本文推出了 THFM,这是一个基于预训练视频扩散模型(Text-to-Video Diffusion)构建的统一视频感知基础模型。它通过单一架构同时处理密集型任务(深度、法线、分割)和稀疏型任务(2D/3D 关键点),在仅使用合成数据训练的情况下,在多个 4D 人体感知基准测试中达到或超越了专门定制的 SOTA 模型。
TL;DR
来自 Google DeepMind 的研究团队推出了 THFM (Unified Video Foundation Model)。它跳出了“一个任务一个模型”的传统怪圈,将预训练的文本-视频生成模型(WAN)改造成了一个全能感知器。只需给出一个文本指令(如 "surface normal"),模型就能在一次前向计算中输出整段视频的深度、法线、分割掩码,甚至是 3D 人体骨架。最令人惊讶的是:它完全在合成数据上训练,却在真实世界评估中碾压了许多用真实数据训练的专用模型。
背景定位:从“生成”到“感知”的华丽转身
在 CV 领域,我们习惯了用特定的 ResNet 或 ViT 去跑特定的任务。然而,性能强大的视频扩散模型(Video Diffusion Models, VDM)为了生成逼真的视频,其实早已在潜意识里学习到了世界的几何结构、光影变化和物体运动规律。
THFM 的核心直觉在于:如果你能生成一段完美的人体运动视频,那你必然已经感知到了人体的骨架和深度。作者的目标就是将这些隐性知识显性化。
痛点深挖:通用视频感知的难题
- 时序一致性:单帧模型处理视频时,帧与帧之间往往会像闪烁的霓虹灯一样不连贯。
- 数据匮乏:真实世界中很难获得带精准 3D 标注或深度图的视频。
- 模态异构:如何让同一个网络既能输出像素级的图片(密集任务),又能输出几十个坐标点(稀疏任务)?
核心架构:模型结构详解
THFM 基于 DiT (Diffusion Transformer) 架构。它抛弃了扩散模型昂贵的迭代去噪过程,将其简化为单步确定性推理(Single-step Inference)。

1. 统一的 RGB 环境空间 (Ambient Space)
对于密集感知任务(深度、法线、分割),THFM 将它们全部规范化到 RGB 图像空间。这意味着模型像在“画”出一张法线图或深度图。作者发现,直接在解码后的图像像素级(Ambient Space)施加监督,比在压缩的潜空间(Latent Space)训练效果要精细得多,尤其是在处理头发和衣物褶皱等细节时。
2. 用于稀疏任务的可学习 Token
为了解决 2D/3D 关键点预测,THFM 引入了额外的 learnable tokens。这些 Token 像导游一样,通过 3D RoPE(旋转位置编码)感知视频的时空分布,最后经过一个简单的 MLP 喷射出关键点坐标。这种设计完美兼容了 DiT 的原生注意力机制。
实验战绩:合成数据的逆袭
THFM 的训练完全依赖于用 Blender 制作的 20,000 段合成视频(利用 RenderPeople 资产)。
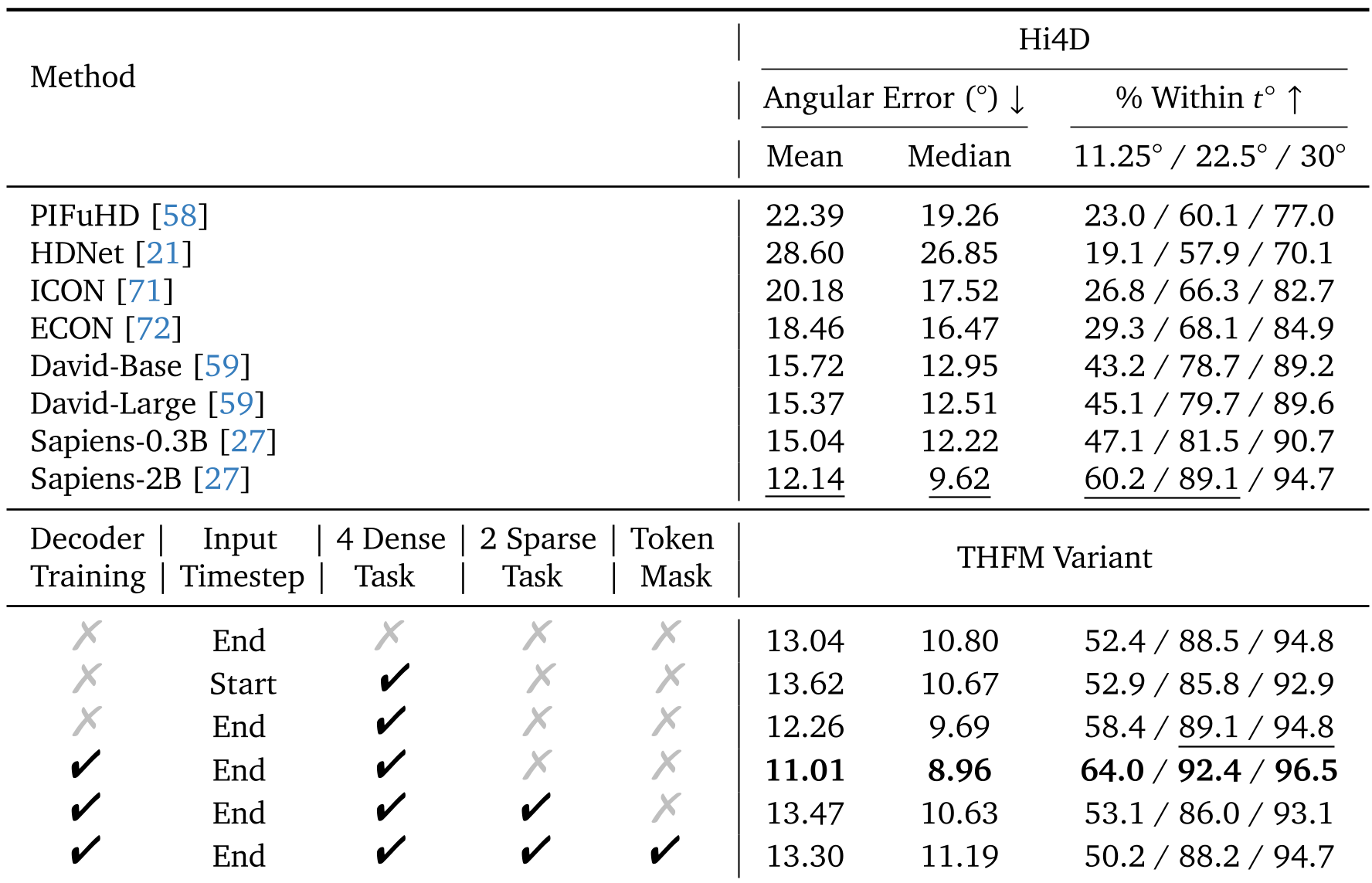
在 Hi4D 和 Goliath 等严格的真实世界基准测试中:
- 法线估计:误差(Median Error)仅 8.96°,优于参数量巨大的 Sapiens-2B。
- 3D 姿态估计:在 H3.6M 数据集上,MPJPE 达到 38.3mm,创下新纪录。
- 时序平滑度:由于原生继承了 VDM 的时序建模能力,其产生的深度图和关键点序列在视觉上极其稳定。
深度洞察:突现的泛化能力 (Emergent Behaviors)
这是本文最“硬核”的部分:
- 分类跨越:模型训练时只看过了合成的“人类”,但在测试时,它能完美识别出动画片里的拟人角色,甚至是穿衣服的猴子和猫。这说明视频扩散模型学习到的是一种通用的几何逻辑。
- 多目标泛化:训练数据全是单人,但测试时面对多人滑雪场景,模型能自动适应,表现出极强的鲁棒性。

总结与未来展望
THFM 标志着视频理解进入了一个新阶段:生成即感知。它证明了利用合成数据在大模型时代并非“走捷径”,而是通过提供无限的高质量监督信号,去激活预训练模型中沉睡的感知潜力。
尽管目前在一个模型里强行塞进所有任务(Dense + Sparse)会导致轻微的性能下降(可能是任务冲突),但这为未来构建真正的“视觉通用智能(Generalist Vision System)”指明了方向。