The SwanNLP paper introduces a multi-tier LLM framework for rating word sense plausibility in narrative contexts for SemEval-2026 Task 5. It combines Supervised Fine-Tuning (SFT) of low-parameter models with dynamic few-shot RAG for large-scale LLMs, achieving 10th place globally with an average score of 0.760.
TL;DR
The SwanNLP framework addresses the challenge of Narrative Word Sense Disambiguation (WSD) by moving beyond binary "correct/incorrect" labels to human-like plausibility scoring (1-5). By combining fine-tuned 4B models (Qwen/Gemma) with a dynamic few-shot GPT-4o system and meta-learning ensembles (XGBoost), the team successfully mimicked the variance and reasoning of human annotators in the AmbiStory dataset.
Problem: The Limits of Sentence-Level WSD
Most WSD benchmarks operate in "silos"—isolated sentences where the context is thin. In real-world storytelling, a word's sense is often ambiguous and dependent on the "pre-context" or the "ending" of a narrative.
The SemEval-2026 Task 5 highlights a critical pain point: LLMs are great at identifying common senses but struggle with "human-ambiguous" scenarios where a sense is partially plausible. Standard models often fail to capture the subtle gradations (e.g., why a sense is a '3' rather than a '5').
Methodology: A Three-Tiered Reasoning Approach
The researchers didn't just throw a larger model at the problem. Instead, they built a pipeline that respects different levels of reasoning complexity.
1. Difficulty-Aware Fine-Tuning
For low-parameter models (4B range), the authors found that simply predicting a score wasn't enough. They introduced Difficulty Analysis. As shown in the workflow below, they categorized data into "Easy" (High/Low scores) and "Ambiguous" (High variance in human scores) to teach the model when to be uncertain.
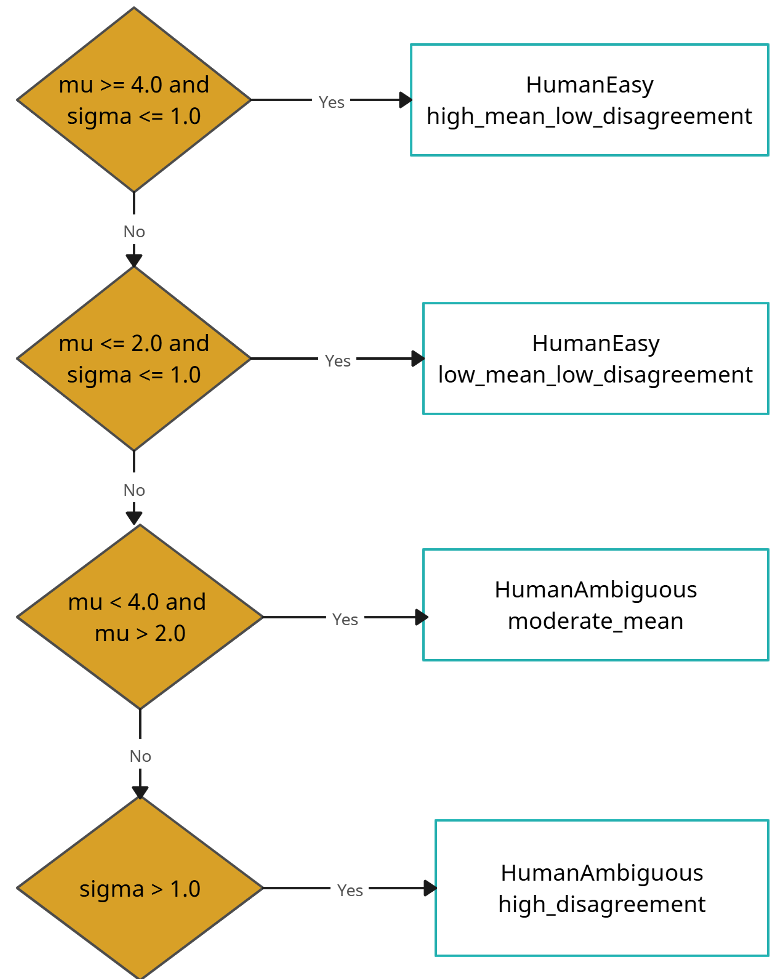 Figure 1: The logic used to classify whether a case is easy or difficult based on annotator agreement.
Figure 1: The logic used to classify whether a case is easy or difficult based on annotator agreement.
2. Dynamic Few-Shot RAG
For commercial models like GPT-4o, they used a Dynamic RAG approach. Instead of static examples, the system retrieves stories from a vector store (FAISS) that share similar ambiguity profiles with the query. This "in-context learning" helps the model calibrate its 1-5 scale based on relevant precedents.
3. Simulating the "Five-Annotator" Consensus
Recognizing that human judgment is rarely a monolith, they treated different models as independent annotators. They tested several ensembling strategies, including Linear Regression Ensembles (LRE) and XGBoost, to weigh the predictions and minimize individual model bias.
Key Results: Qwen's Leap and GPT-4o's Dominance
The experiments revealed a massive gap between "base" models and "reasoning-aware" models:
- Small Model Gains: Fine-tuning Qwen-4B with difficulty analysis improved Spearman correlation from a near-random 0.031 to a robust 0.491.
- Large Model Prowess: GPT-4o remained the SOTA baseline for plausibility, particularly when aided by dynamic examples.
- Ensemble Success: The Linear Regression Ensemble achieved the highest test accuracy (0.797), proving that a "committee of models" better approximates the average human score than any single model.
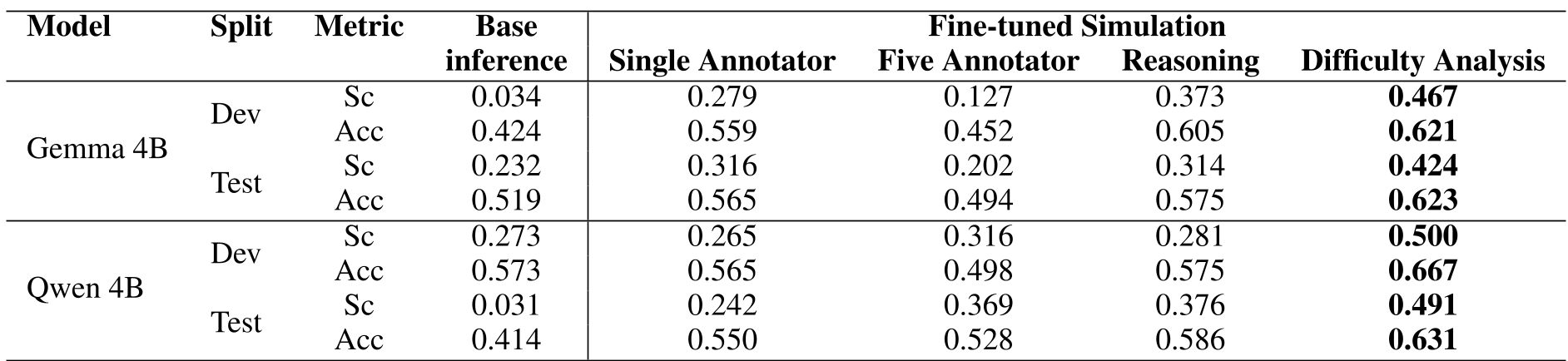 Table: Performance comparison showing the drastic improvement from 'Base Inference' to 'Difficulty Analysis' fine-tuning.
Table: Performance comparison showing the drastic improvement from 'Base Inference' to 'Difficulty Analysis' fine-tuning.
Critical Insight & Conclusion
The core takeaway is that subjective NLP tasks require structural reasoning. When LLMs are prompted to think about "evidence for" and "evidence against" a sense BEFORE scoring (as seen in the Appendix A prompt), they align much closer to human logic.
However, a lingering limitation exists: even the best models struggle when the context is inherently uncertain. Future research must look into Probabilistic WSD, where models output a distribution of plausibility rather than a single scalar, better reflecting the diversity of human interpretation.
Final Achievement: 10th Place (SemEval-2026 Task 5 Leaderboard).