Symphony is a cognitively-inspired multi-agent system (MAS) designed for long-form video understanding (LVU). It achieves state-of-the-art results on benchmarks like LVBench (71.8%) and VideoMME (78.1%) by decomposing reasoning into specialized functional agents and employing a reflection-enhanced dynamic collaboration mechanism.
TL;DR
Symphony is a new multi-agent framework that solves the "lost in the context" problem for long videos. By splitting the work among specialized agents (Planning, Grounding, Subtitle, and Perception) and adding a secondary "Reflection" agent to double-check the logic, it has set new records across major benchmarks including LVBench and VideoMME.
The Bottleneck: Why Long Videos Break AI
As video length grows, two things happen: the information density skyrockets, and the reasoning chain required to answer a question becomes perilously long. Current MLLMs (Multimodal Large Language Models) suffer from a "reasoning capacity limit"—once a task gets too complex, they default to simplistic, often incorrect answers. Furthermore, standard retrieval methods (like CLIP) are "blind" to intent; they find segments that look like the query but miss segments that are logically relevant but visually different.
Methodology: The Cognition-Inspired Architecture
Symphony moves away from the traditional approach of "one model does it all." Instead, it mimics human cognitive dimensions:
- Planning Agent (Reasoning/Decision): The conductor of the MAS, orchestrating other agents and accumulating evidence.
- Grounding Agent (Attention): Instead of simple keyword matching, it uses an LLM to "think" about what the question actually means, then uses a VLM to score video segments based on relevance.
- Visual Perception & Subtitle Agents: Specialized modules that handle fine-grained visual details and semantic text analysis respectively.
- Reflection Agent (The Critic): Acting as a "Verifier," this agent reviews the entire reasoning path. If it finds a gap in logic, it sends the Planning agent back to the drawing board with a specific critique.
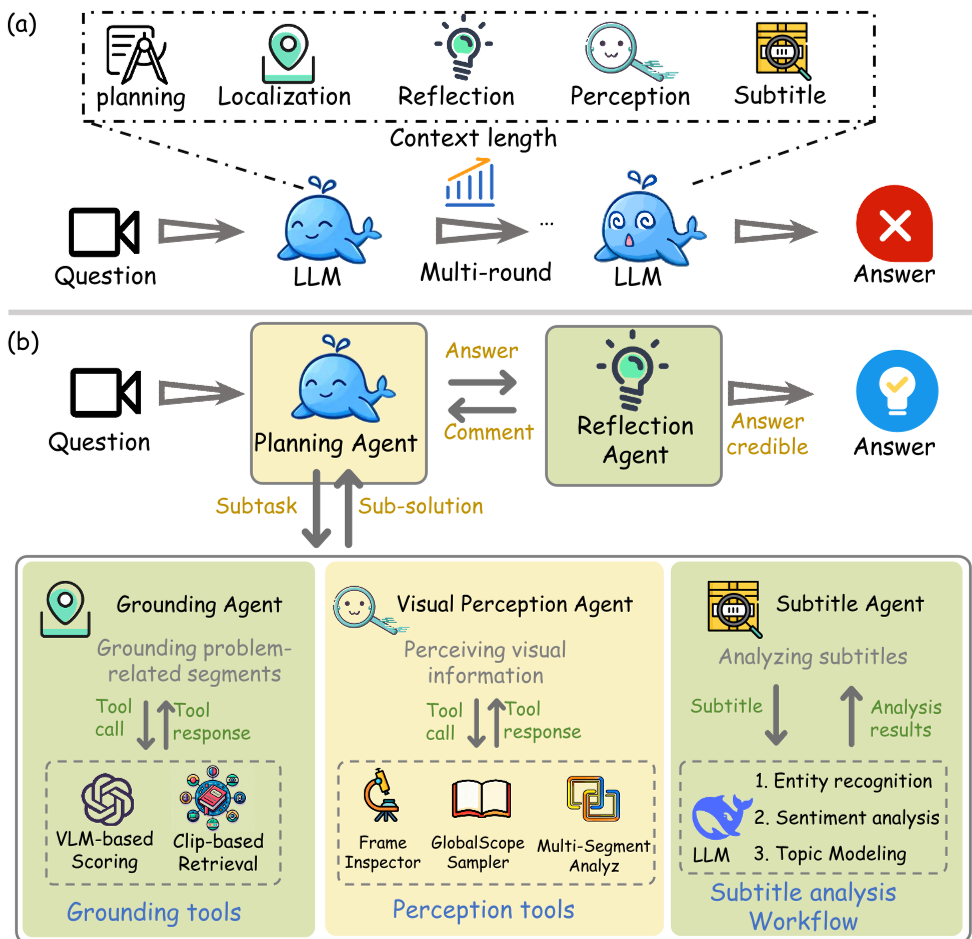 Figure 1: Symphony's functional decomposition vs. traditional single-agent approaches.
Figure 1: Symphony's functional decomposition vs. traditional single-agent approaches.
The Secret Sauce: Reflection-Enhanced Collaboration
Inspired by the Actor-Critic framework, Symphony doesn't just output an answer in one go. The Reflection Agent evaluates the reasoning trajectory (). If the evidence is insufficient, it generates a critique () and forces a new round of exploration. This allows the system to correct its own "hallucinations" before they become final answers.
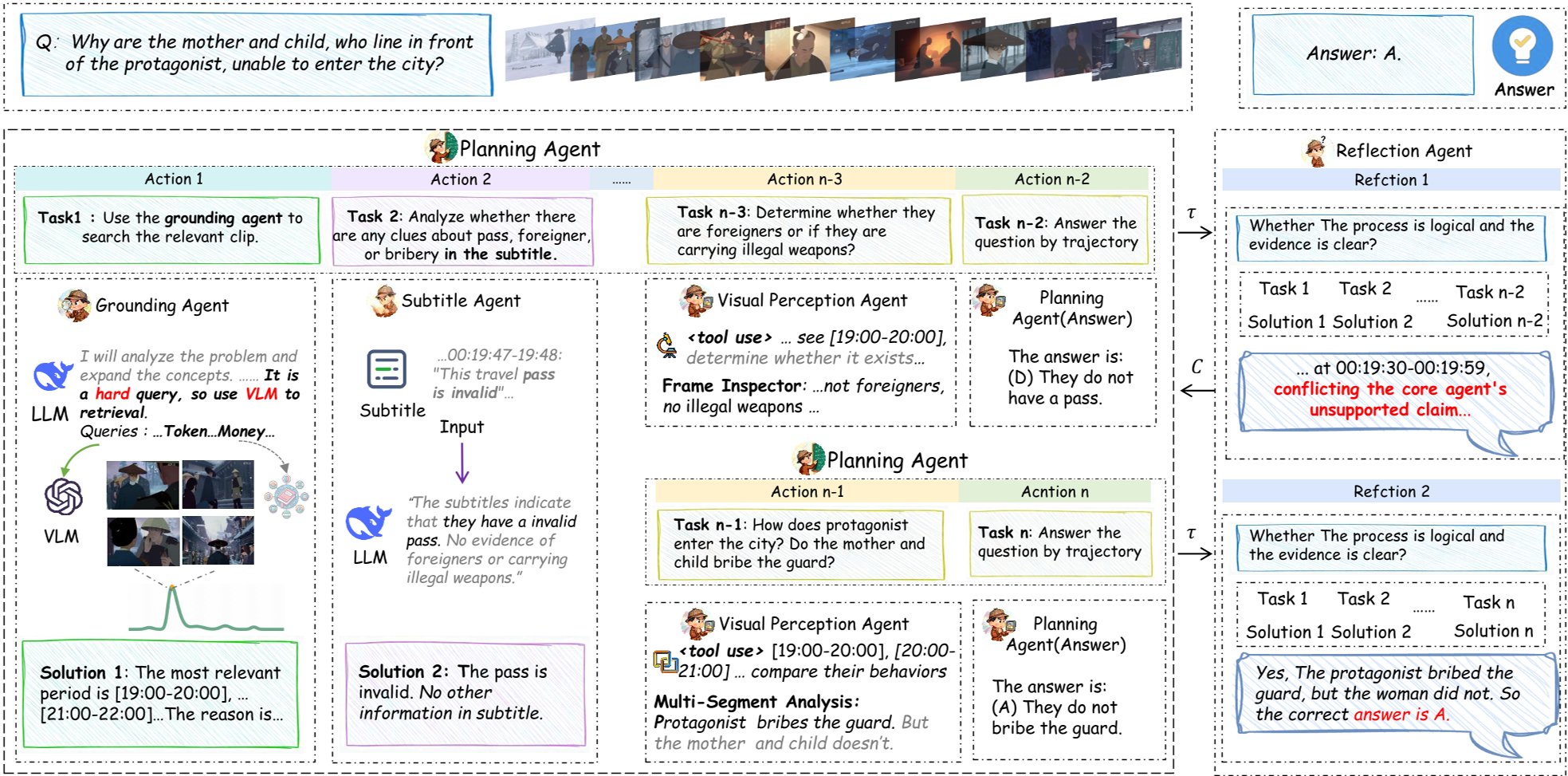 Figure 2: The iterative reasoning loop between the Planning and Reflection agents.
Figure 2: The iterative reasoning loop between the Planning and Reflection agents.
Experiments & Results
Symphony was tested against industry giants like GPT-4o and Gemini-1.5-Pro. It didn't just compete; it dominated.
- LVBench: Achieved 71.8%, surpassing the previous SOTA (DVD) by 5.0%.
- MLVU: Reached 81.0%, showing exceptional performance in multi-task scenarios.
- Ablation Success: Removing the Reflection Agent caused a 2.5% drop in performance, proving that "thinking about thinking" is a measurable advantage.
 Table 1: Symphony vs. SOTA Models across multiple benchmarks.
Table 1: Symphony vs. SOTA Models across multiple benchmarks.
Deep Insight: Beyond Feature Extraction
The genius of Symphony lies in its Grounding Agent. By using an LLM to expand a query before searching, it can find segments that a standard CLIP search would miss. For example, if asked about a "tense moment," the LLM expands this into visual cues like "rapid breathing," "sweat," or "shaky camera," which the VLM then identifies with high precision.
Conclusion & Future Outlook
Symphony proves that the future of Long-Video Understanding isn't just "bigger models" but "smarter systems." By decoupling cognitive functions and introducing a verification layer, it bridges the gap between raw perception and deep logical reasoning.
Limitations: While powerful, the multi-round reasoning adds latency compared to single-pass models. Future work may focus on optimizing the number of iterations or using smaller, specialized models for the reflection step to reduce costs further.
Takeaway: If you are building for complex LVU, stop trying to fix the model's context window and start building a cognitive symphony of agents.