本文提出了 SFGS(Structure-aware Fine-grained Gaussian Splatting),一种用于从单目视频重建高逼真、可驱动 3D 重写人体数字分身的方法。该方法基于 3D Gaussian Splatting 框架,通过引入结构感知模块和细粒度手部重建,在保持 30 FPS 实时渲染的同时,显著提升了手部动作和面部表情的精度。
TL;DR
在元宇宙与增强现实(AR)的浪潮下,如何从一段普通的单目视频中提取出一个“栩栩如生”且“可实时驱动”的数字人?今日分享的论文 SFGS (Structure-aware Fine-grained Gaussian Splatting) 给出了目前的优解。它不仅解决了人体运动的连贯性,更通过结构感知(Structure-aware)机制,攻克了数字人重建中“最难啃的骨头”——手部细节与面部表情,并成功在 RTX 4090 上跑出了 30 FPS 的实时性能。
背景定位:从神经辐射场(NeRF)到高斯泼溅(3DGS)
早期的人体重建方法(如 Vid2Avatar, NeuMan)多基于 NeRF。尽管效果尚可,但其极慢的渲染速度(通常 1 FPS 以下)限制了交互可能。3D Gaussian Splatting (3DGS) 的出现改变了游戏规则。然而,现有的 Human-3DGS 方法(如 HUGS, ExAvatar)在处理手部这种非刚性、高自由度的微小部件时,经常出现“手指融合”或“肢体闪烁”的惨状。SFGS 的核心动机便是:如何在 3DGS 框架下,利用人体解剖学结构先验,实现更高精度的骨架绑定与形变。
核心痛点:为什么手部总是“糊”的?
- 拓扑建模不足:SMPL-X 虽然提供了手部参数,但由于全局优化的局限,手部网格往往过于粗糙。
- 时空不一致性:单帧重建容易导致视频播放时产生明显的闪烁(Flicker)。
- 非刚性变形难点:衣服褶皱、肌肉隆起等依赖姿态的变化,难以用简单的线性混合剥离(LBS)表达。
技术深挖:SFGS 的三大必杀技
1. Triplane-Hexplane 联合建模
作者不满足于只建模空间特征,引入了 Hexplane(包含 XY, XZ, XT, YZ, YT, ZT 六个平面)来捕捉时间维度的动态特征。通过一个自适应的 Fusion Module,模型能根据像素点的动态程度,自动调节静态 Triplane 和动态 Hexplane 的权重,大幅缓解了快速运动下的画面抖动。
2. 结构感知偏移预测 (Structure-Aware Offset)
这是本文的灵魂。SFGS 为每个 Gaussian 点分配一个“主导关节”(Dominant Joint)。在预测 Gaussian 的位置和缩放偏移时,不仅参考空间特征,还输入了该关节的 6D 旋转和位置向量。这种局部坐标系敏感的设计,让模型能理解物体的动作意图,从而产生更精准的皮肤拉伸和颜色变化(如握拳时皮肤颜色的改变)。
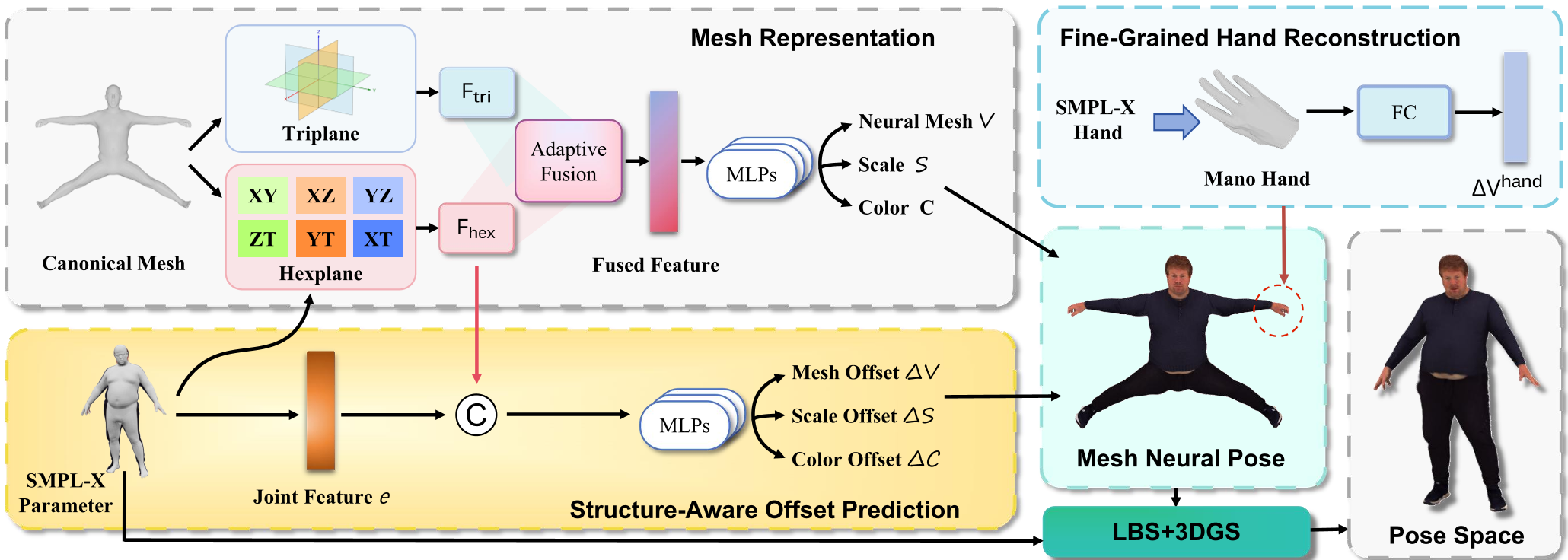 图 1:SFGS 的核心 pipeline,展示了从 SMPL-X 采样到 Hexplane 特征融合,再到结构感知预测的全过程。
图 1:SFGS 的核心 pipeline,展示了从 SMPL-X 采样到 Hexplane 特征融合,再到结构感知预测的全过程。
3. 基于 MANO 的残差修正
针对手部,SFGS 引入了专门用于手部建模的 MANO 模板。通过计算 MANO 模型与 SMPL-X 之间的几何残差(Residual),并用一个小型的 MLP 根据当前手势动态修正这些残差,从而补偿了原有参数模型在精度上的先天不足。
实验战果:更准、更快、更自然
在与 SOTA 方法 ExAvatar 的对比中,SFGS 展现了压倒性的细节优势。从定性结果看,SFGS 渲染出的手指根根分明,且具有正确的阴影投射;从定量数据看,PSNR 在 Bike 等复杂序列上提升了近 6dB。
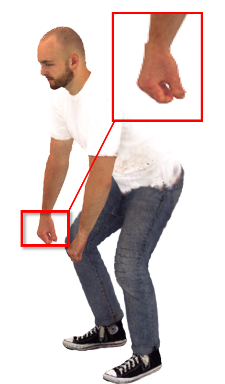 图 2:在 X-Humans 数据集上的对比,SFGS 在手部阴影和边缘清晰度上明显优于基线。
图 2:在 X-Humans 数据集上的对比,SFGS 在手部阴影和边缘清晰度上明显优于基线。
更令人惊喜的是其效率。表 7 显示,SFGS 是目前为数不多能突破 30 FPS 大关的高精度人体重建方案,这意味着将其部署在 VR 环境中进行实时驱动已成为可能。
总结与洞察:走向通用数字人
SFGS 证明了 “结构化先验 + 显式点云渲染” 是当前动态数字人方案的黄金搭档。它不仅解决了局部细节丢失的问题,还通过 Hexplane 平衡了流畅度。
局限性:尽管 SFGS 在紧身服装上表现卓越,但对于极其肥大的衣物(如长裙、斗篷),由于初始采样点的密度受限于人体表皮网格,可能会出现局部模糊。未来的研究可能会引入动态点云增殖技术,以应对这些非人体的外部几何形态。
正如作者在结论中所述,SFGS 为从单目视频构建可交互、高真实感的数字分身铺平了道路,或许很快,我们只需要用手机自拍一段视频,就能生成一个精细到指尖的元宇宙化身。