This paper introduces Sig2GPS, a novel framework that treats GPS trajectory reconstruction from coarse cellular signaling as an image-to-video generation task. By fine-tuning the Wan2.1-5B video model and applying a trajectory-aware RL method (Traj-GDPO), the system transforms signaling footprints on maps into continuous, road-constrained GPS paths.
Executive Summary
TL;DR: Reconstructing precise GPS movement from coarse cellular signaling (base station pings) has long been a "black art" of multi-stage engineering. This paper flips the script by framing Sig2GPS as a video generation task. By teaching a model to "draw" a trajectory on a map tile, the authors leverage the spatial reasoning of video models like Wan2.1 to outperform traditional coordinate-based regression and industrial pipelines.
Background: Historically, trajectory mining has been treated as a Sequence-to-Sequence problem (coordinates at time $T$). This work represents the first successful attempt to move reasoning into the Map-Visual Domain, treating the map not just as a feature, but as the canvas for generation.
Problem & Motivation: The "Coarse" Reality of Signaling
Cellular signaling records are ubiquitous but frustratingly imprecise. They tell you which tower a phone talked to, but not where the user actually was.
- The Pipeline Hell: Current industrial solutions involve "Ping-pong" effect mitigation, Kalman filtering, and complex map-matching. These pipelines are slow and break easily in different cities.
- The "Human" Intuition: Human experts don't look at coordinate strings; they overlay dots on a map and sketch a path that follows the roads. Previous AI models (like GRUs or Transformers) struggled to capture this "map-aware" logic because they lacked the visual grounding of road topology.
Methodology: The "Think Over Trajectory" Paradigm
The core innovation is treating the GPS path as a dynamic video overlay.
1. Image-to-Video Transformation
The input is a Conditioning Image: a map tile with the signaling trace rendered as a polyline. The output is a 21-frame video where a blue dot "draws" the fine-grained GPS path over time. This forces the model to learn the underlying road network's constraints implicitly.
2. Traj-GDPO: Reinforcement Learning from Verifiable Rewards
While Supervised Fine-Tuning (SFT) gets the "look" right, it often makes physical errors (e.g., wrong turns at junctions). The authors introduce Traj-GDPO (Trajectory-aware Group Decoupled Policy Optimization) to align the model with three verifiable rewards:
- Distance: Keeps the generated points close to ground truth.
- Direction: Ensures the path goes from A to B, not B to A.
- Continuity: Penalizes "ghosting" or broken lines (enforcing $C=1$ connected components).
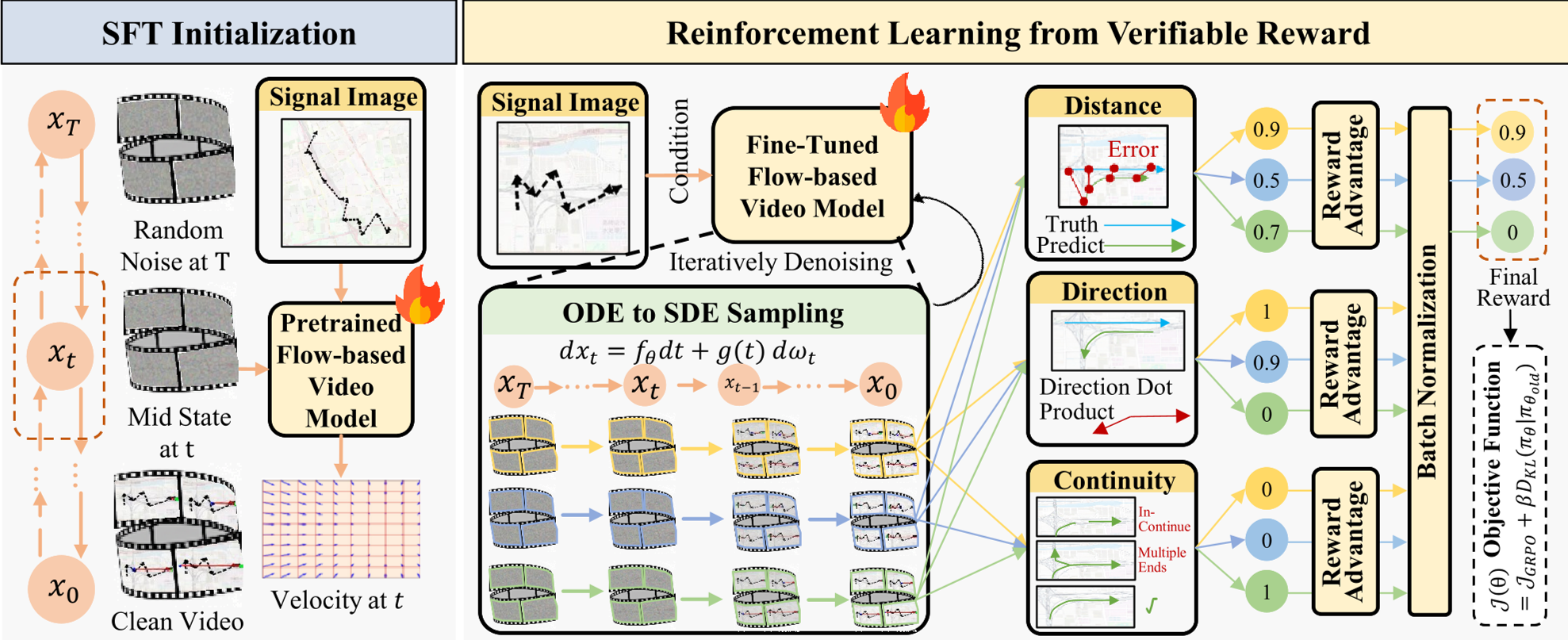 Figure: The framework leverages SFT followed by RLVR to ensure map-consistent generation.
Figure: The framework leverages SFT followed by RLVR to ensure map-consistent generation.
Experiments: Speed and Accuracy
The results on real-world datasets from Beijing are striking. Compared to Rule_sig (the production-grade industrial pipeline), the video-generation approach is not only more accurate but significantly faster.
Key Performance Metrics:
| Scope | MAE (Ours) | MAE (Rule_sig) | L100 (Ours) | |---|---|---|---| | Small | 214.96m | 306.12m | 36.71% | | Large | 441.10m | 516.80m | 15.24% |
Inference Speed: The one-step generation takes <30 seconds, while the traditional pipeline drags on for over 2 minutes.
Test-Time Scaling
One of the most interesting findings is Test-Time Scaling. By increasing the number of generated frames (from 13 to 21), the model's error (MAE/RMSE) consistently drops. This suggests the model actually "thinks" harder and utilizes more temporal context when given more generation budget.
 Table: Comparison across different trajectory scopes shows the robust advantage of the generative approach.
Table: Comparison across different trajectory scopes shows the robust advantage of the generative approach.
Critical Analysis & Conclusion
The Takeaway: Scaling laws are moving into domain-specific reasoning. By shifting from coordinate regression to visual generation, we allow models to inherit the spatial "common sense" baked into their pre-trained vision weights.
Limitations:
- Sparse Signaling: The model's performance might degrade in areas with extremely low tower density (rural areas).
- Map Style Sensitivity: If the map tile style (OSM) changes drastically, the model might require re-alignment.
Future Outlook: The "Think Over Trajectory" paradigm could soon be applied to Autonomous Driving (path planning) or Indoor Navigation, where visual constraints are just as critical as numerical accuracy. As video models become more efficient (via Distillation or Quantization), we could see real-time "visual GPS" reconstruction on-device.