The paper introduces a "Depth-Recurrent Transformer" that implements "Vertical Chain-of-Thought" (VCoT) by iteratively applying a shared-weight Transformer block in latent space. This architecture decouples computational depth from parameter count and token length, achieving SOTA compositional generalization on graph, logic, and relational tasks.
TL;DR
While the industry focuses on "Horizontal CoT" (generating more tokens to think), this paper proposes Vertical Chain-of-Thought (VCoT). By recurrently passing data through the same Transformer block in latent space, the model "thinks deeper" without consuming context windows or increasing parameter counts. This approach solves complex compositional tasks with near-perfect OOD generalization.
The "Fixed Depth" Bottleneck
In standard Transformer architectures (like GPT-4 or Llama), the computational budget is "baked in." A 32-layer model applies exactly 32 layers of processing to every token, whether the task is a simple "Hello" or a complex mathematical proof. To do more work, models currently rely on generating more tokens—a process that is slow, expensive, and limited by the context window.
The authors argue that this is fundamentally inefficient. We need models that can decide to spend more internal "thinking cycles" on harder problems without externalizing every thought as a word.
Methodology: The Architecture of Latent Reasoning
To make a Transformer block stable over 20+ recurrent steps—a feat that usually leads to gradient explosions or representation collapse—the paper introduces a trifecta of stabilization techniques:
- Silent Thinking: The model is only told if its final answer is right. By removing intermediate supervision, the model is forced to learn a robust internal algorithm instead of taking "shortcuts" to satisfy per-step losses.
- LayerScale Initialization: By initializing sub-layers with a tiny scale ($10^{-4}$), the model effectively starts as an identity mapping. This creates a "safe space" for signals to pass through while the model slowly learns to activate its reasoning logic.
- Identity-Biased Gated Recurrence: Using a GRU-like gate with a negative bias (-2.0) ensures that at the start of training, the model defaults to remembering its previous state, creating a Temporal Gradient Highway.
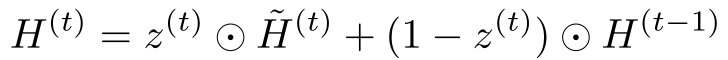
Discovering the "Computational Frontier"
The most striking finding is the Computational Frontier. In tasks like Graph Reachability and Nested Boolean Logic, there is a clear diagonal boundary: as the complexity of the problem increases, the model must increase its thinking steps to maintain accuracy.
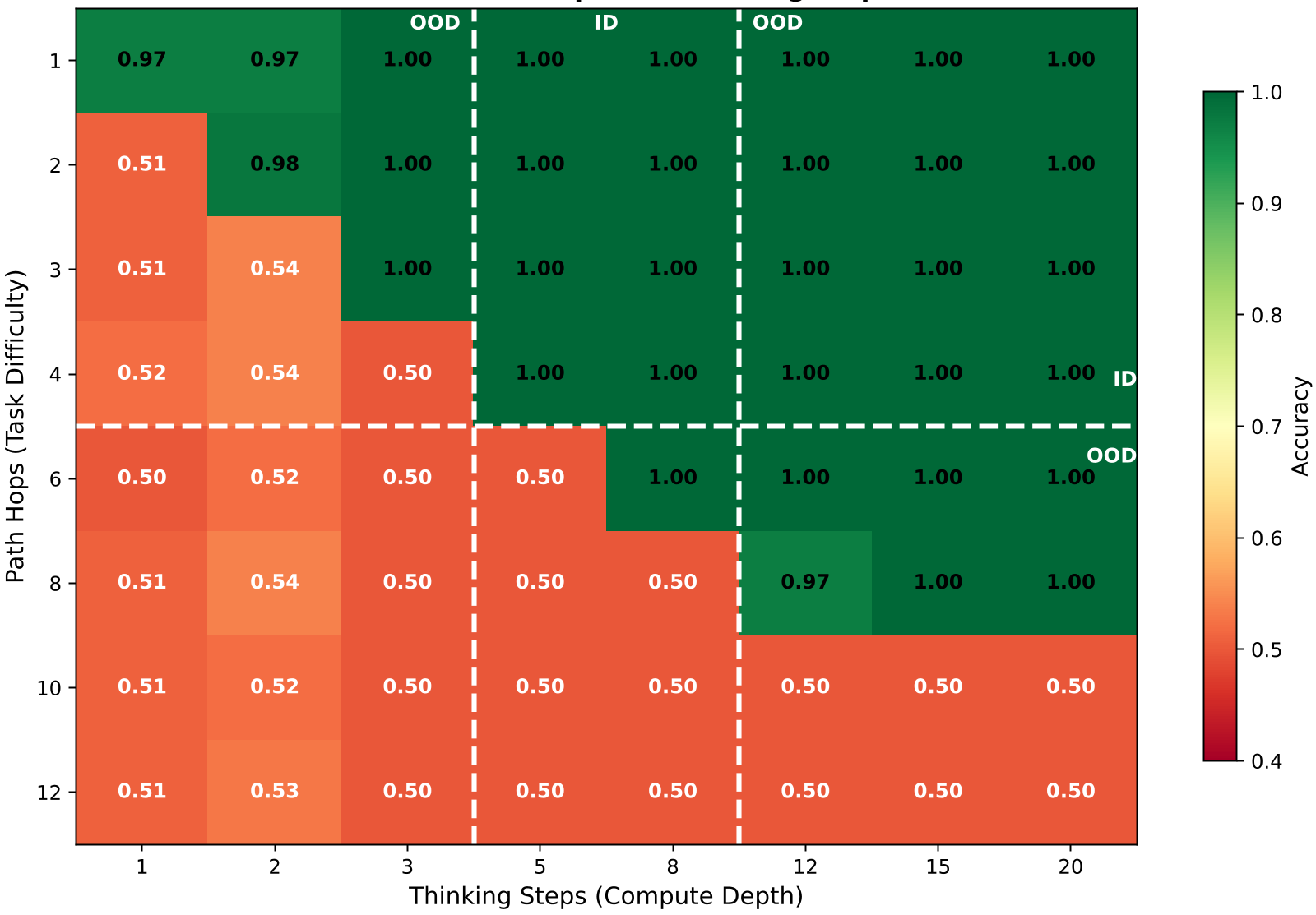
As seen in Figure 1, for a graph problem with $N$ hops, the model requires roughly $N$ thinking steps. Interestingly, if provided with more steps than necessary, the model remains stable—it doesn't "overthink" or degrade, thanks to the gated recurrence.
Why Intermediate Supervision is Poison
A key contribution of this work is the critique of intermediate supervision. The authors show that when you supervise every step of a recurrent model, it learns to "cheat." For example, in graph tasks, the model starts guessing reachability based on graph density (a heuristic) rather than actually traversing the nodes (an algorithm). Silent thinking prevents this "bandwidth occupation" and forces the emergence of genuine multi-step logic.

Insights & Future Outlook
This paper proves that we don't always need more parameters or more tokens to solve harder problems—we need more depth.
- Precise vs. Robust: The model behaves differently depending on the "perception interface." With hard masks (graphs), it is precise but brittle; with relative positions (logic), it is approximate but robust.
- Autonomy: In unstructured text tasks, the model autonomously discovered pointer-chasing routes without any structural help from the input format.
The Takeaway: Vertical CoT represents a shift from "Scaling Laws of Parameters" to "Scaling Laws of Latent Compute." For the next generation of LLMs, the ability to "pause and think" internally for an arbitrary number of cycles might be the key to matching human-level reasoning.