本文提出了 TRouter,一种任务类型感知的大语言模型 (LLM) 路由框架,旨在解决冷启动环境下(缺乏领域内训练数据)的路由难题。核心方法包括一个多级任务概况引导的数据合成框架,用于模拟测试分布生成高质量 QA 对。
核心速览
TL;DR:大语言模型(LLM)层出不穷,但如何在保证效果的前提下最省钱?传统的“路由器”需要大量真实数据来训练,这在产品刚上线(冷启动)时简直是天方夜谭。本文提出的 TRouter 通过“分层任务分类+合成数据引导”,在没有任何真实训练数据的情况下,实现了超越传统有监督学习方法的路由性能。
背景定位:该工作是 LLM 路由(Routing)领域的突破,特别是针对实用化落地中的冷启动痛点。它不仅是一个模型,更是一套成熟的“合成-训练-推理”流水线。
痛点深挖:昂贵的“学费”
现有的 LLM 路由器(如 RouterDC, GraphRouter)通常将问题视作分类或回归:给每个 Query 打分,选出性价比最高的模型。但它们的死穴有二:
- 数据依赖:训练路由器需要数千条真实 Query 并给所有候选模型跑一遍测试。这不仅慢,而且昂贵(API 采样成本)。
- 领域偏移(Domain Shift):在写代码数据集上训练的路由器,放到法律咨询场景几乎直接“报废”。
作者的直觉(Insight)非常敏锐:任务的难度和类别决定了模型表现的上限和成本的下限。既然缺数据,为什么不让 LLM 自己给自己定制一套“模拟卷”?
方法论详解:TRouter 的双核驱动
1. 多级任务概况引导的数据合成 (Data Synthesis)
这不是简单的 Prompt 增强,而是一个严密的工业化流程:
- 三层分类体系:从 Domain(如数学)到 Subcategory(如代数)再到 Difficulty(五个难度梯度)。
- 质量评估器:利用 LLM 作为审稿人(Self-critique),剔除冗余和模糊的标签。
- QA 对生成:基于细粒度的任务描述(Task Profile)生成高质量问答。
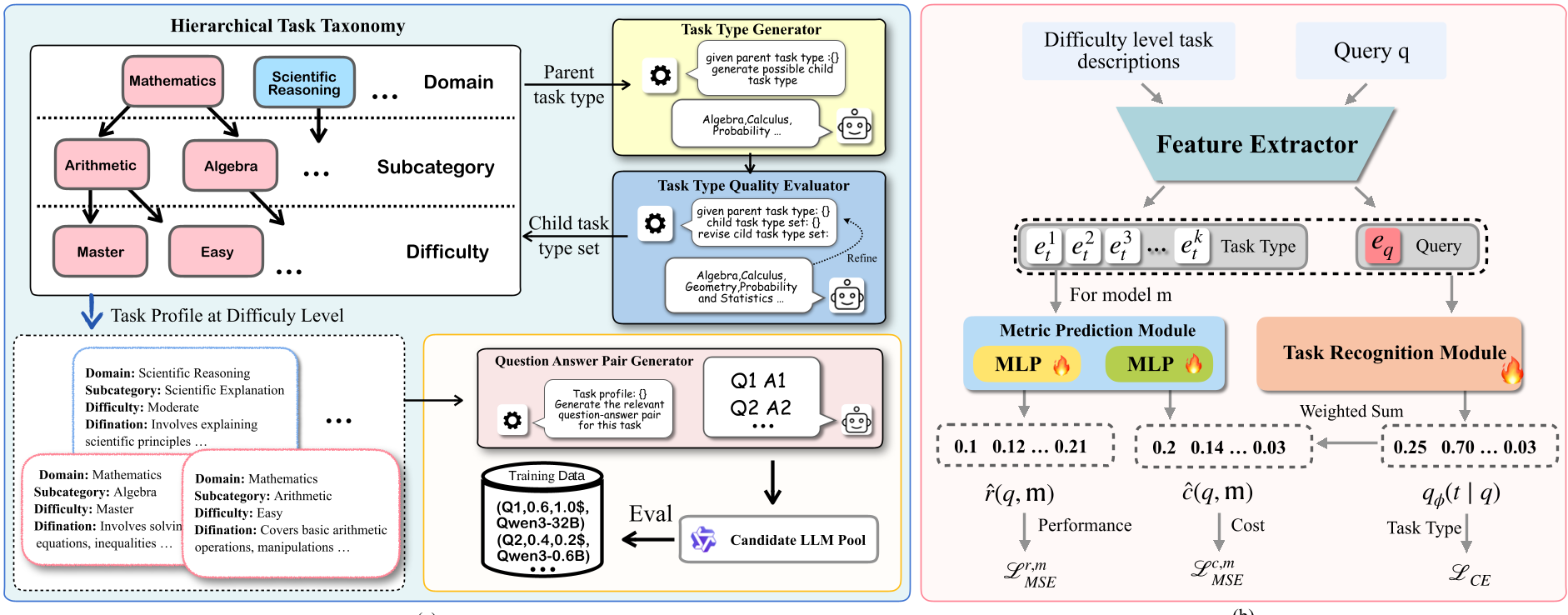
2. 隐变量路由框架
TRouter 的精髓在于它不直接从原始 Query 预测成本。它假设存在一个隐藏的“任务类型 ”。
- 数学美感:通过引入变分后验 ,TRouter 将性能/成本预测分解为先验正则化项。这使得路由器在面对从未见过的 Query 时,能根据其任务语义特征快速收敛。
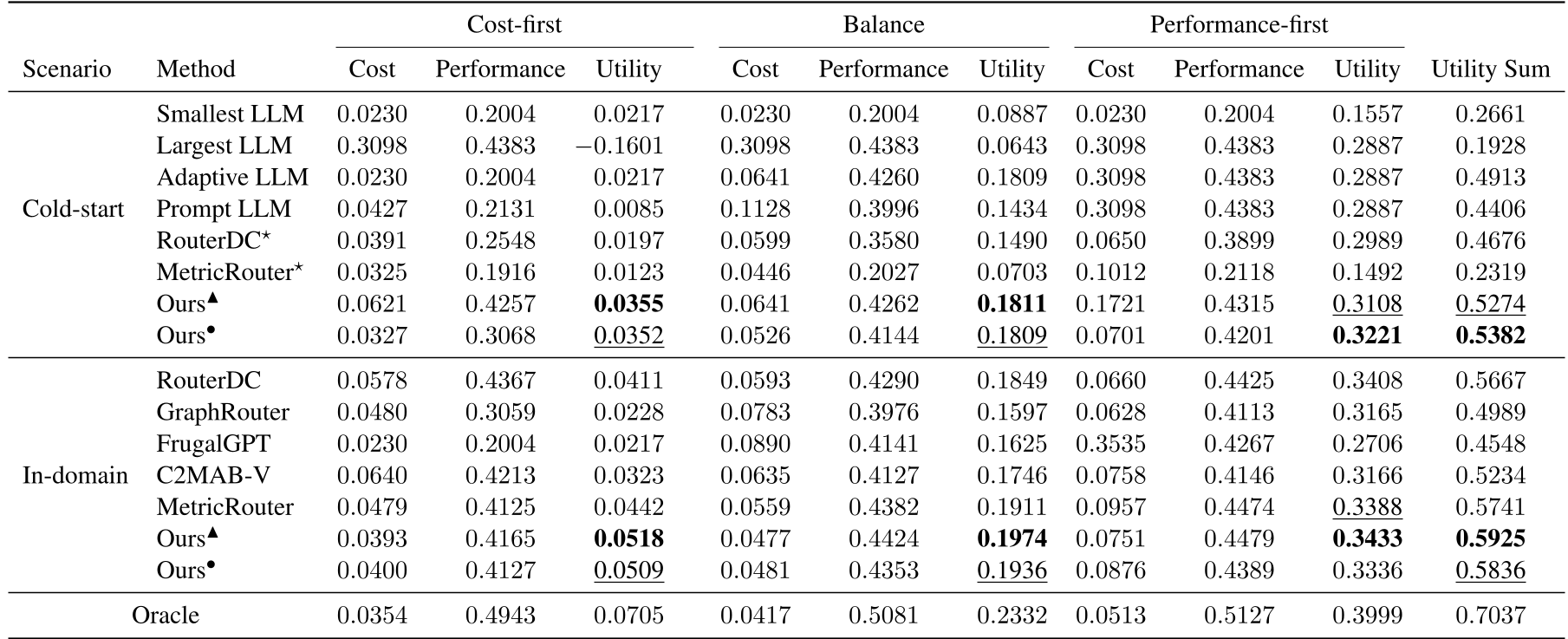
实验与结果:冷启动下的奇迹
在 Qwen 3 系列模型(从 0.6B 到 235B)的路由池中,TRouter 展现了极强的统治力:
- 零数据胜有数据:在 LLM-as-a-judge 评估协议下,仅靠合成数据训练的 TRouter 竟然超过了在真实数据上训练的 RouterDC 和 MetricRouter。
- 小样本效率:消融实验显示,TRouter 每个任务类型只需 5-10 个样本即可达到近乎 SOTA 的表现,展示了极高的采样效率。
此外,作者对比了“人工标注”与“合成数据”的效果(Table 12),发现合成数据的质量在路由任务中完全可替代成本高昂的专家标注。
深度洞察与总结
关键结论 (Takeaway)
- 任务感知是关键:路由器的本质是理解“题目的难易色调”,而非死记硬背 Query 内容。
- 合成数据的威力:在理解模型能力边界这件事上,LLM 比人类更了解彼此(LLM understands LLMs)。
局限性与展望
尽管 TRouter 表现惊艳,但它目前依赖于 GPT-4 等强模型作为教师机来合成数据。如果教师机本身对某一领域存在偏见(如特定的冷门小语种),那么合成的路由策略也会产生偏差。
未来的方向在于如何让路由器实现增量更新——即在运行过程中,随着用户真实反馈的流回,动态修正其内部的任务先验分布。
资深主编点评:TRouter 最令人兴奋的地方在于其“工程闭环”的完整性。它不仅在学术上探讨了变分路由,更提供了一套让模型路由在实际业务中“生根发芽”的冷启动操作手册。