本文提出了 TAG (Target-Agnostic Guidance),一种针对 Vision-Language-Action (VLA) 模型的轻量级推理时引导机制。该方法通过对比原始图像与目标擦除(Target-erased)图像的预测差异,生成残差信号来增强模型对目标物体的注意力,在 LIBERO 和 VLABench 等基准上显著提升了复杂环境下的操作成功率。
TL;DR
在机器人操作中,VLA 模型(视觉-语言-动作)最尴尬的失败不是“动不了”,而是“抓错了邻居”。中山大学的研究团队提出 TAG (Target-Agnostic Guidance),一种无需改变模型架构的推理增强技术。它通过对比“有目标”和“没目标”的两路信号,强制模型忽略背景杂质,专注于真正的任务目标。
痛点深挖:为什么 VLA 总是“抓偏”?
当你在杂乱的桌面上命令机器人“拿走红色的方块”时,桌上的一堆杂物、光影反射、甚至桌布的纹理都在干扰模型的判断。
作者发现,VLA 模型的失败呈现出明显的规律:
- Instance-level Grounding Failure:模型生成的抓取轨迹在物理上是合理的,但空间误差导致其落在目标旁边(Near-miss)或者抓到了旁边的干扰物。
- Implicit Fusion 的代价:现有的主流模型(如 OpenVLA, π0)依赖注意力机制自动学习背景与目标的权重,但在测试场景稍微改变(如换了光照、相机歪了点)时,这种隐式平衡就会崩溃。
核心逻辑:TAG (Target-Agnostic Guidance)
1. 直觉:找茬式引导
如果原始预测包含“目标信息 + 背景干扰”,而我们造出一个只包含“背景干扰”的预测,那么两者相减,剩下的不就是最纯粹的“目标驱动动作”吗?
2. 数学表述
TAG 借鉴了扩散模型中常用的 Classifier-Free Guidance (CFG)。在 Flow-matching 策略下,预测的引导速度场 定义为: 其中 是引导权重(Guidance Scale)。通过调节 ,我们可以人为地“放大”那些由目标物体诱发的动作趋势。
3. 如何构造“没目标”的图像?
这是本文工程设计的精妙之处。作者开发了一套自动化管线:
- 训练阶段 (I-erase):随机遮闭目标物体并进行 Inpainting。
- 推理阶段 (I-bg):提取背景静态帧(无物体、无机械臂),作为稳定的参考底图。
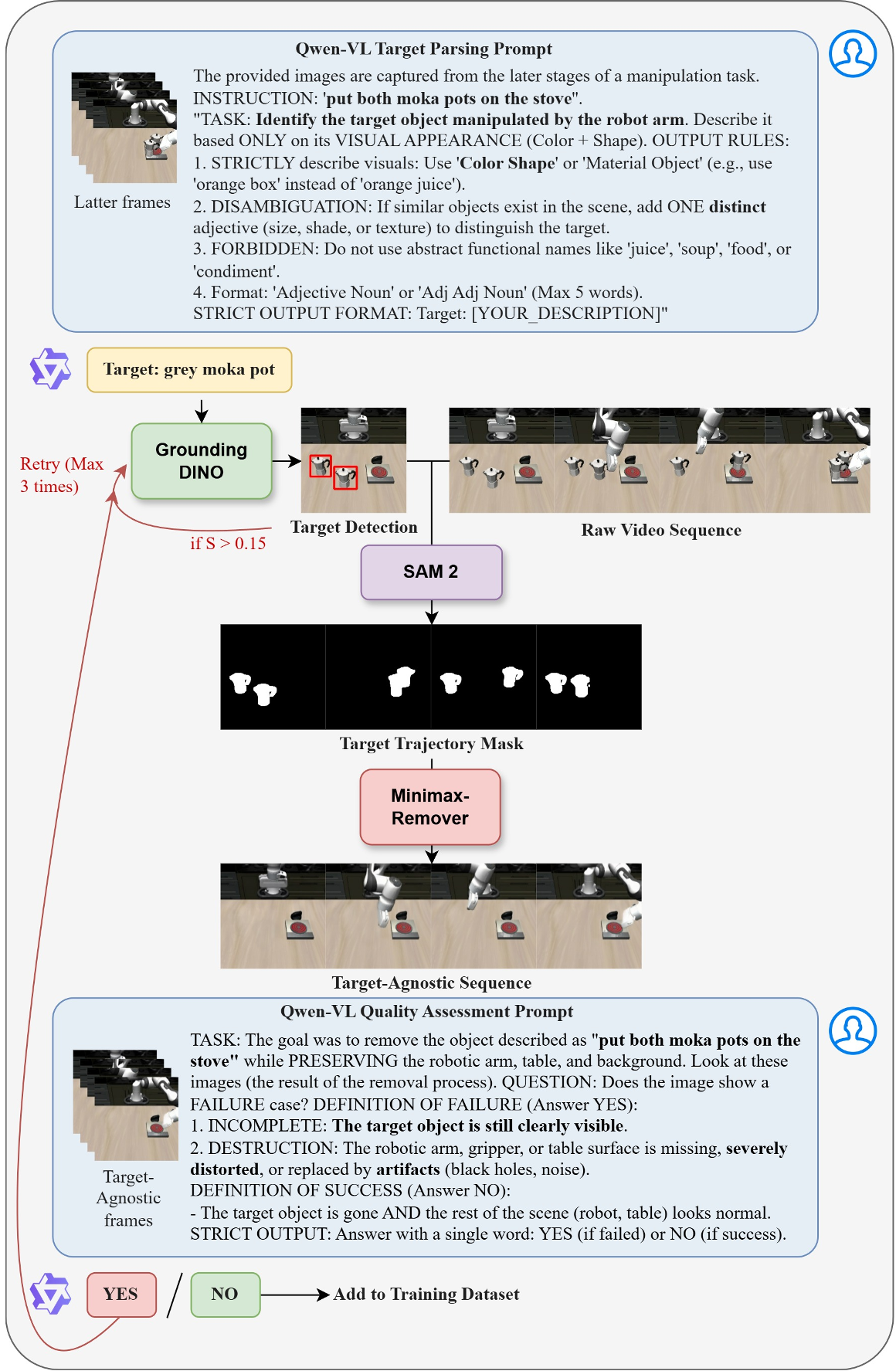 图 1:自动反事实合成管线,利用 SAM 2 和 Inpainting 模型生成目标无关图像。
图 1:自动反事实合成管线,利用 SAM 2 和 Inpainting 模型生成目标无关图像。
实验战绩:多项全能
在多个机器人公开数据集上,TAG 展现了碾压级的提升:
- LIBERO-Long (长时任务):这类任务极易产生复合误差。TAG 让 π0.5 的性能从 89.6% 提升到 97.0%。
- VLABench (高精度任务):在要求选出特定点数的扑克牌或麻将牌时(极多相似干扰),TAG 的表现比 Baseline 高出一倍。
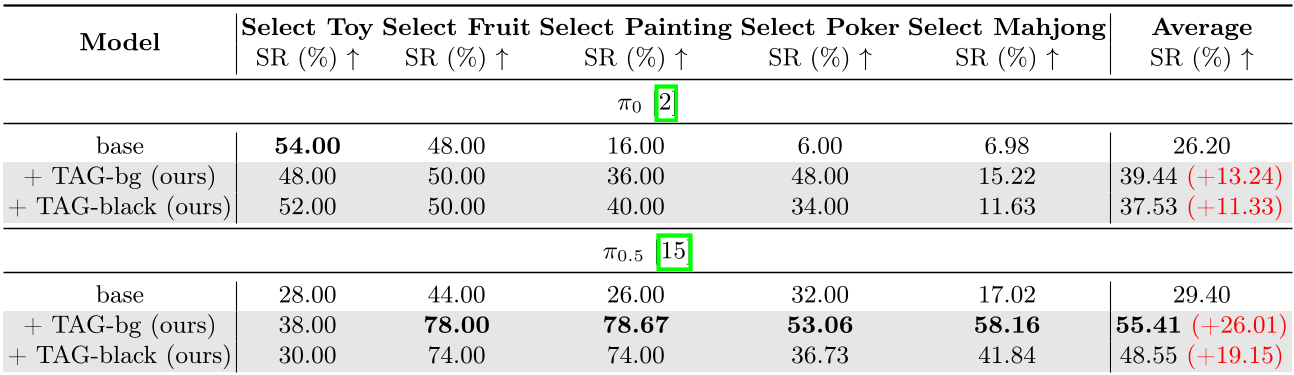 表 1:在 VLABench 复杂选择任务中,TAG 相比 π0/π0.5 基座模型有质的突破。
表 1:在 VLABench 复杂选择任务中,TAG 相比 π0/π0.5 基座模型有质的突破。
此外,消融实验证明,使用“静态背景图”作为引导信号(TAG-bg)远比实时擦除图像更稳定,因为它避免了因 Inpainting 引入的逐帧视觉伪影。
深度洞察
1. 为什么它是“Target-Agnostic”?
传统的引导往往需要明确知道目标的 Class。而 TAG 利用了 LLM 的推理能力和检测器的定位,自动在背景中剥离物体,实现了对任意复杂指令的通用化。
2. 局限性与展望
尽管理论上优雅,但 TAG 在推理时需要运行两次模型前向传导(两路对比),这在算力受限的实时机器人硬件上是一个挑战。此外,如果场景中环境光照发生剧变,预先捕获的背景帧可能会失效。
总结
TAG 为 VLA 模型的鲁棒性问题提供了一个全新的视角:与其强求模型在纷乱的世界中学习注意力,不如在推理时给它一个“擦除目标后”的参照系。这种“去偏”思路可能会成为未来具身智能走向工业级可靠性的重要补充。
关键词:VLA Models, Robot Learning, TAG, Classifier-Free Guidance, 视觉鲁棒性