本文提出了 TETO (Tracking Events with Teacher Observation),一种基于教师-学生架构的事件相机运动估计框架。通过从预训练 RGB Tracker 中提取知识,仅需 25 分钟无标注真实世界数据即可实现 SOTA 级别的点追踪(Point Tracking)与光流(Optical Flow)估计,并成功应用于高质量视频插帧。
TL;DR
传统的事件相机研究往往陷入“合成数据规模”的陷阱,导致模型在真实复杂场景中表现不佳。TETO (Tracking Events with Teacher Observation) 另辟蹊径,抛弃了数小时的合成数据,转而通过知识蒸馏(Knowledge Distillation)从预训练的 RGB Tracker 中学习。仅凭 25 分钟的无标注真实数据,它就在点追踪、光流预测和视频插帧三大任务上刷新了 SOTA 记录。
1. 痛点:被“诅咒”的合成数据
事件相机(Event Camera)凭借微秒级的时空分辨率,理论上是处理极速运动(Fast Motion)的神器。然而,训练这些模型需要精确的运动标注,这在真实世界中极难获取。
前人工作如 ETAP 和 MATE 依赖于 EventKubric 等合成数据集。但作者通过对 事件间隔 (IEI) 的深度分析发现,合成数据与真实数据存在巨大的分布鸿沟:
- Sim-to-Real Gap:合成模拟器(如 v2e)生成的事件往往存在周期性的人工痕迹,且密度比真实事件稀疏近 25 倍。
- Overfitting:由于合成场景背景简单,模型容易对全局自我运动(Ego-motion)产生严重的归纳偏差,导致在处理独立运动物体时失效。
2. 核心方法论:从老师那里“偷取”直觉
TETO 的核心在于一个教师-学生蒸馏框架。其中老师是一个已经在海量数据上训练过的 RGB Tracker(如 AllTracker),而学生则是需要学习事件处理能力的 TETO。
2.1 运动感知的采样策略 (Motion-aware Sampling)
为了防止学生模型只学会跟着相机晃动(自我运动),作者通过 RANSAC 拟合全局仿射模型,剥离出残差光流,从而定位出场景中的独立运动物体区域。采样时,90% 的查询点被强制投射在这些动态区域中。
2.2 兼容结构:Concentration Network
为了直接复用预训练 RGB 模型的强大匹配能力,作者设计了一个轻量级的 U-Net(Concentration Network),将 B 通道的事件堆栈压缩成 3 通道表征。这保证了预训练的 Backbone 权重无需从头学习,从而极大地提高了小样本下的泛化能力。
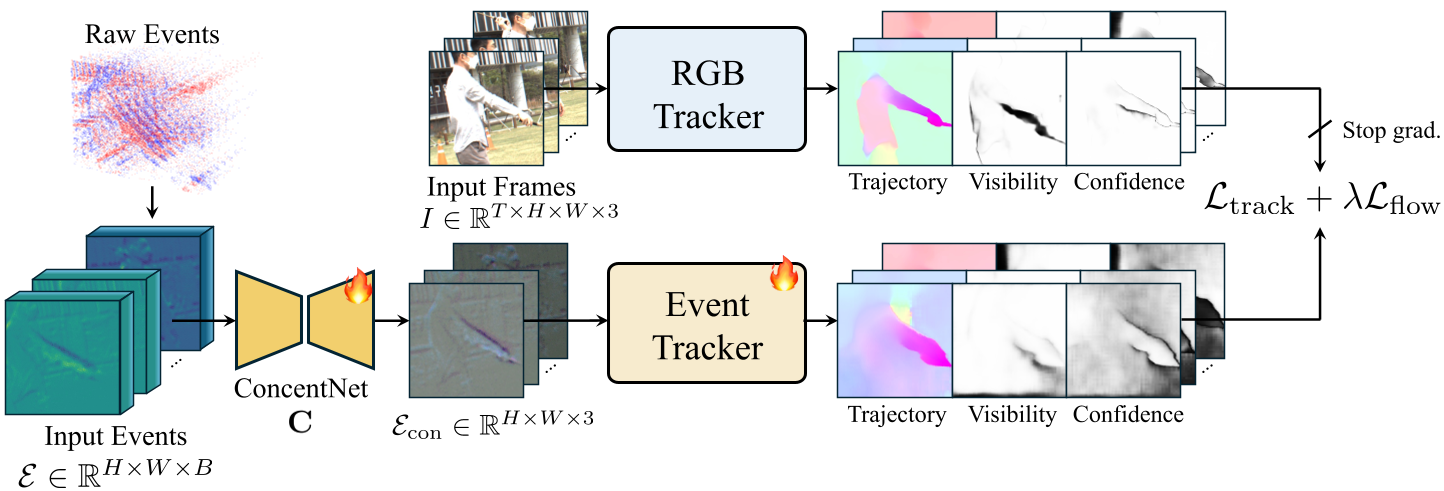 图 1:通过 Concentration Network 将多通道事件转换为 RGB 兼容特征,并接收来自教师模型的伪标签监督。
图 1:通过 Concentration Network 将多通道事件转换为 RGB 兼容特征,并接收来自教师模型的伪标签监督。
3. 视频插帧:当扩散模型拥有“明晰的运动灵魂”
TETO 不仅仅是一个估计器,它为 视频插帧 (VFI) 提供了三层显式的运动先验:
- Latent Warping:利用光流在潜空间对边界帧进行初步对齐。
- Attention Supervision:利用 TETO 预测的长程轨迹点,通过 Huber Loss 约束扩散模型内部的 Attention Maps,强制模型关注真实的几何对应关系。
- Event Motion Mask:直接从原始事件流量中提取掩码,告诉生成模型“这里有动静,重点画这里”。
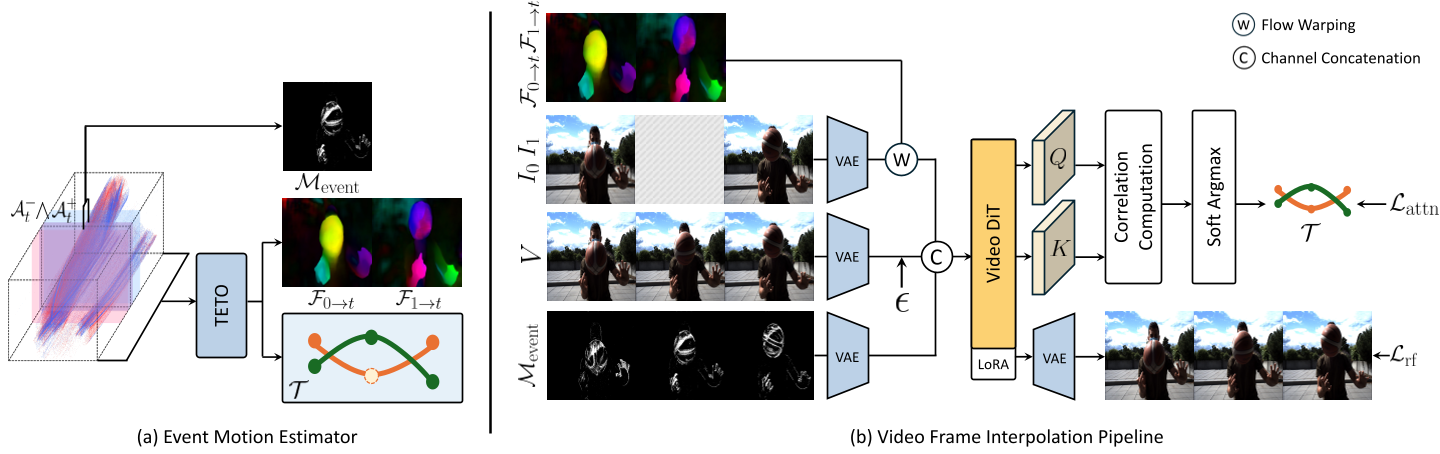 图 2:三管齐下的运动调节策略,将高质量运动先验注入视频扩散 Transformer(DiT)。
图 2:三管齐下的运动调节策略,将高质量运动先验注入视频扩散 Transformer(DiT)。
4. 实验战绩:以少胜多的典范
4.1 惊人的泛化性能
在 EVIMO2 上,TETO 以远少于对手的数据量实现了更高的 AJ 指标(67.9)。更令人振奋的是,在低光、极速等 RGB 教师模型模型彻底失效的场景下,TETO 依然能凭借对事件时空结构的理解输出连贯轨迹。
4.2 极速插帧
在插帧质量(FID/LPIPS)全面超越基线的同时,TETO-VFI 的推理速度比当前的 SOTA 扩散插帧方法 VDM-EVFI 快了足足 8.56 倍。
 图 3:在极端运动与动态物体场景下的点追踪对比,TETO 表现出极强的稳定性。
图 3:在极端运动与动态物体场景下的点追踪对比,TETO 表现出极强的稳定性。
5. 局限性与展望
尽管 TETO 表现优异,但在处理流体运动(如喷泉、火焰)以及阴影诱导事件时仍面临挑战。因为阴影也会触发亮度变化,模型有时会误将阴影当成实体物体追踪。未来的研究可能会引入跨模态的推理,利用 RGB 的语义信息来过滤这些“虚假运动”。
结论
TETO 的意义在于它打破了“学术界必须卷合成数据规模”的思维定式。通过精细的数据策展和明晰的几何先验注入,真实的小样本数据同样能爆发巨大的模型生产力。