The paper introduces Token- and Turn-level Policy Optimization (T2PO), a framework for stabilizing multi-turn reinforcement learning in LLM agents. By explicitly controlling exploration through a self-calibrated uncertainty signal, T2PO achieves state-of-the-art results on WebShop, ALFWorld, and Search QA benchmarks.
TL;DR
Training LLM agents to solve multi-step tasks (like online shopping or embodied navigation) via Reinforcement Learning (RL) is notoriously unstable. This paper identifies "Hesitation"—the generation of redundant tokens and repetitive, unproductive turns—as the primary driver of training collapse. The authors propose T2PO, which uses intrinsic uncertainty signals to adaptively truncate over-thinking at the token level and resample redundant moves at the turn level, leading to unprecedented stability and efficiency.
The "Hesitation" Problem: Why Agents Fail
In the world of multi-turn RL, traditional stabilization focuses on better reward functions or trajectory filtering. However, T2PO’s authors argue the problem is more fundamental: Inefficient Exploration.
They find that LLMs often enter two types of "Hesitation" loops:
- Token-level over-thinking: The model generates an "aha moment" and makes a decision, but then continues to ramble, adding noise to the credit assignment.
- Turn-level repetition: The agent gets stuck in a loop (e.g., searching for the same item twice without finding it) because its internal state hasn't meaningfully shifted.
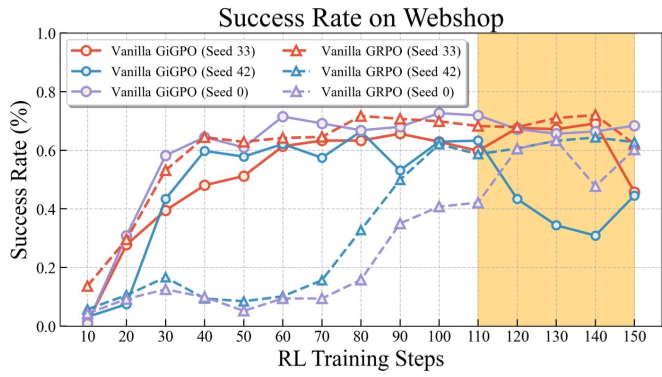 Figure 1: SOTA baselines frequently suffer from gradient explosions and performance collapse due to these inefficiencies.
Figure 1: SOTA baselines frequently suffer from gradient explosions and performance collapse due to these inefficiencies.
Methodology: Hierarchical Exploration Control
1. The Self-Calibrated Uncertainty Signal
T2PO doesn't just use Entropy (too smooth) or Confidence (too localized). It fuses them into a combined signal .
- Entropy () captures the overall distribution spread.
- Confidence () captures the peak probability. The resulting creates a non-degenerate geometry that distinguishes between meaningful reasoning and "rambling."
2. Token-Level Thinking Intervention (TTI)
Instead of a hard budget, TTI monitors the velocity of uncertainty. When the marginal change in uncertainty falls below a threshold (), the system triggers an intervention. It forcibly injects a </think> tag and resumes with the structured <action> phase.
3. Turn-Level Dynamical Sampling (TDS)
If the average uncertainty of a turn is too similar to the previous turn, the agent is likely "stuck." T2PO identifies these low-information turns and forces a dynamic resample (regeneration), ensuring that every rollout sent to the optimizer is informative.
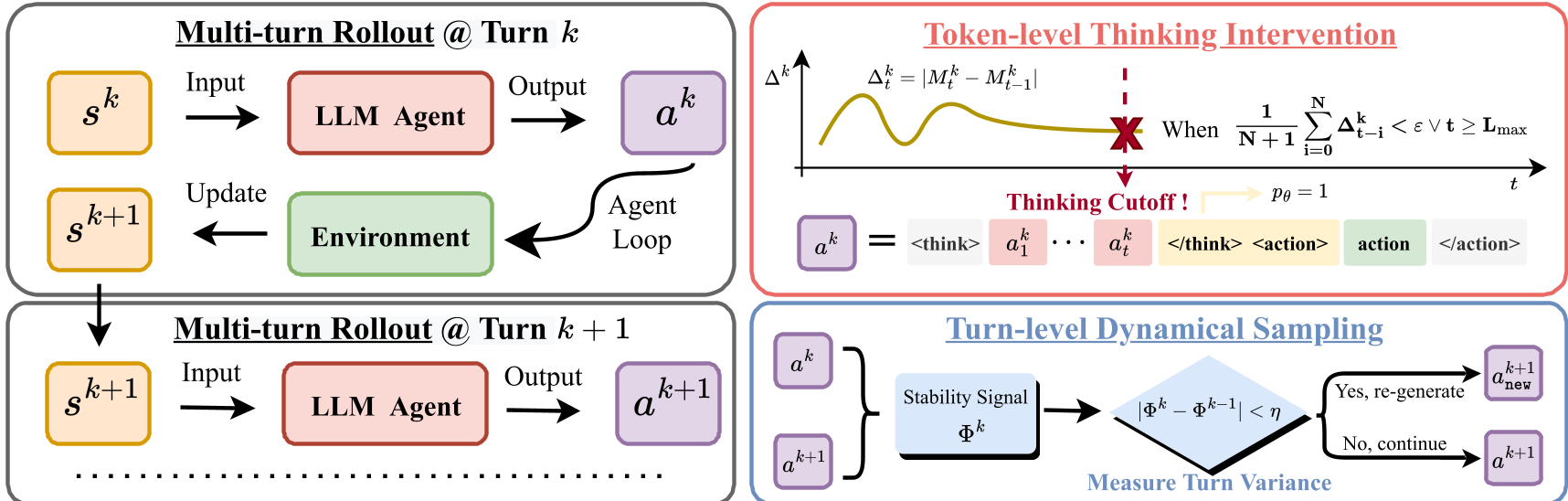 Figure 2: Overview of the hierarchical control at both token and turn levels.
Figure 2: Overview of the hierarchical control at both token and turn levels.
Experiments: SOTA Achievement
The authors tested T2PO on WebShop, ALFWorld, and Search QA. The results were striking:
- Performance: On ALFWorld, T2PO scored 92.4% success, roughly 10 points higher than the previous SOTA (GiGPO).
- Efficiency: It completed tasks with 25% fewer turns and significantly fewer tokens.
- Stability: Unlike baselines that collapsed after a few hundred steps, T2PO showed monotonic improvement across multiple random seeds.
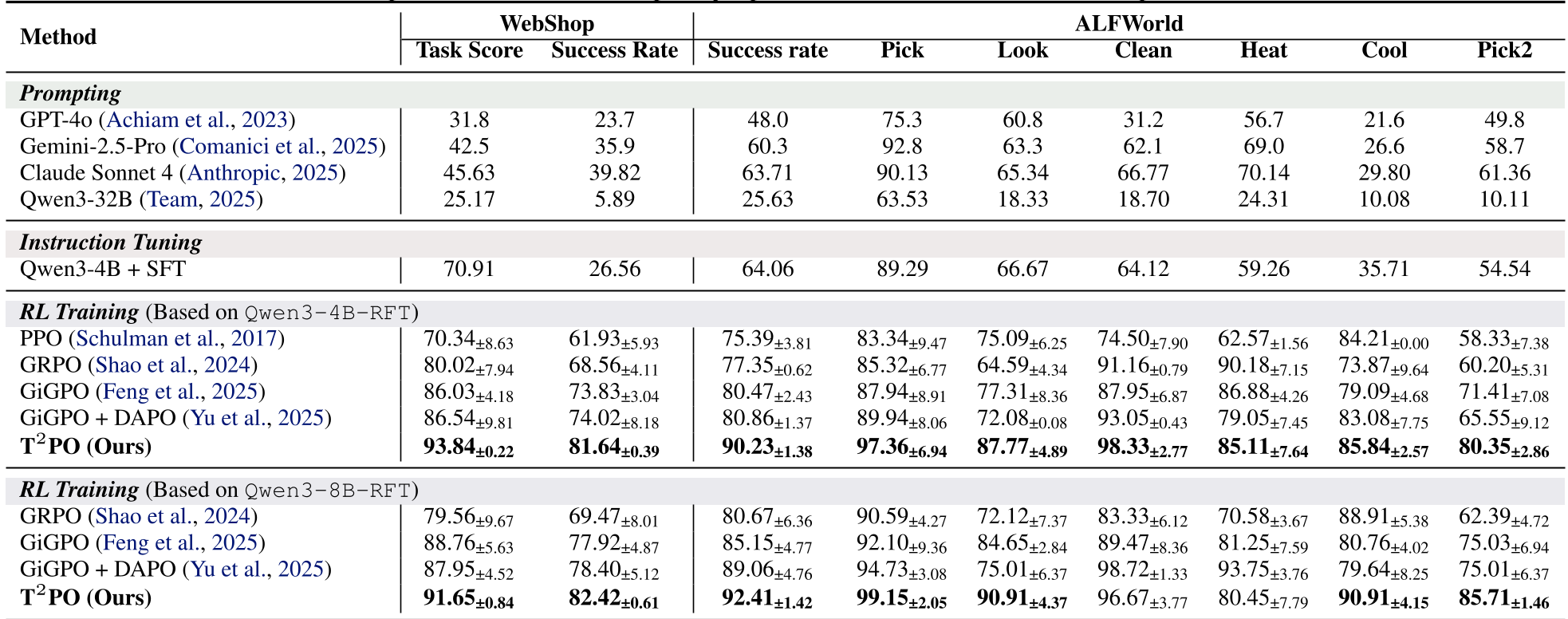 Table 1: Quantifying the massive lead in success rates over PPO, GRPO, and GiGPO.
Table 1: Quantifying the massive lead in success rates over PPO, GRPO, and GiGPO.
Critical Insight: Efficiency is Effectiveness
The most profound takeaway from T2PO is that training effectiveness and efficiency are not at odds. By pruning the noise (the "hesitation"), the learning signal becomes cleaner. This allows the agent to learn the "causal" relationship between its reasoning and the outcome much faster.
Limitations & Future Work
While T2PO excels in structured environments like WebShop, its reliance on specific tags (<think>, <action>) assumes a "Reasoning LLM" backbone (like Kimi or DeepSeek-style models). Future work could explore how to adapt this to models that do not use explicit CoT tags.
Conclusion
T2PO represents a shift from implicit control (reward shaping) to explicit control (uncertainty-guided intervention). For developers building agents, the message is clear: if you want a stable RL agent, don't just wait for it to fail; monitor its uncertainty and stop it once it stops learning.