TerraScope is a unified vision-language model (VLM) specifically designed for pixel-grounded geospatial reasoning in Earth Observation (EO). By integrating a mask decoder into a VLM framework, it achieves SOTA performance on tasks requiring precise spatial analysis, such as land-cover area quantification and multi-temporal change detection, outperforming existing models on the new TerraScope-Bench.
Executive Summary
TL;DR: TerraScope is a landmark Vision-Language Model (VLM) that moves beyond simple image captioning to pixel-accurate geospatial reasoning. By interleaving text generation with precise segmentation masks, it can "see" and "quantify" Earth features (Area, Distance, Change) with unprecedented accuracy.
In the landscape of Earth Observation (EO) research, most models are either specialized perception tools (Segmentation/Classification) or general-purpose chat bots. TerraScope bridges this divide, establishing a new SOTA by embedding a "pixel-thinking" mechanism directly into the Transformer's reasoning loop.
Problem & Motivation: The "Coarse-Grain" Trap
Traditional VLMs, including giants like GPT-4o, treat spatial grounding as an afterthought. They often use Bounding Boxes to identify objects. While boxes work for a cat or a car in a natural image, they are disastrous for Earth Observation.
- Continuous vs. Discrete: Land cover (forests, water, crops) doesn't fit in boxes; it has irregular, continuous boundaries.
- Multi-Sensor Blindness: Satellites provide diverse data—Optical (spectral) and SAR (radar). Existing models usually pick one or dump both into a messy concatenation, failing to leverage SAR's ability to "see" through clouds when the Optical sensor is blind.
The authors' insight is simple but powerful: To reason about the Earth, the model must localize at the pixel level before it calculates.
Methodology: Thinking with Pixels
TerraScope's architecture is a trio of a Vision Encoder (InternVL), a Language Model, and a SAM-2 based Mask Decoder.
1. Pixel-Grounded Chain-of-Thought (CoT)
When asked a complex question (e.g., "Is the forest larger than the cropland?"), the model doesn't just guess. It generates a reasoning trace:
- "I first identify the forest regions [SEG]..."
- The [SEG] token triggers the mask decoder to highlight every forest pixel.
- The model then selects those specific "forest tokens" and injects them back into its brain to calculate the area.
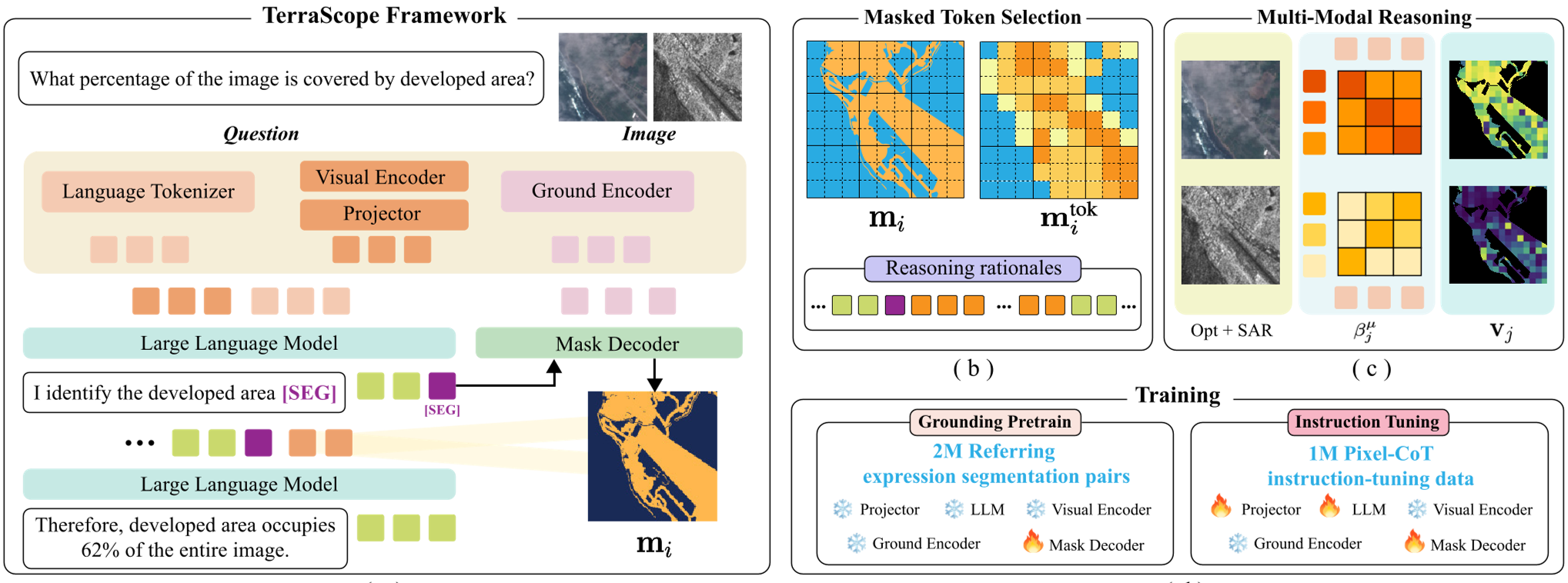
2. Adaptive Multi-Modal Fusion
EO data is messy. If there are clouds, Optical data is useless. TerraScope uses a text-guided cross-attention mechanism to compute a "relevance score" for each token. It adaptively swaps between Optical and SAR tokens at the pixel level—prioritizing SAR where clouds are detected and Optical where spectral fidelity is needed.
Data and Benchmarks: Terra-CoT & TerraScope-Bench
The team curated Terra-CoT, a massive 1M-sample dataset featuring reasoning chains interleaved with pixel masks. To test this, they built TerraScope-Bench, which evaluates models on six high-stakes tasks, including:
- Coverage Percentage Analysis
- Distance Measurement
- Building Change Estimation (Multi-temporal)
Experiments & Results
The performance gap is staggering. On the TerraScope-Bench, the model achieved 68.9% accuracy, nearly doubling the performance of general VLMs like Qwen and InternVL which haven't been tuned for pixel-level precision.
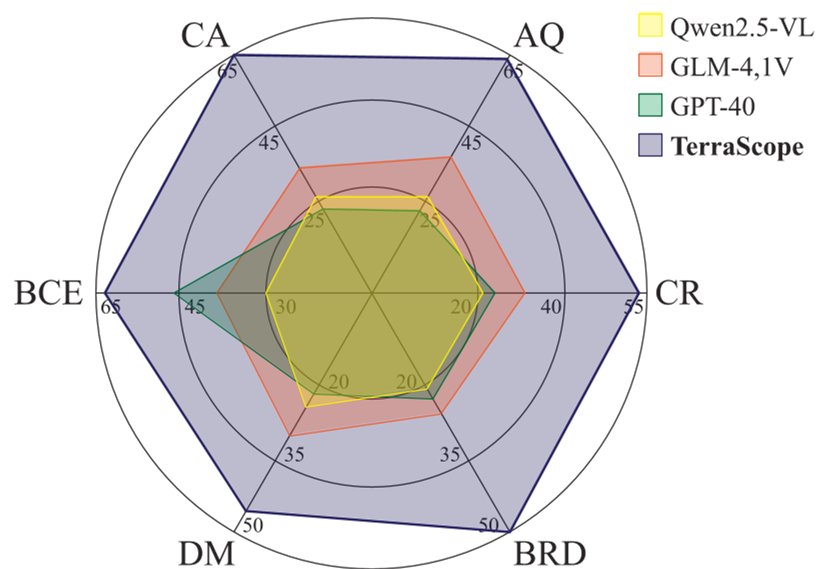 Figure: The correlation between segmentation IoU and answer correctness. Better masks lead to better answers.
Figure: The correlation between segmentation IoU and answer correctness. Better masks lead to better answers.
Key Ablation: Why Pixels Matter
The authors replaced the segmentation masks with Bounding Boxes (Box CoT). The accuracy dropped from 68.9% to 62.8%. This proves that in remote sensing, the precise shape of the feature is the "evidence" required for correct mathematical deduction.
Critical Insight & Future Outlook
Takeaway: TerraScope proves that "implicit" understanding in LLMs is not enough for scientific domains like Earth Observation. We need interleaved visual tokens that act as hard evidence for the model's logic.
Limitations: Currently, the model is limited to RGB + SAR. Future iterations must incorporate Multispectral (NIR, SWIR) bands to distinguish between similar-looking vegetation types. Furthermore, handling "hour-scale" or "year-scale" video-like temporal sequences remains an open frontier for the next generation of TerraScope.
For more details, refer to the full paper "TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation".