本文提出了 TabEmbed,这是首个统一了表格分类与检索任务的全能型(Generalist)嵌入模型。同步推出的 TabBench 成为评估模型在数值推理与语义对齐能力上的核心基准。
TL;DR
在自然语言处理(NLP)领域,统一特征表示(Unified Representation)已是标配,但在表格数据领域,分类与检索长期处于“各自为战”的状态。由蚂蚁集团、苏州大学等机构联合提出的 TabEmbed,通过统一的对比学习框架,让 0.6B 指令模型在表格理解上完胜 8B 巨头,实现了 Classification(分类)与 Retrieval(检索)在同一向量空间的完美融合。
背景:被“冷落”的表格数据
尽管 LLM 改变了我们与文本交互的方式,但世界上的核心资产依然存储在结构化的表格(SQL/CSV)中。
- 传统痛点:XGBoost 等树模型虽然分类强,但需要固定 Schema,没法做向量检索。
- 大模型瓶颈:通用的文本嵌入模型(如 Qwen-Embedding)把表格当乱序文字读,根本分不清 "Price > 50" 和 "Price < 10" 的物理含义。
作者由此提出两个核心贡献:TabBench(首个针对嵌入模型的表格全方位评测集)和 TabEmbed(全能模型)。
核心动机:为什么要从 Language-to-Row 建模?
传统的自监督表格学习通常会让两个类似的“行”靠近。但这会导致语义坍缩(Semantic Collapse):如果两行只是因为 Label 相同就被拉近,模型就会忽略它们特征值之间的细微差异(例如数值的大小)。
TabEmbed 的直觉:如果我能用自然语言(Query)去“搜”某一行(Row),模型就必须理解 Query 里的逻辑条件。
方法论:统一对比学习框架
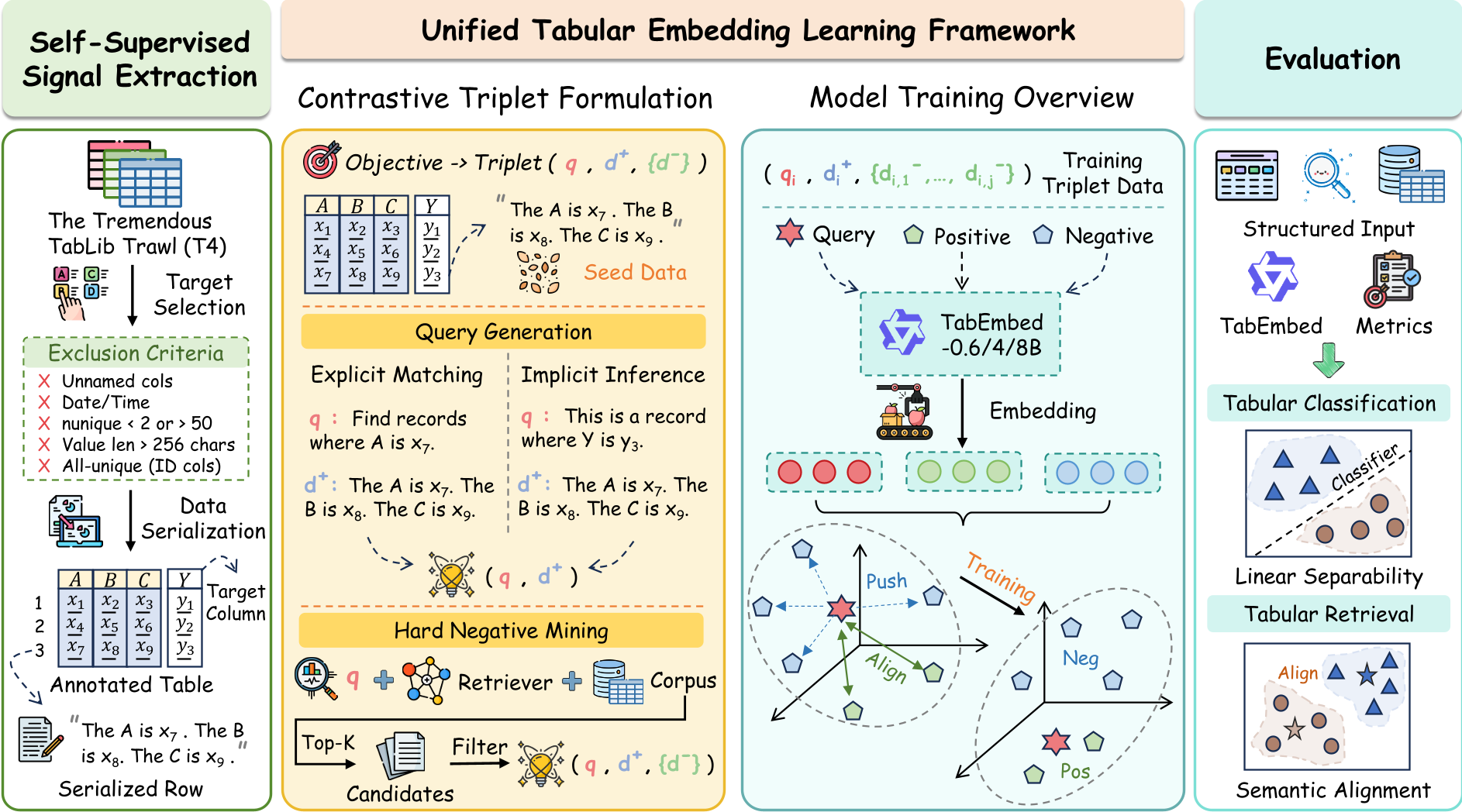
TabEmbed 的训练分为两个关键动作:
- 任务自适应查询生成 (Task-Adaptive Query Generation):
- 检索模式:生成如“找出状态为 Active 且价格小于 50 的记录”的显性 Query。
- 分类模式:生成如“这是一条关于 [类别] 的记录”的隐性 Query。
- 正样本感知的强负采样 (Positive-Aware Hard Negative Mining): 通过检索器找出那些语义极度相似但实际上违反了边界条件的记录(比如价格是 50.1 而不是 50),作为强负样本,逼迫模型学习“数值敏感性”。
实验与结果:参数效率的奇迹
实验证明,TabEmbed 展示了惊人的参数利用率。
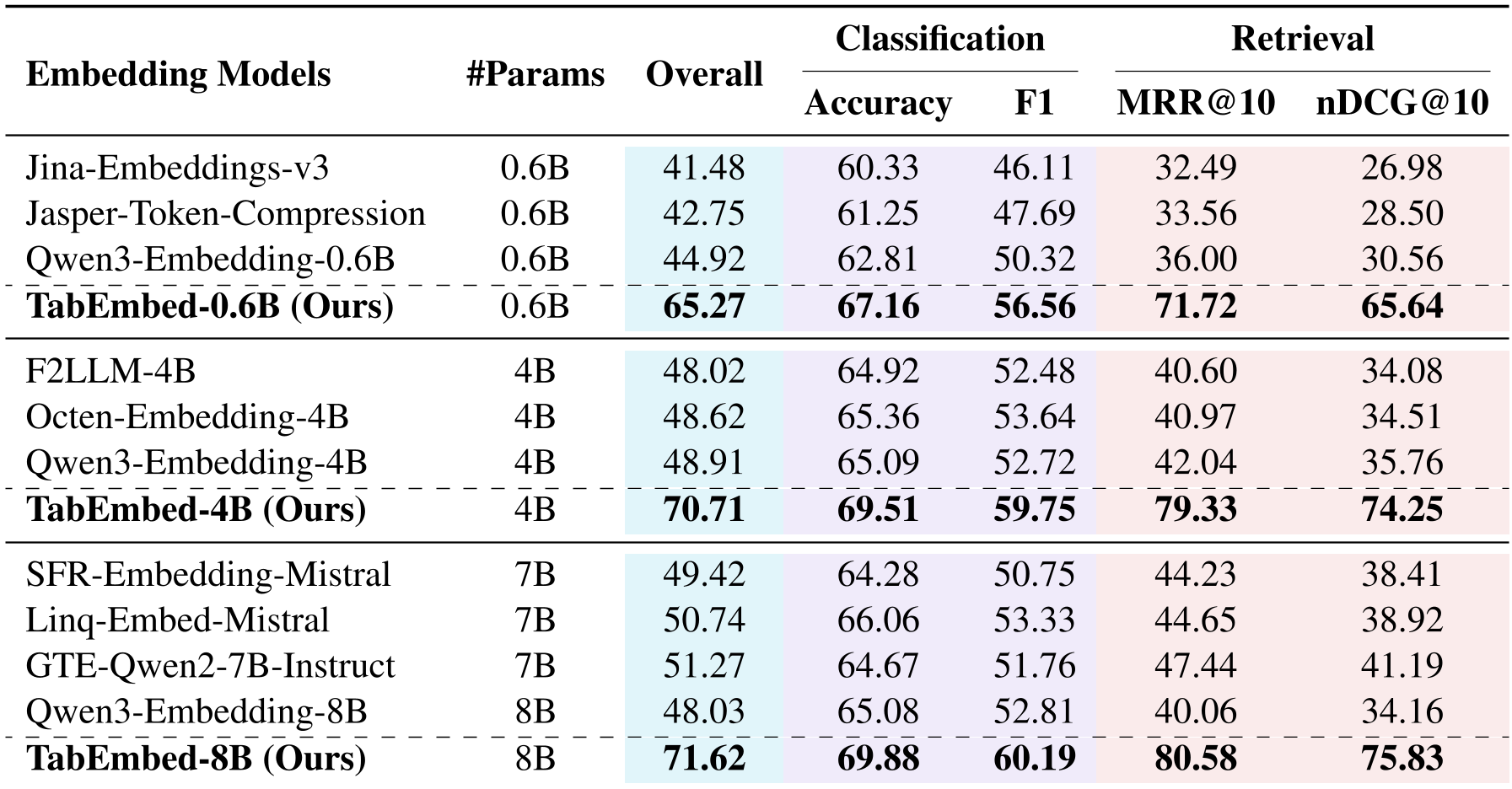
- 降维打击:TabEmbed-0.6B 的综合得分远超 Qwen3-Embedding-8B。
- 数值觉醒:在数值敏感度测试中(Spearman 相关性分析),TabEmbed 将基座模型近乎随机的表现提升到了 0.8 以上的高相关性。
- 稳健性:即便在表格中加入 30 列无关的干扰信息,TabEmbed 的性能依然保持稳定。
深度洞察:让向量具备“数学思维”
通过可视化分析发现,TabEmbed 成功在向量空间中拟合了“阶跃函数”。
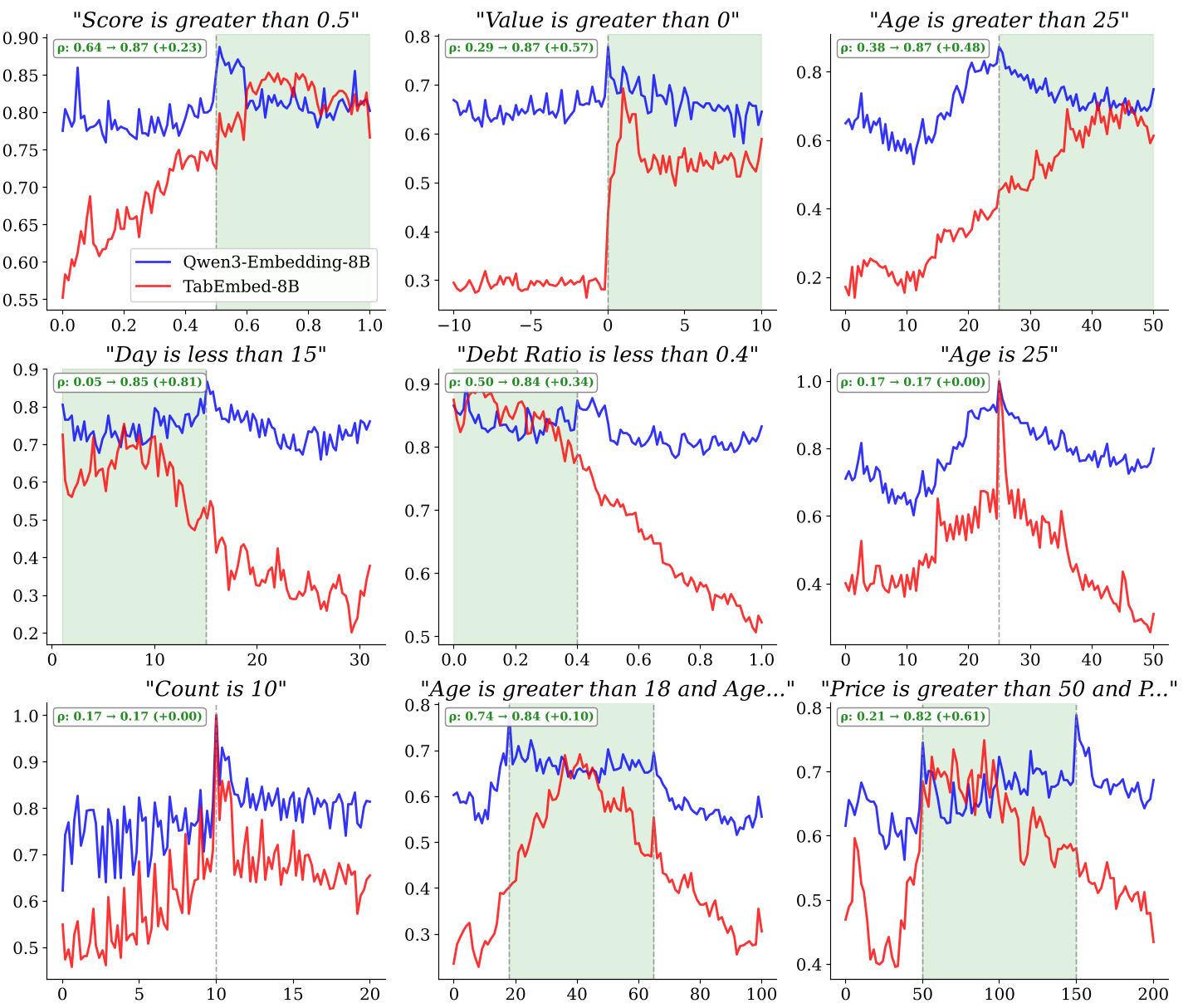 上图显示,当 Query 是“年龄大于 25”时,TabEmbed 的余弦相似度在 25 这个临界点会产生剧烈的阶跃变化。这意味着它不再仅仅是做 Token 匹配,而是真正内化了数学逻辑。
上图显示,当 Query 是“年龄大于 25”时,TabEmbed 的余弦相似度在 25 这个临界点会产生剧烈的阶跃变化。这意味着它不再仅仅是做 Token 匹配,而是真正内化了数学逻辑。
总结与未来展望
TabEmbed 不仅仅是一个模型,它为工业界提供了一套处理异构数据的标准范式。它在 RAG 系统底层检索、数据湖发现(Data Discovery)以及冷启动预测方面具有巨大的应用潜力。
局限性:虽然对一般表格表现极佳,但对于拥有数百列的超宽表,文本序列化的长度限制仍是一个挑战。未来的研究可能会转向更高效的 Token 压缩或长上下文架构。
本文由资深学术技术主编重构,旨在解析 TabEmbed 在结构化数据理解方面的革命性进展。