SIRA:重塑检索智能体——从“盲目试错”到“单次击穿”
Superintelligent Retrieval Agent: The Next Frontier of Information Retrieval
本文提出了 SIRA (SuperIntelligent Retrieval Agent),一种由 LLM 驱动的超智能检索智能体。SIRA 摒弃了传统的多轮迭代检索模式,通过“单次专家级检索行动”实现了对现有密集检索器(Dense Retrievers)和多轮 RL 搜索智能体的全面超越。
TL;DR
在 RAG (检索增强生成) 领域,我们习惯了智能体在搜索框里反复横跳:搜一次、看一眼、改个词、再搜一次。Meta 和莱斯大学的研究团队最近推出的 SIRA (SuperIntelligent Retrieval Agent) 告诉我们:真正的“超智能”检索不需要多轮对话。通过结合 LLM 的先验知识与经典的 BM25 统计特性,SIRA 实现了单次检索即可吊打 SOTA 密集检索器和强化学习训练的多轮搜索智能体。
痛点深挖:为什么你的 AI 搜索像个“菜鸟”?
现状是,即便拥有最强的推理模型,AI 在处理检索任务时仍面临两大困境:
- 黑盒焦虑:现在的嵌入式(Dense Embedding)检索是个黑盒,智能体只能拿到一堆余弦相似度分数,却无法精确控制“必须包含某词”或“排除某概念”。
- 新手行为模式:现有的 Agent(如 ReAct 模式)通过反思和重写查询来补偿检索器的无力。这种“检索-上下文优势(Retrieval-context Advantage)”极其昂贵且效率低下,本质是因为智能体不了解它所检索的语料库特征。
作者指出:检索不是简单的语义匹配,而是一个对比排序问题。你不仅要找相关的,还要找那些能把“正确答案”从“迷惑项”中分离出来的特征词。
核心方法:像专家一样“编程”检索式
SIRA 放弃了把检索当工具用的思路,转而让 LLM 充当检索引擎的“首席架构师”。其核心包含两个维度:
1. 词汇增强(Vocabulary Enrichment)
- 离线侧:LLM 预先预判:用户会用什么词来搜这个文档?它会把文档本身没写但在搜索时高频出现的关键词(如同义词、缩写)注入索引。
- 在线侧:当用户提出问题,SIRA 不直接搜,而是先画一个“预期响应草图(Expected-Response Sketch)”,预测正确答案周围应该出现哪些专业术语。
2. 语料库统计过滤(DF Filter)
这是 SIRA 的灵魂所在。LLM 提出的词虽然专业,但可能在库里根本没有,或者太常见了(IDF 权重低)。SIRA 会调用轻量级工具检查每个词的文档频率 (Document Frequency)。
- 太常见的词?删掉。
- 索引里没出现的词?删掉。
- 剩下的“黄金词汇”?加大权重,合成一个复杂的 加权 BM25 查询式。
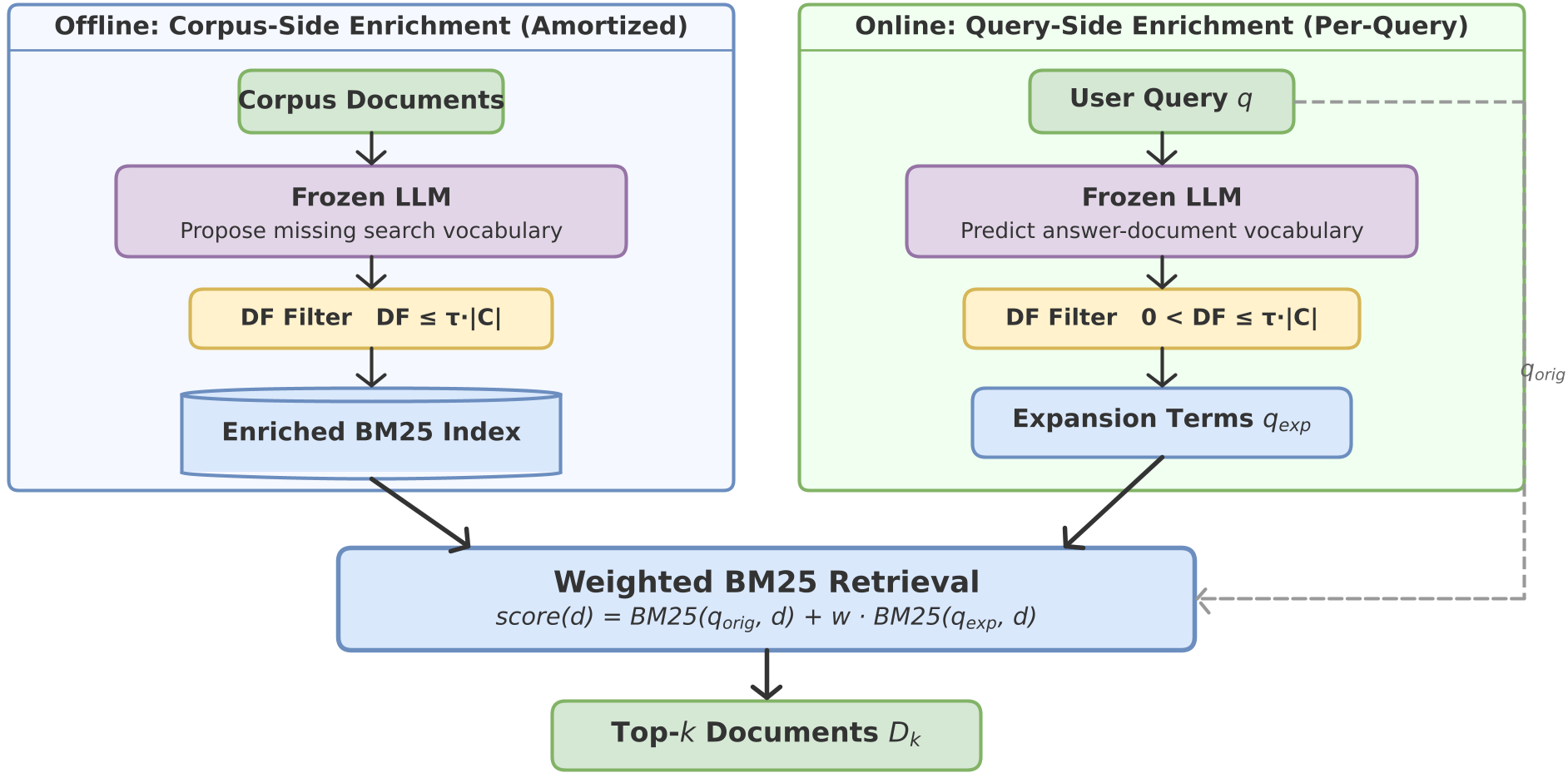 图 1:SIRA 通过离线和在线双向增强,利用索引统计数据实现精准制导。
图 1:SIRA 通过离线和在线双向增强,利用索引统计数据实现精准制导。
实验战绩:老树开新花,传统词法检索的逆袭
在涵盖 10 个数据集的 BEIR 基准测试 中,SIRA 展现了恐怖的统治力。
| 模型 | Recall@10 (Avg) | NDCG@10 (Avg) | | :--- | :--- | :--- | | BM25 (基线) | 0.530 | 0.424 | | E5 (强力神经检索) | 0.648 | 0.543 | | SIRA (本文方法) | 0.691 | 0.572 |
最令人惊讶的是在下游 QA 任务上。即使不使用任何强化学习(RL)训练,SIRA 的单轮检索覆盖率(NQ: 84.7%)直接超越了那些在 QA 目标上反复摩擦训练的多轮搜索智能体(如 Search-R1)。这说明:与其教 Agent 怎么折腾搜索引擎,不如给它一个能精准操控的引擎。
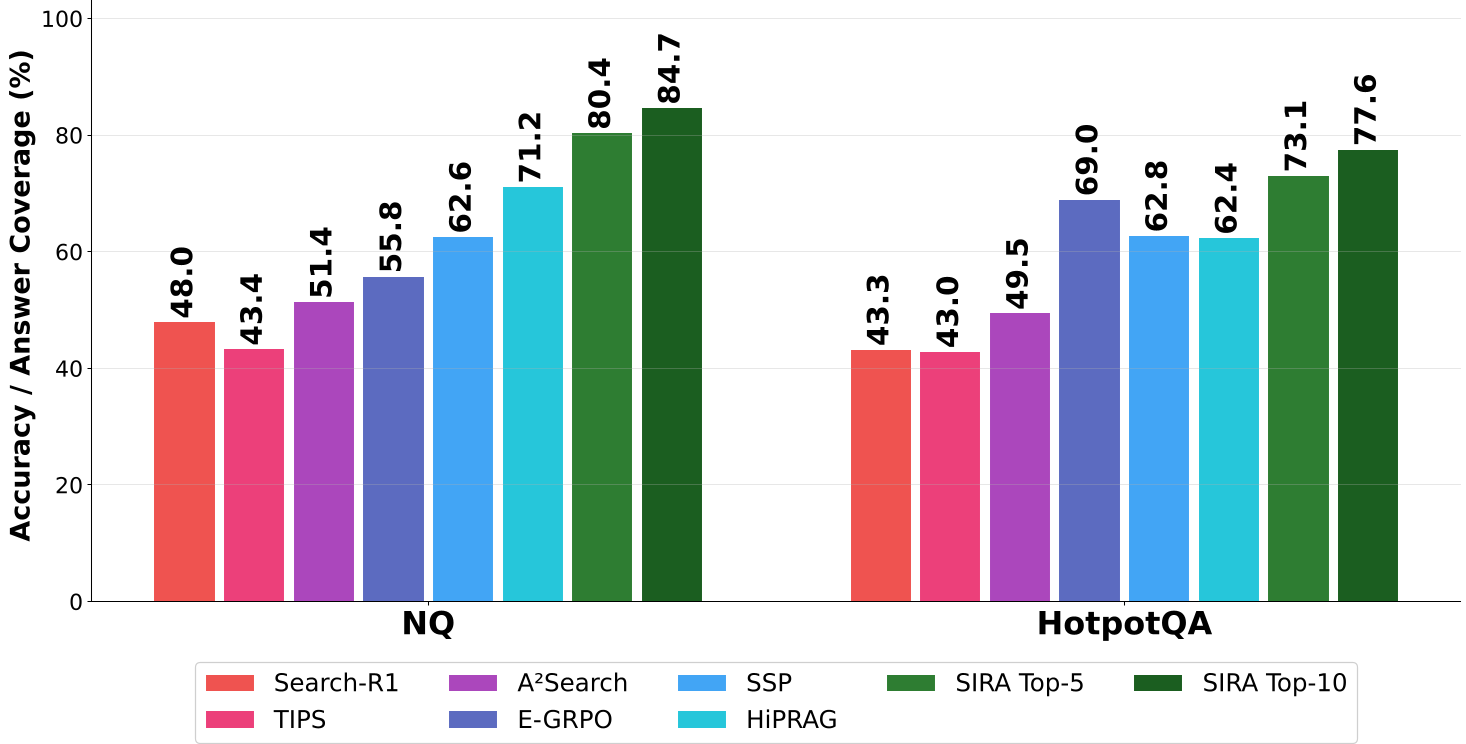 图 2:SIRA 与各类 RL 训练的搜索代理在 NQ 和 HotpotQA 上的性能对比。
图 2:SIRA 与各类 RL 训练的搜索代理在 NQ 和 HotpotQA 上的性能对比。
深度洞察:回归第一性原理
SIRA 的成功反映了 IR 领域的一个趋势回归:可解释性与控制力。 神经网络虽然能理解上下文,但在“判别性(Discriminative)”上往往不如精准的统计词频。SIRA 证明了:当 LLM 提供认知先验,传统倒排索引提供统计底盘,两者结合后产生的“单次快准狠”检索,比笨拙的多轮迭代更有竞争力。
局限性观感: 目前的 SIRA 依赖于 LLM 强大的参数化知识。如果我们要检索一个全新的、极其冷门的领域(比如某个企业内部刚生成的秘辛文档),LLM 可能无法给出有效的“预期响应草图”。这种情况下,如何进行动态的领域适应(In-domain Adaptation)将是未来的攻坚点。
总结
SIRA 为我们展示了“超智能检索”的未来:不是更复杂的神经架构,而是更聪明的索引感知与控制策略。它让 BM25 这个老兵在 AI 时代依然能作为最锋利的战刃,在 RAG 战场上大杀四方。