本文提出了 T2PO,一种针对多轮代理强化学习(Agentic RL)的动态探索控制框架。该方法通过在 Token 和 Turn(回合)两个层级引入基于自校准不确定性的干预机制,显著提升了推理型大模型在 WebShop、ALFWorld 等复杂交互任务中的训练稳定性和 SOTA 性能。
TL;DR
在多轮强化学习(Multi-turn RL)中,Agent 的“过度思考”和“原地打转”往往是导致训练崩溃的元凶。本文提出的 T2PO (Token- and Turn-level Policy Optimization) 框架,通过监控模型内部的 不确定性(Uncertainty) 动态,在 Token 层级切断无效冗余推理,在 Turn 层级重采样重复行为。它不仅刷新了 WebShop 和 ALFWorld 的 SOTA 记录,更重要的是让 Agent 变得“干脆利落”,训练过程稳如磐石。
1. 痛点深挖:Agent 为什么会“训练崩溃”?
在追求“思考过程(CoT)”的今天,我们发现推理型 LLM Agent 在强化学习中经常展现出一种病态的 Hesitation(迟疑) 行为:
- Token 层级的过载:模型生成了极长的思考过程,但在这些 Token 中,信息增益迅速饱和,而随机噪声却不断累积。
- Turn 层级的停滞:Agent 在多个回合中反复执行语义相似的错误操作,无法从失败中自我纠正。
这种低质量的 Rollout 引入了巨大的梯度方差,导致 KL 散度和梯度范数在训练中后期瞬间爆炸(见下图),即所谓的 Training Collapse。
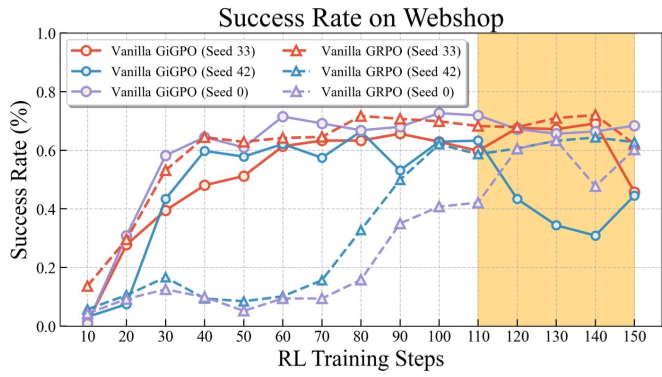
2. 核心直觉:自校准不确定性信号
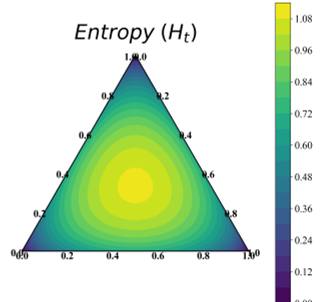
作者认为,Token 的熵(Entropy)和置信度(Confidence)虽然都能反映不确定性,但各有限制:熵在极端分布下区分度较差,而置信度忽略了长尾分布。
T2PO 设计了一个 自校准稳定性信号 ,通过融合归一化的熵与置信度,创造了一个非线性的等高线空间(见下图)。这个信号能够精准捕捉模型何时对当前思考感到“满意”或是进入了“迷茫的重复”。
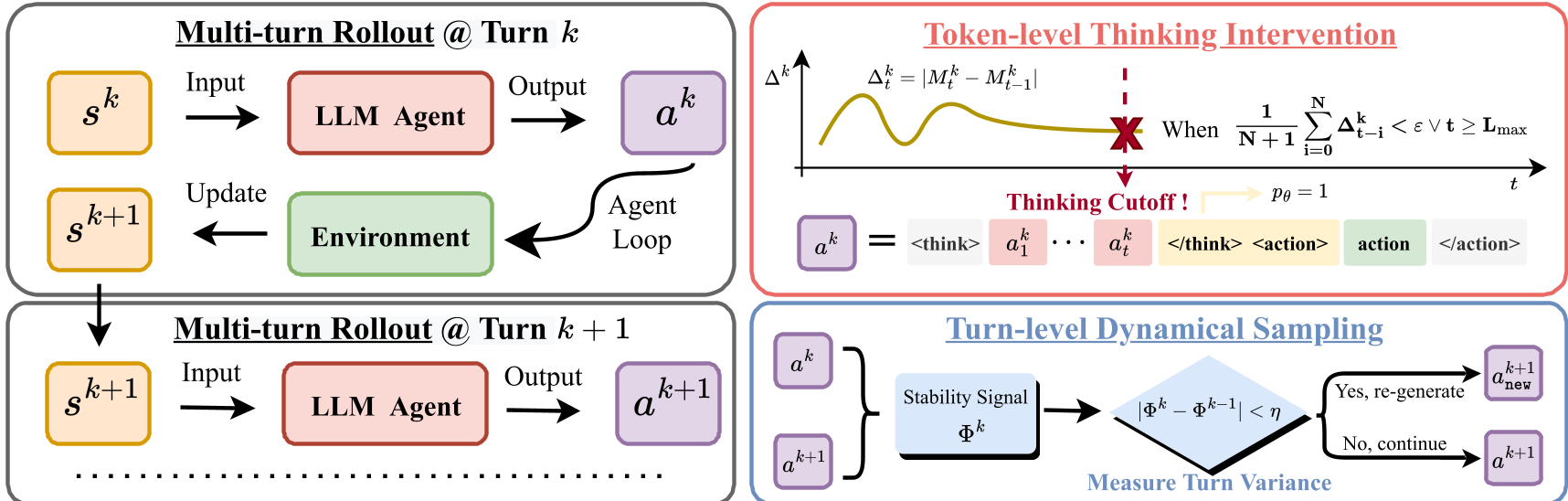
3. 方法论详解:双层级干预机制
3.1 Token 层级:思考干预 (TTI)
模型在推理时,会产生一个“啊哈时刻(Aha Moment)”,此时不确定性剧变;但在随后的冗余推理中,不确定性的边际变化(Marginal Change)趋近于零。
- 逻辑:当一个滑动窗口内的 变化量低于阈值 时,系统强制注入
</think>标记。 - 物理含义:既然继续想下去也不会增加确定性,那就立刻停下来去执行。
3.2 Turn 层级:动态采样 (TDS)
如果不确定性在不同回合之间表现出高度相似的模式,说明 Agent 陷入了重复思维。
- 逻辑:计算回合内的特征信号 ,若相邻回合的变化 ,则直接丢弃该 Rollout 并触发 重采样。
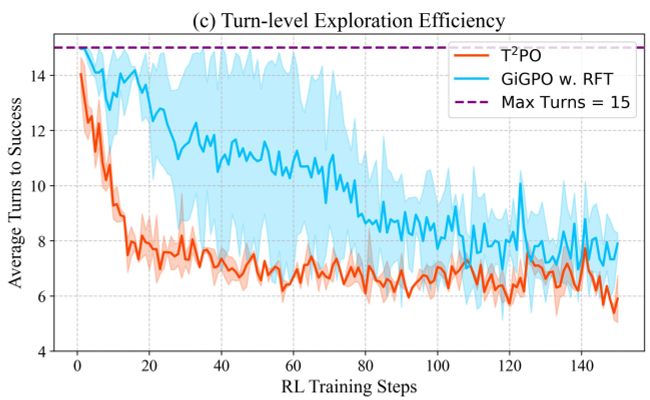
4. 实验与结果:不仅更准,而且更稳
在 WebShop 和 ALFWorld 等严苛的交互环境中,T2PO 表现出了碾压级的优势:
- 性能:在 WebShop 上达到了 81.64% 的成功率,远超 GPT-4o 的 Prompting 表现(23.7%)。
- 效率:完成相同任务所需的 Token 数量减少了约 20%,交互回合数减少了约 25%(见下图)。
消融研究
去掉 RFT(冷启动)、TTI 或 TDS 中的任何一个模块,性能都会出现显著下滑,特别是 TDS 的缺失会导致模型在多轮交互中失去多样性。
5. 深度洞察:为什么 T2PO 能有效?
传统的稳定方法(如奖励建模或轨迹过滤)大多是在“事后”修补。而 T2PO 是一种 “事中”干预。它直接在 Agent 产生垃圾轨迹之前就将其截断。
- 降低 Variance:通过减少冗余 Token,显著降低了策略梯度的方差。
- 高质量数据流:强迫模型始终在具有高信息增益的区域探索,避免了在低效区域的无效梯度更新。
6. 总结与局限
Takeaway: T2PO 证明了 Agent 的思考不是越长越好,精细化的不确定性感知是实现多轮 RL 稳定性的银弹。
局限性: 目前的阈值 和 仍属于启发式超参数。未来的研究方向可以探索如何让阈值随着训练进程自适应演进,从而进一步释放推理型 LLM 的潜力。