THFM (Unified Video Foundation Model for 4D Human Perception) is a generalist perception model derived from a pretrained text-to-video diffusion model. It jointly addresses dense tasks (depth, normals, segmentation, dense pose) and sparse tasks (2D/3D keypoints) in a single architecture, achieving SOTA results on benchmarks like Hi4D and EMDB despite being trained exclusively on synthetic data.
TL;DR
THFM (Unified Video Foundation Model) transforms a text-to-video diffusion model into a versatile "Swiss Army Knife" for human perception. By fine-tuning exclusively on synthetic data, this single model masters both dense geometric tasks (depth, normals) and sparse structural tasks (2D/3D keypoints) in a single forward pass. It doesn't just match specialized SOTA models; it often exceeds them, while showing "emergent" generalization to animals and multi-person scenes.
Background: Beyond Specialization
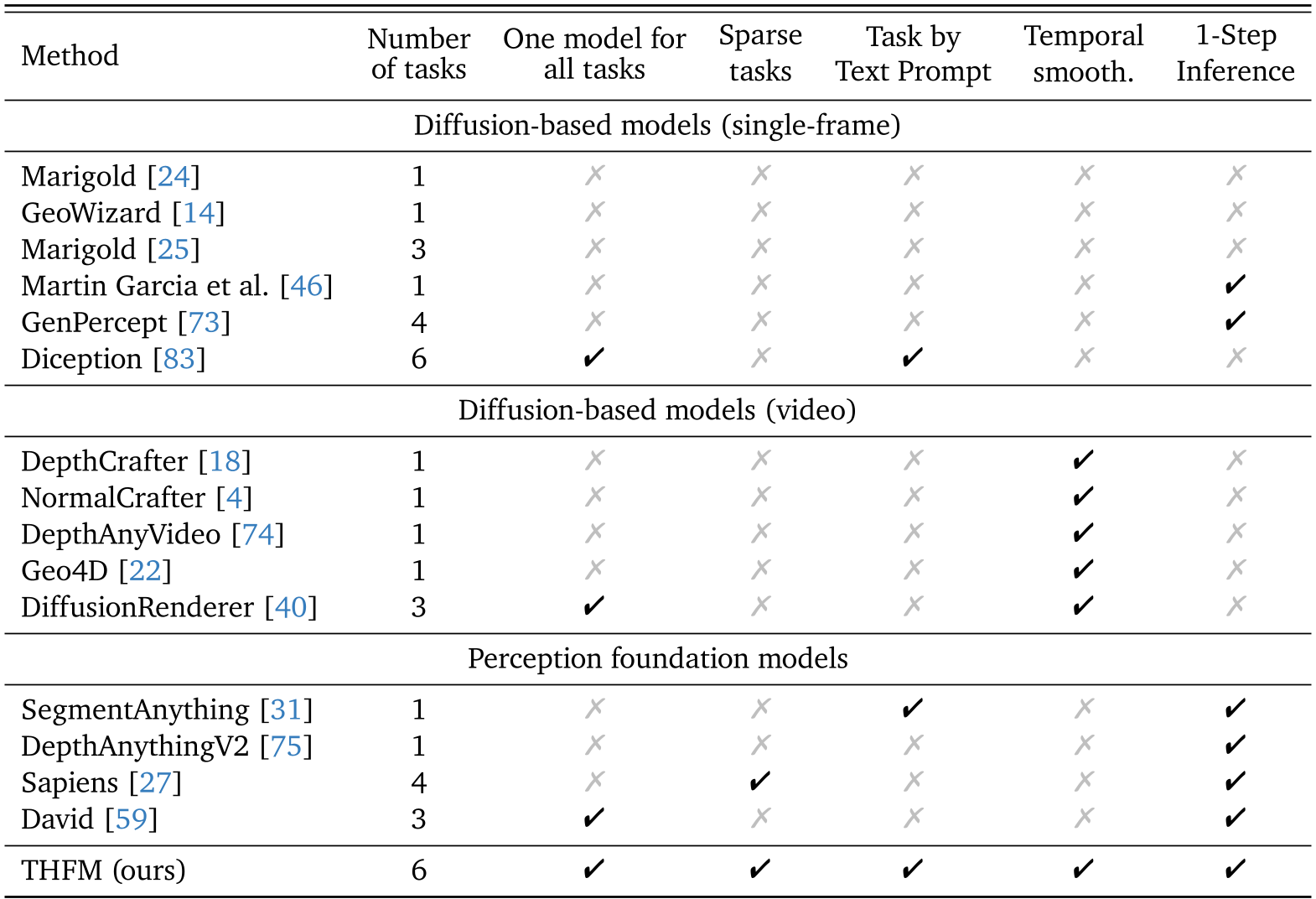
In the current CV landscape, we usually see a "one model, one task" paradigm. If you want surface normals, you use one model; for 3D pose, you use another. This fragmentation is inefficient and ignores the inherent correlations between geometry and motion. THFM asks a radical question: Can a video generation model—already internally aware of 3D consistency and temporal flow—be the ultimate generalist for perception?
The Core Insight: Diffusion as a World Simulator
The authors argue that a model capable of generating realistic videos must implicitly understand:
- 3D Geometry: To keep objects consistent as they move.
- Temporal Dynamics: To simulate realistic motion.
- Semantics: To follow text prompts.
By "freezing" the generative process into a single-step deterministic mapping, THFM extracts this latent knowledge for explicit perception tasks.
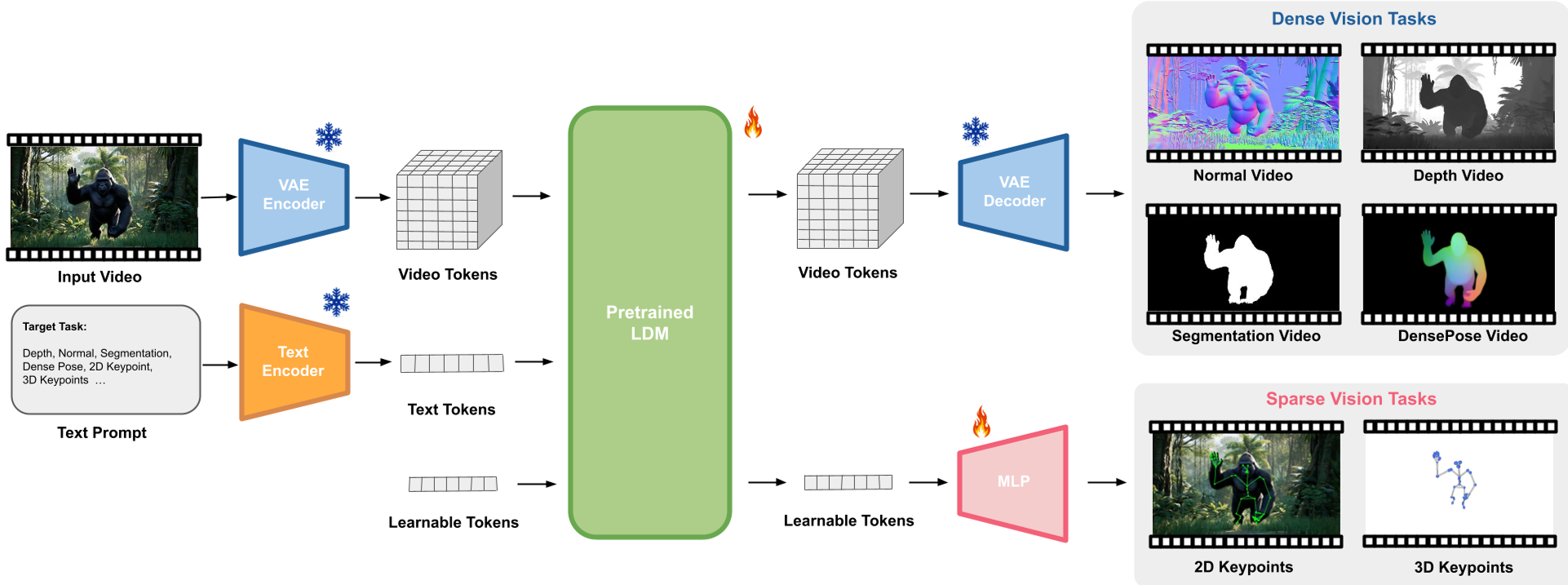
Methodology: The Architecture of THFM
THFM utilizes a Latent Diffusion Model (LDM) backbone, specifically the WAN architecture. The workflow involves two clever architectural "hacks":
- Unified Ambient Space for Dense Tasks: Tasks like depth and segmentation are mapped to the RGB space. For example, the 3-channel output represents (x, y, z) components for normals or repeated channels for depth.
- Learnable Tokens for Sparse Tasks: Since keypoints can't easily be "painted" as pixels, the authors append learnable tokens to the video latents. These tokens use 3D RoPE (Rotary Positional Embeddings) to stay spatially and temporally aware, allowing a simple MLP head to regress 3D coordinates.
Two-Stage Training Recipe
- Stage 1 (Latent Space): Efficiently training on compressed latents using MSE loss.
- Stage 2 (Ambient Space): Fine-tuning through the VAE decoder to apply high-resolution, task-specific losses (like scale-and-shift invariant depth loss) directly on pixels.
Experiments: Dominating the Human-Centric Benchmarks
Despite never seeing a real-world training image, THFM wipes the floor with models trained on real data.
- Surface Normals: THFM achieves an angular error of 11.01° on Hi4D, outperforming Sapiens-2B (12.14°), which was pre-trained on massive real-world datasets.
- 3D Pose: It sets a new benchmark on EMDB with an MPJPE of 68.7mm, proving that the temporal consistency of the video backbone significantly reduces "jitter" in 3D reconstructions.
Emergent Behaviors: The "Wow" Factor
The most striking part of the research is what the model learned "for free":
- Zero-Shot Multi-Person: Trained only on single humans, it correctly identifies and segments multiple people in complex real-world videos.
- Cross-Category Generalization: It can estimate the depth and normals of a panda or a cartoon character, despite only being trained on synthetic humans. This suggests the model has learned a general "articulated object" prior.

Critical Analysis & Future Outlook
While THFM is a major step forward, the authors admit a slight "multi-task penalty"—performance drops slightly when sparse and dense tasks are trained together (Ablation Table 2). Solving this multi-objective optimization conflict is the next frontier.
Conclusion: THFM demonstrates that the next generation of perception models won't be built from scratch; they will be "distilled" from the massive world-knowledge locked inside video generative models.
Takeaway for Practitioners
- Stop worrying about real-world labels; high-quality synthetic data + a strong generative prior is the new SOTA recipe.
- Single-step diffusion is fast enough for near-real-time production pipelines.