本文提出了 Tango,一种针对视频大语言模型(Video LLMs)的高效 Token 剪枝框架。该方法通过引入多样性驱动的显著 Token 选择策略和时空旋转位置嵌入(ST-RoPE),显著提升了视觉信号的利用率,在保留 10% Token 的情况下实现了 LLaVA-OV 98.9% 的性能,并获得 1.88 倍推理加速。
TL;DR
在视频大语言模型(Video LLMs)领域,如何剔除冗余的视觉 Token 而不损耗性能是核心挑战。本文提出的 Tango 框架通过“多样性驱动的选择”和“带有局部性先验的时空聚类(ST-RoPE)”,在仅保留 10% 视觉 Token 的极端情况下,依然维持了原模型 98.9% 的性能,推理效率近乎翻倍。
背景定位:从“重要性”到“代表性”
目前的 Video LLM 效率优化主要走“Token 剪枝”路线。前人的工作或是关注 Saliency(显著性,如根据 Attention 分数选 Top-k),或是关注 Diversity(多样性,如聚类去重)。
然而,本文作者敏锐地发现这两个方向都存在直觉上的缺陷:
- Attention 不是简单的 Top-k 游戏:视频中的注意力分布通常是多峰的(比如同时关注字幕和人物)且长尾的。死板的 Top-k 往往会漏掉那些分值虽低但具有独特语义的“尾巴”区域。
- 聚类不能只看语义相似度:如果仅仅根据特征空间距离聚类,空间上不相连的像素碎块会被强行揉在一起,导致池化后的特征成了无法辨认的“语义噪声”。
核心方法论:Tango 的两把利剑
1. 多样性驱动的显著 Token 选择 (STS)
为了解决 Top-k 的局限性,Tango 采用了一种“先扩容、再聚类、后精选”的策略:
- Step 1: 获取比目标数量更多的候选 Token(通过系数 扩容)。
- Step 2: 在候选池中进行 DPC-KNN 聚类,将潜在的语义区域划分为不同的 Cluster。
- Step 3: 在每个 Cluster 内部选出 Attention 分数最高的 Token。 这样确保了即便某个区域的平均注意力较低,由于它形成了一个独立的语义簇,其中的精英 Token 仍会被保留。
2. ST-RoPE:给相似度加上“距离枷锁”
这是本文最优雅的数学贡献。作者认为:同一个物体的 Token 在空间和时间上应该是连续的。
为此,Tango 引入了 Spatio-temporal Rotary Position Embedding (ST-RoPE)。其核心逻辑是将传统的 1D RoPE 扩展到 三维,并利用 RoPE 特有的 Long-term Decay(长效衰减) 性质: 当两个 Token 的时空距离 增大时,经过旋转后的向量内积自然下调。
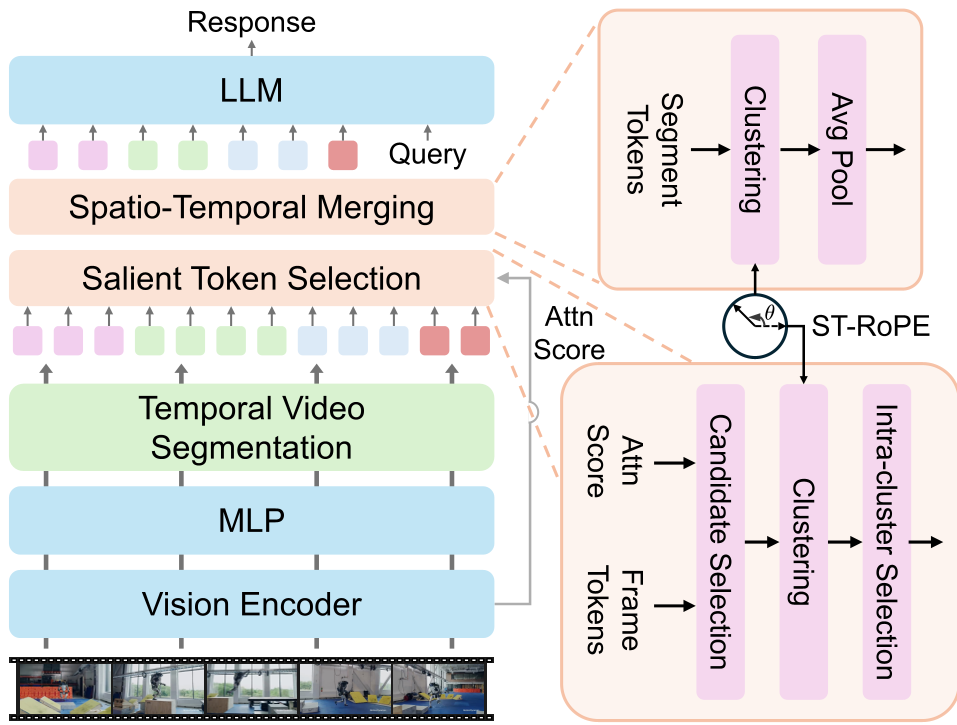 图 1: Tango 框架概览,包含时空分割(TVS)、显著选择(STS)和时空合并(STM)
图 1: Tango 框架概览,包含时空分割(TVS)、显著选择(STS)和时空合并(STM)
这种设计使得聚类过程具有了“几何约束”:只有语义相似且位置接近的 Token 才会聚在一起。如图 2 所示,相比于基线方法产生的碎片化结果,Tango 能够完美保持物体的几何轮廓。
 图 2: 聚类结果对比。底部的 Tango 明显更好地保留了人头部的完整几何形状。
图 2: 聚类结果对比。底部的 Tango 明显更好地保留了人头部的完整几何形状。
实验战绩:低预算下的强者
Tango 在 LLaVA-OneVision, LLaVA-Video, Qwen2.5-VL 等主流模型上均表现出色。
- 性能保持能力:在 10% 的极低保留率下,平均分数达到 58.4,远超同类方法(如 FastVID 的 56.9 和 HoliTom 的 57.1)。
- 推理加速:在 Video-MME 榜单测试中,实现了接近 2 倍的端到端推理提速。
- 帧数扩展性:随着输入视频帧数增加,Tango 的优势越发明显,证明其在处理长视频时的时空冗余压缩非常精准。
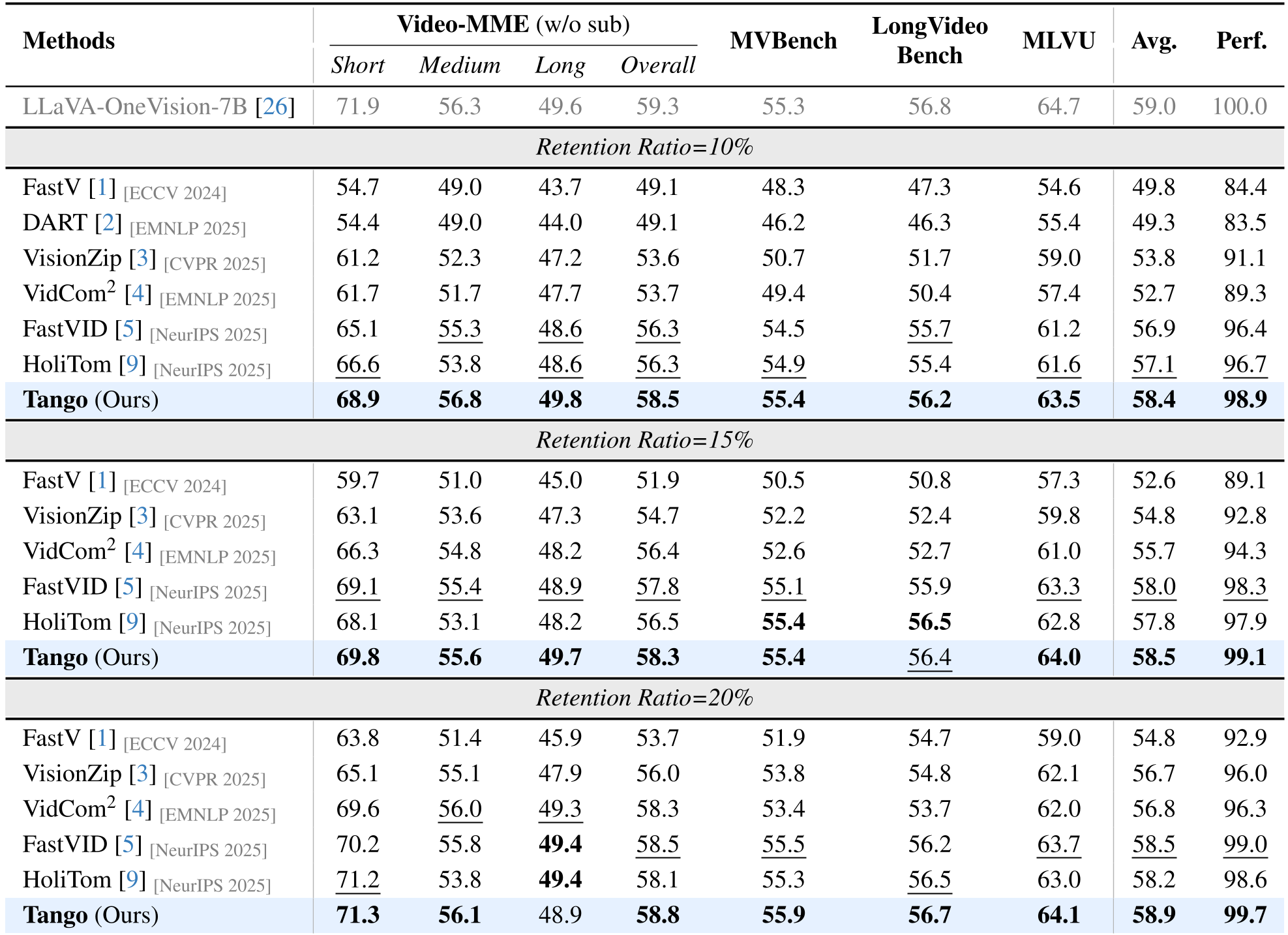 表 1: 在 LLaVA-OneVision 上的性能对比,Tango 在各保留率下均稳占第一。
表 1: 在 LLaVA-OneVision 上的性能对比,Tango 在各保留率下均稳占第一。
深度洞察:关于 Attention Sink 的有趣发现
论文附录部分对 Attention Sink(注意力汇聚) 现象进行了深入拆解。作者发现:
- 在视频模型中,图像四个角落的 Token 往往会分走巨量的注意力(即便那里只是背景)。
- 这种现象在 SigLIP 架构中尤为严重,其源头竟然是 Position Embedding 的初始化。
- Tango 通过自动屏蔽掉这些位置固定的“汇聚点(Sinks)”,成功将模型的视线重新引向了真正的目标。
总结与局限
Tango 证明了通过精细化的时空建模,视频 LLM 的视觉 Token 存在巨大的压缩空间。其 ST-RoPE 的设计不仅解决了效率问题,更在无监督的情况下提供了一定的物体一致性约束。
局限性:虽然 Tango 在通用场景下表现优异,但在处理极致复杂、语义密集的长序列(如成百上千人的运动场面)时,如何选取那些“细微但关键”的 Token 仍是未来的挑战。
关键词:Video LLM, Token Pruning, ST-RoPE, 推理加速, 多样性采样