本文提出了 SUPERNOVA,一个专为强化学习与可验证奖励(RLVR)设计的通用推理数据策展框架。通过利用现有的指令微调数据集(如 SuperNI),该框架能够有效提取并重构海量高质量的通用推理任务,使小型模型(如 Qwen3-4B)在 BBEH 等通用推理基准上超越了 2 倍规模的基线模型,刷新了非科学(Non-STEM)领域的推理性能 SOTA。
TL;DR
在 DeepSeek-R1 开启的“后规模时代”,RL(强化学习)已成为提升模型推理能力的标配。然而,业界一直面临一个尴尬现状:模型在 MATH 和代码上刷分飞起,遇到逻辑悖论或因果分析却表现平平。本文提出的 SUPERNOVA 框架通过对 SuperNI 等人类标注指令集的“点金之术”,成功将 RLVR(带可验证奖励的强化学习)引入通用推理领域。结果惊人:一个 4B 的模型在通用推理任务上竟能吊打 8B 甚至更大参数量的模型。
背景定位:通用推理的“缺失环节”
当前的推理模型正陷入“STEM 局部优化的陷阱”。虽然 AIME、CodeForces 成绩显著,但在 BBEH (Big-Bench Extra Hard) 这类评估因果、空间、时间理解的基准上,很多号称“Thinker”的模型反而退步了。
作者指出:通用推理能力的匮乏,本质上是因为缺乏高质量、可验证的非 STEM 训练数据。互联网抓取的数据就像“垃圾食品”,噪声大且难以自动判分。
核心动机:指令数据的“二次开发”
作者产生了一个天才的直觉(Insight):人类过去几年辛苦积累的 Instruction-tuning 数据库(如 SuperNI、FLAN)中其实蕴含了极丰富的推理模式,只是因为它们大多是开放式问答,无法直接喂给 RL 算法。如果能把这些数据“重构”为可验证格式,不就拥有了一座推理金矿?
方法论:SUPERNOVA 的三阶火箭
SUPERNOVA 并不是简单地堆砌数据,它包含了一套严谨的策展策略:
1. 任务重构与选择 (Task Selection)
并不是所有指令任务都能触发推理。作者测试了 83 个候选任务,发现效果千差万别。
- 高价值任务:多步推理(Multi-hop)、指代消歧。
- 负贡献任务:叙事相干性、单纯的日期格式转换。

2. 微观混合策略 (Micro Mixing)——最关键的创新
传统的做法是计算所有任务的平均分,选前 N 名(Macro Mixing)。SUPERNOVA 提出了 Micro Mixing:
- 将 BBEH 拆解为 23 个子任务(如:几何、逻辑、社交)。
- 针对每个子任务,挑选最能提升该能力的 Top-K 个练习题集。
- 取并集。 结果:Micro Mixing 的性能一致性地优于 Macro Mixing,因为它保证了模型推理技能的“营养均衡”。
3. 反直觉的发现:合成干预(Data Intervention)
作者尝试通过注入长上下文、人为制造逻辑陷阱来增加数据难度。但实验表明,这些合成干扰在固定算力预算下反而降低了模型表现。这给盲目崇拜“复杂合成数据”的研究者们敲响了警钟:真实的、高质量的人工标注结构依然是不可替代的。
实验战绩:小钢炮的胜利
在 BBEH 这种“硬骨头”基准测试中,SUPERNOVA 展现了极强的统治力。
| 模型 | 参数量 | BBEH-test (pass@8) | 相比基线提升 | | :--- | :--- | :--- | :--- | | Qwen3-0.6B | 0.6B | 15.2% | - | | SUPERNOVA-0.6B | 0.6B | 25.0% | +64.5% | | Qwen3-4B | 4B | 23.2% | - | | SUPERNOVA-4B | 4B | 33.3% | +43.5% | | Qwen3-8B | 8B | 24.2% | (反被 4B 超越) |
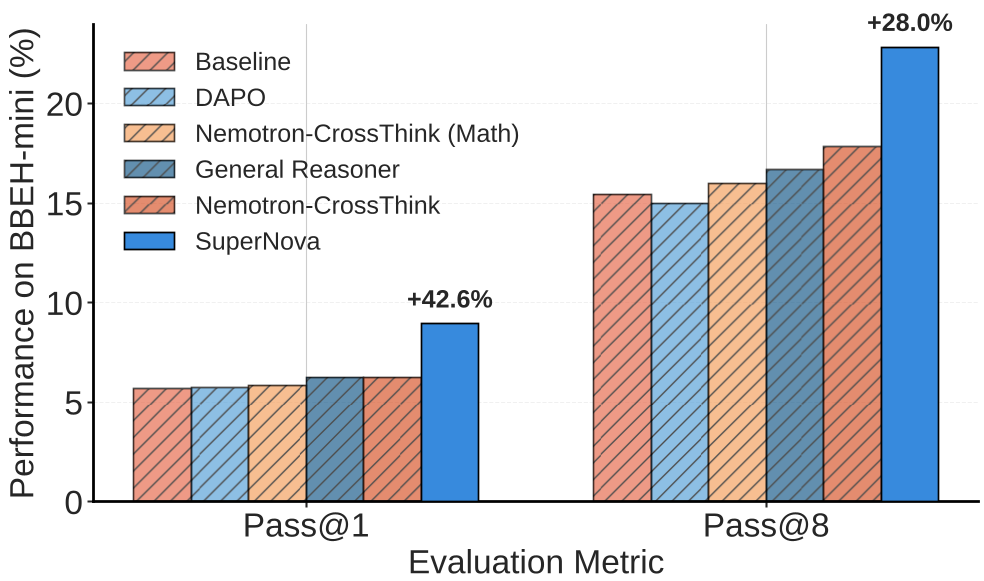
从上图可以看出,SUPERNOVA 的策展方案在不同领域(Math, BBH, Zebralogic)都实现了稳健增长。特别是在 Zebralogic(斑马逻辑难题) 上,SUPERNOVA-4B 的表现(77.0%)几乎两倍于原始模型(55.6%)。
深度洞察与总结
为什么 SUPERNOVA 有效?
- 精准打击:通过 Micro Mixing,模型被针对性地训练了处理特定逻辑结构的能力。
- 可验证性:将指令任务 MCQ 化,解决了通用推理中 Reward 信号模糊的问题。
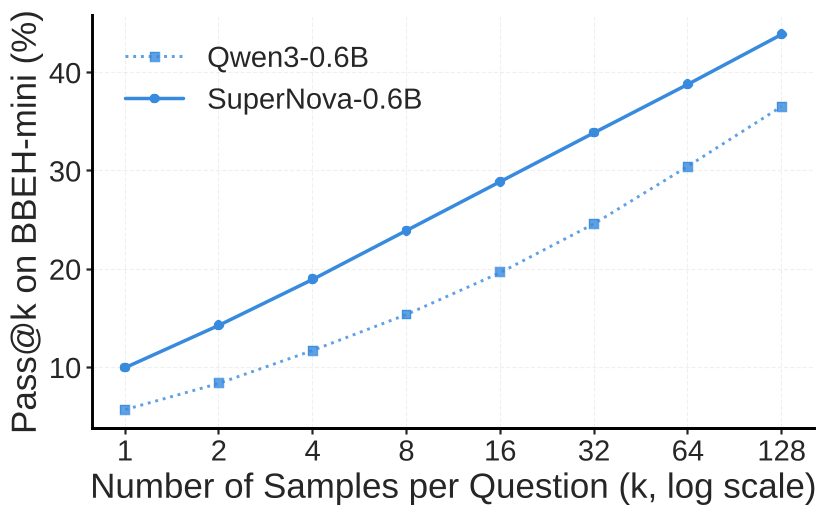
- 探索空间:如下图所示,随着 值的增大(从 pass@1 到 pass@128),SUPERNOVA 的领先幅度在扩大,说明它确实激发了模型在推理过程中的探索广度,而不仅仅是记住了答案。
局限性与展望
尽管 SUPERNOVA 在学术 Benchmarks 上表现优异,但其依赖的 SuperNI 任务类型仍有上限。未来如果能将该框架应用到更复杂的、非公开的工业级数据源上,人类或许能训练出在商业决策、法律咨询等复杂场景下具备真正“General Reasoner”素质的轻量化模型。
结论:想让 AI 变聪明,光刷数学题是不够的,得学会分类策展和精准 RL。