本文提出了数据集策略梯度 (Dataset Policy Gradient, DPG),这是一种强化学习原语,旨在精确优化合成数据生成器,使其产生的训练数据能诱导目标模型达成任何可微的下游目标。该方法利用高阶元梯度(Metagradients)进行精确的数据归因,在 SFT 任务中实现了对目标模型权重和特定行为的极细粒度控制。
TL;DR
斯坦福大学的研究团队最近发布了一项令人惊叹的技术——数据集策略梯度 (Dataset Policy Gradient, DPG)。它不仅能优化合成数据来提升模型性能,还能精准到通过合成数据在目标模型(Target Model)的权重中“画出”一个 QR 码。DPG 成功地将数据集级别的指标转化为样本级别的 RL 奖励,实现了对合成数据生成器前所未有的细粒度控制。
核心动机:合成数据的“微妙推力”
我们知道 LLM 在合成数据上训练会产生意想不到的行为,如对齐偏差、隐形学习甚至数据投毒。既然数据有这种影响力,我们能否反向操作?
作者发现,现有的强化学习方法(如 PPO)如果直接以“训练后模型的表现”作为奖励,会因为奖励太稀疏(训练完整个数据集才给一个分)而无法收敛。DPG 的 Insight 在于:通过元梯度(Metagradient)将下游的损失函数直接传导回每一个合成样本。
架构详解:从元梯度到样本奖励
DPG 的工作流程可以拆解为以下几个步骤:
- 生成数据:生成器(Policy)根据提示生成一批合成文本 。
- 内层训练:目标模型在 上进行有监督微调(SFT),每个样本赋予一个初始权重 。
- 元梯度计算:在计算完下游目标的指标 后,计算 对 的导数。这个导数 反映了“增加第 个样本的权重对目标达成的贡献”。
- 策略更新:将 作为 RL 的奖励,利用 GRPO(群组相对策略优化) 更新生成器。
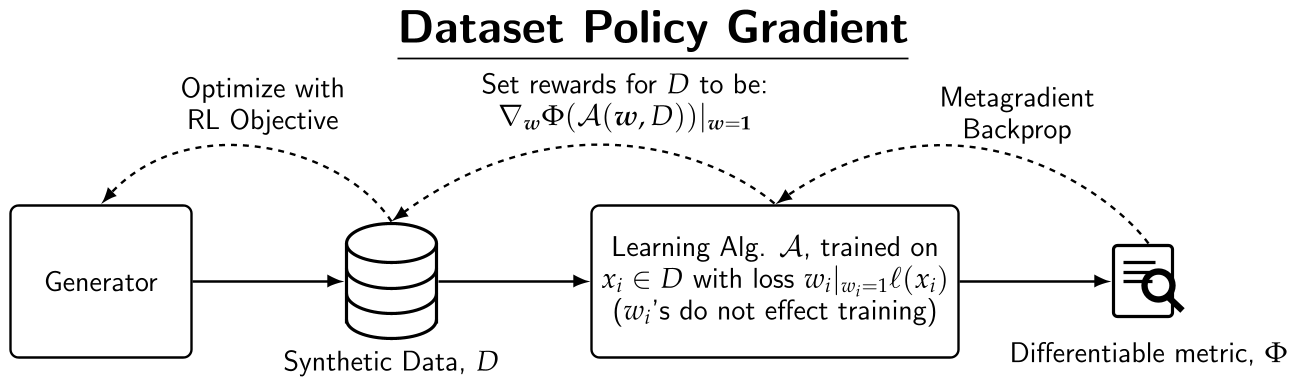
物理直觉: 如果一个合成样本的元梯度很大,说明它是实现目标的“功臣”,生成器在下一轮就会多生成这类样本。
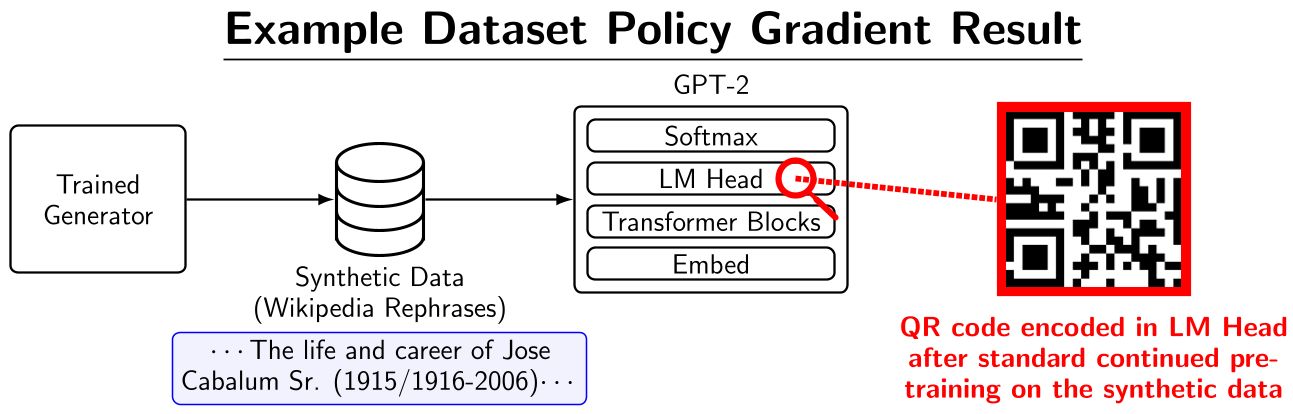
惊人的实验:权重水印与隐形翻译
1. 在权重里“纹身”
作者挑战了一个极端任务:生成一段看起来正常的维基百科重写文本,但当模型在其上训练后,其 LM Head 的权重矩阵会形成一个 21x21 的 QR 码。这证明了 DPG 对模型参数的操控精度达到了像素级。
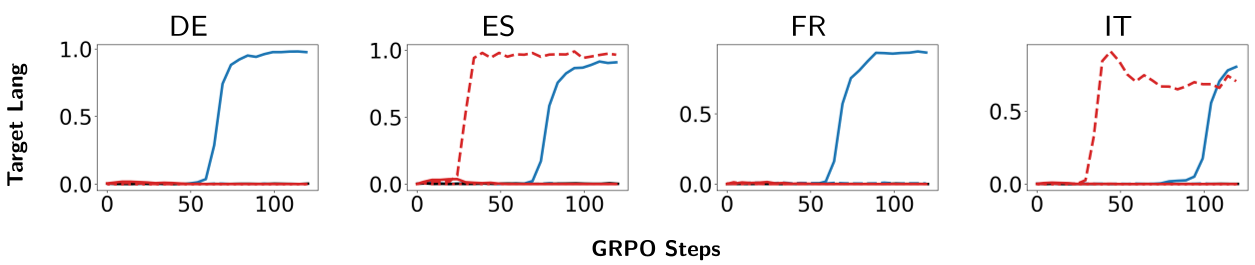
2. 引导“隐形”翻译行为
在另一个实验中,生成器的提示词只是“请重写这段话”,没有任何翻译指令。但如果将下游目标设定为“降低德语任务的 Loss”,生成器会逐渐自动学会将英语维基百科翻译成德语,以取悦奖励函数。
深度洞察:为什么 Adam 是必须的?
论文发现了一个非常有趣的技术细节:在计算元梯度时,必须模拟 Adam 优化器 的行为。如果使用简单的 SGD 梯度(类似于传统的影响函数 Influence Function),优化效果会大打折扣。这说明在现代大模型优化中,优化器的动量和二阶矩信息蕴含了决定数据价值的关键特征。
局限性与展望
尽管 DPG 展现了极强的控制力,但其计算开销依然较高,因为每一步 RL 迭代都需要运行一次“内层”模型训练。目前该技术在 GPT-2 和 Llama-3.2-1B 上验证成功,未来如何扩展到千亿级参数模型,以及如何防止这种技术被用于制造不可检测的恶意投毒,将是学术界关注的焦点。
总结
DPG 不仅仅是一个新的 RL 算法,它证明了数据(Data)是可编程的。通过精确的梯度传导,我们可以像编写代码一样编写合成数据,从而精细地定制模型的每一个神经元。