This paper identifies the "Temporal Trap" in Multimodal Large Language Models (MLLMs), where Video Supervised Fine-Tuning (Video-SFT) consistently enhances video understanding but degrades static image performance. To address this, the authors propose an instruction-aware Hybrid-Frame strategy that adaptively allocates frame counts, achieving comparable video gains while preserving spatial reasoning over SOTA models like Qwen2.5-VL and LLaVA.
TL;DR
The industry largely assumes that training Multimodal Large Language Models (MLLMs) on video data (Video-SFT) is an "all-round" win. This paper proves otherwise, uncovering the Temporal Trap: a phenomenon where video gains come at the direct cost of spatial (image) reasoning. By introducing an instruction-aware Hybrid-Frame strategy, the authors demonstrate that we can have the best of both worlds by adaptively sampling frames instead of brute-forcing high frame counts.
The "Temporal Trap": When More Data Isn't Better
As we push MLLMs like Qwen2.5-VL and Gemini 2.5 to handle hours of video, we depend on Video Supervised Fine-Tuning (Video-SFT) to bridge the gap between static pixels and temporal flow. However, the authors observed a disturbing trend across different architectures (LLaVA, Qwen) and scales (3B to 72B):
- The Conflict: As video scores go up, image scores (MME, MMStar) often stagnate or crash.
- Fine-Grained Decay: Tasks like celebrity recognition and OCR suffer the most, suggesting that temporal training "blurs" the model's ability to focus on high-resolution spatial details.
- The Dimension of Scale: While larger models (72B) are more robust, the trap persists in the most popular 7B-30B parameter range.
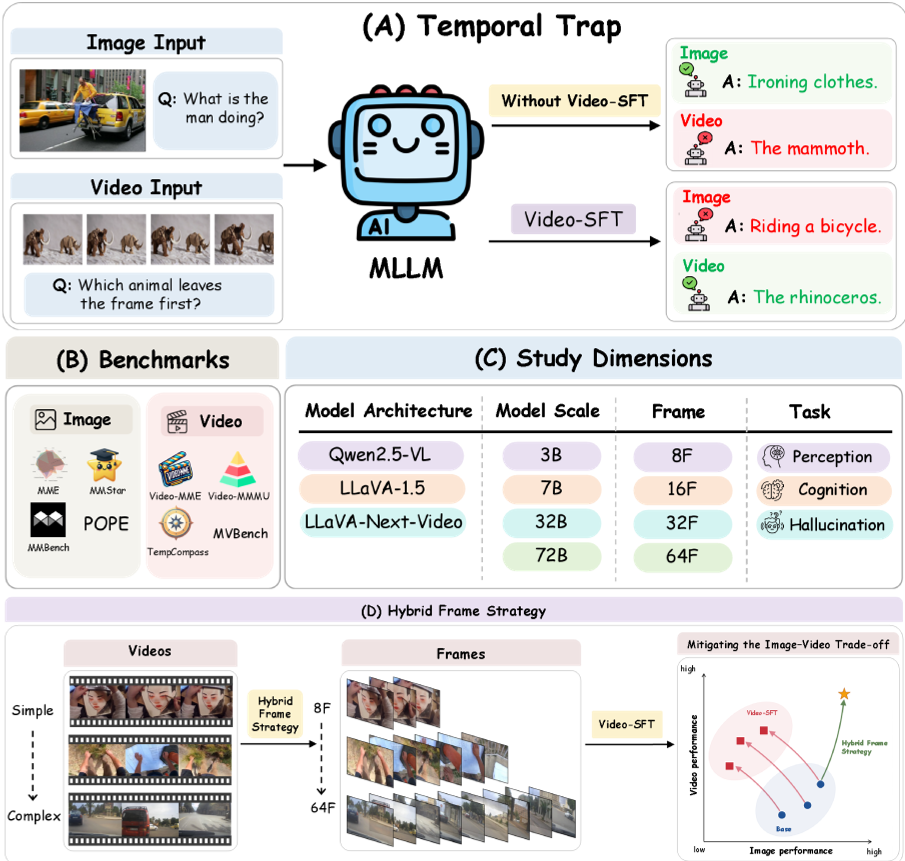
Methodology: Shifting from Fixed to Adaptive Frames
The core of the paper is a theoretical intervention. Through gradient analysis, the authors show that video gradients () contain two parts: a shared visual component and a temporally specialized component. When we use too many frames for a simple task, the "temporal" component starts to dominate, creating a gradient conflict that overwrites the spatial knowledge learned during image pre-training.
The Hybrid-Frame Strategy
To combat this, the authors propose a Hybrid-Frame Strategy. Instead of feeding every video into the SFT process with 32 or 64 frames, they use a small "predictor" model (like Qwen3-VL-8B) to analyze the prompt.
- If the question is: "What color is the car?", the model might only need 8 frames.
- If the question is: "Describe the complex interaction between the three actors", it scales up to 64 frames.
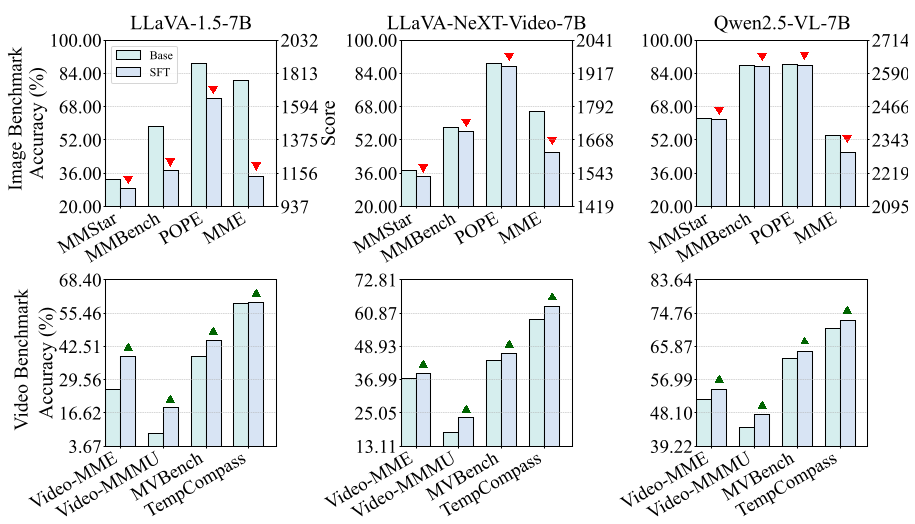
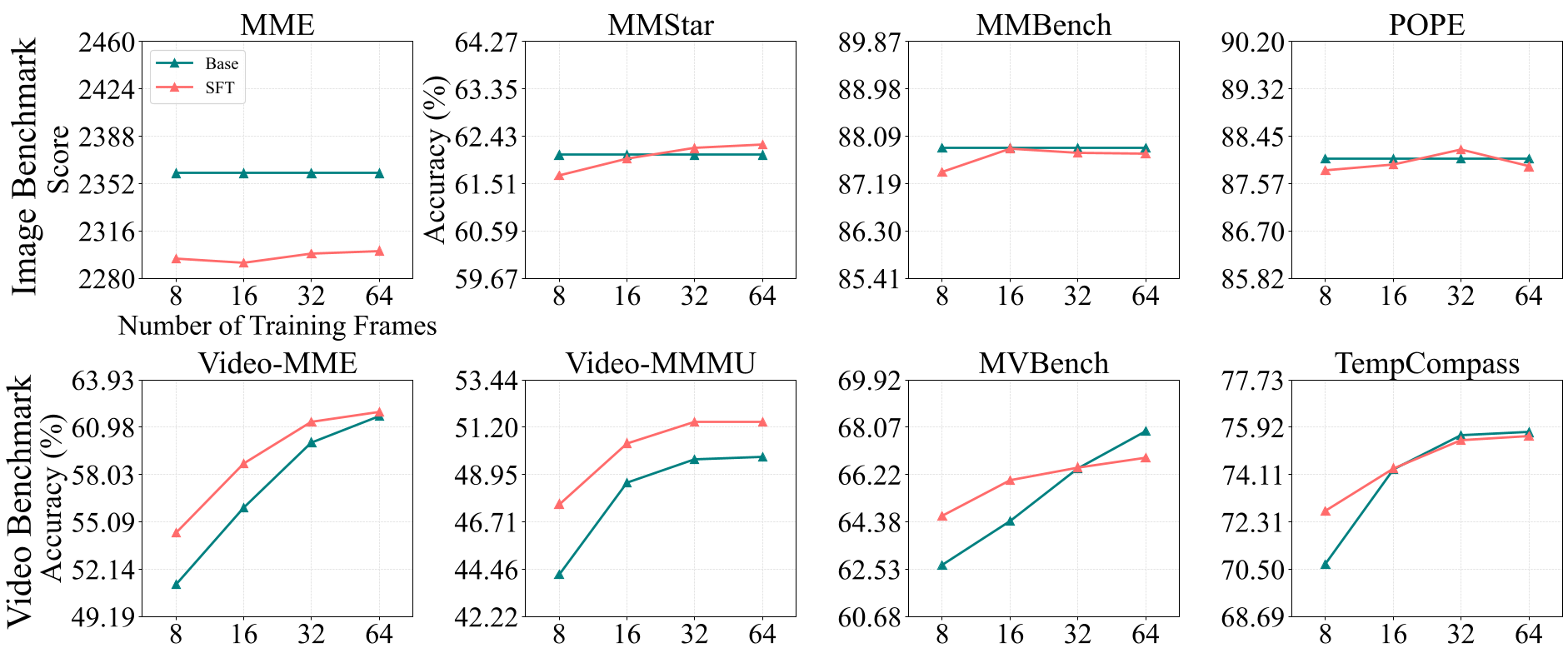
Experimental Evidence: Escaping the Trap
The results across benchmarks show that the Hybrid-Frame strategy isn't just a cost-saver—it's a performance booster.
- Spatial Preservation: On LLaVA-1.5-7B, the Hybrid strategy achieved an MMStar score of 32.47, significantly higher than the 29.40 achieved by 32-frame fixed SFT.
- Efficiency: The average frame count dropped to roughly 11 frames, yet the model maintained competitive Video-MME scores compared to models trained on 64 frames.
- Cross-Scale Robustness: Larger models showed more "localized" attention on objects after Video-SFT, whereas smaller models saw their attention "scattered"—a visual proof of the spatial degradation.
Critical Insight: The Future of Unified Training
The "Temporal Trap" suggests that current MLLM pipelines are fundamentally imbalanced. We are treating videos as just "sequences of images," but the optimization objectives are at war.
Key Takeaways for Practitioners:
- Don't over-sample: Blindly increasing frame counts for SFT might destroy your model's OCR and fine-grained perception.
- Instruction-Awareness is Key: The context of the query should dictate the compute budget.
- Image-Video Synergy: True unification requires more than a shared encoder; it requires gradient surgery or adaptive strategies like Hybrid-Frame to prevent modality interference.
Conclusion
This work serves as a vital reminder that in the era of "All-in-One" multimodal models, adding a new dimension (Time) can inadvertently shrink others (Space). The Hybrid-Frame strategy offers a practical, heuristic-driven path to maintain spatial integrity while conquering temporal reasoning.