本文提出了 TARo,一种针对大语言模型(LLM)推理任务的 Token 级自适应路由方法。通过在推理过程中动态平衡冻结的主模型与专门的奖励模型(Reward Model)的输出,TARo 在 MATH500 逻辑推理任务上相比基座模型提升了高达 22.4% 的准确率,实现了高效的测试时对齐(Test-time Alignment)。
TL;DR
Meta 与 Pitt 等机构的研究人员提出了一种名为 TARo 的新框架。它不需要对庞大的基座模型进行重训练(Post-training),而是通过一个极其轻量级的“路由器”,在生成每个字(Token)时动态决定:这一步是听“底座模型”的常识,还是听“专家奖励模型”的逻辑。在 MATH500 任务中,这种灵活性带来了惊人的 22.4% 性能跃升。
背景定位
目前提升 LLM 推理能力的手段大多集中在后训练阶段(如强化学习 GRPO)。虽然效果显著,但代价极大:显存爆炸、领域锁定,且容易产生“偏好塌陷”。测试时对齐(Test-time Alignment) 是一条更轻量化的路径,但之前的做法(如 GenARM)太死板——全局用统一的权重分配,就像给所有难度的数学题都配同样比例的草稿纸,显然不够智能。
痛点深挖:为什么“一刀切”的融合会失效?
传统的对齐方法使用固定系数 : 实验证明(见下图), 的最优值随任务和模型规模剧烈波动。对于某些任务,固定的奖励引导甚至会起到副作用。
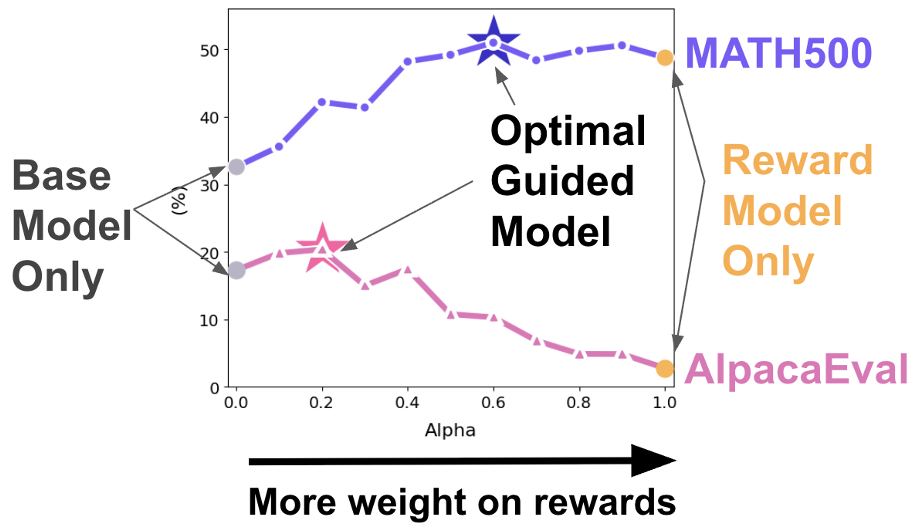
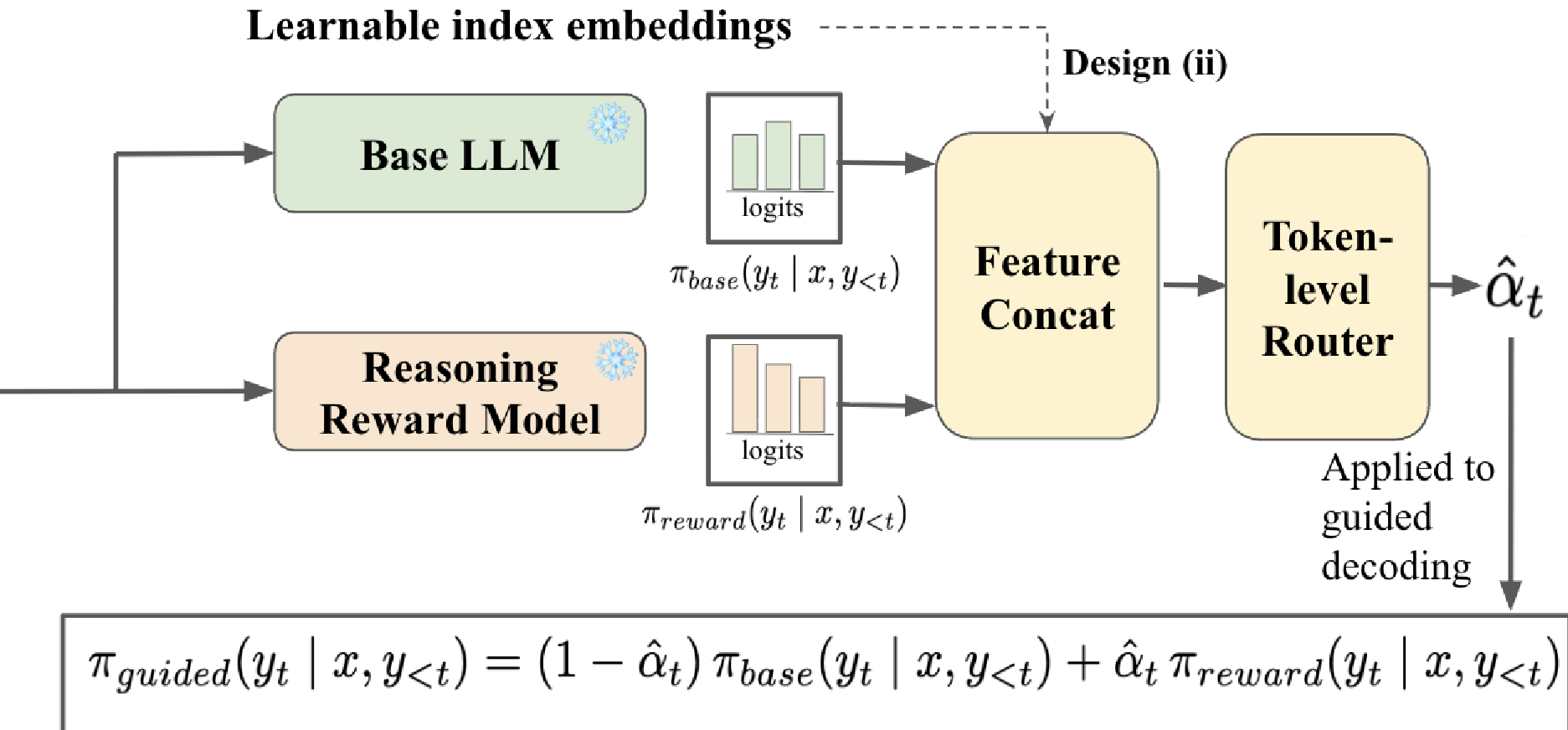
核心方法:Token-level Adaptive Routing (TARo)
TARo 的核心直觉是:并非每个 token 都需要同等强度的奖励引导。
1. 推理奖励模型 (Reasoning Reward LLM)
作者首先在 Math-StepDPO-10K 数据集上训练了一个小巧的奖励模型。它的特殊之处在于使用了 Step-wise(步骤级)的偏好对:当一步推导正确而另一步错误时,强迫模型识别其中的逻辑断点。
2. 轻量级路由器设计
这是本文的精华。路由器 在每个解码步 接收两个模型的 Logits 信息,输出一个动态的 。
- 输入特征:作者权衡了 Hidden States(隐层状态)和 Logits。最终选择了 Logits,因为 Logits 是模型规模无关的(Scale-agnostic),这为后面的“弱到强泛化”埋下了伏笔。
- Top-k 策略:为了减小噪音,路由器只关注两个模型输出概率最高的 K 个候选词。
实验与结果分析
令人惊喜的“弱到强”泛化
最令人振奋的实验是:在 Llama-3-8B 上训练的路由器,可以直接“搬”到 Llama-3-70B 上使用,且效果依然显著。这说明路由器学到的是一种“什么时候该怀疑基座模型”的普适策略,而非特定的参数记忆。
| Method | MATH500 (Acc) | MedXpertQA (OOD) | AlpacaEval (Win Rate) | | :--- | :---: | :---: | :---: | | Base (Llama-3.1-8B) | 32.0 | 13.0 | 17.3 | | GenARM (Fixed Weight) | 49.2 | 11.2 | 10.8 | | TARo (Ours) | 54.4 | 13.2 | 20.8 |
路由器究竟在干什么?
通过对 值的可视化分析(见下表),研究者发现:
- 高 Token:集中在
rightarrow,Step,critical,Evaluate等逻辑转折和运算符号上。 - 低 Token:集中在
period,students,houses等背景描述词上。 这证明了路由器学会了“逻辑骨架靠奖励模型,自然语言表达靠基座模型”的分工模式。

深度洞察:为什么 TARo 有效?
- Inductive Bias 的精准捕捉:推理任务的本质是离散的逻辑跳跃,而非平滑的文本生成。Token 级的路由精准捕捉到了这些“关键节点”。
- 避免“指令退化”:通过动态路由,当模型生成通用文本时( 低),基座模型的预训练知识得以保留,避免了为了逻辑而丢失指令遵循能力的代价。
结论与展望
TARo 提供了一种极具工程价值的思路:我们可能不需要为每个垂直领域都去微调一遍 70B 甚至 400B 的巨型模型。通过训练一系列 1B/8B 规模的领域路由器和奖励专家,我们可以像“外挂组件”一样动态提升巨型模型在数学、医学或编程上的表现。
局限性:目前的奖励模型仍然可能在错误的路径上一条路走到黑,未来引入“回溯(Backtracking)”机制将是更进一步的突破口。