本文提出了 Depth-Recurrent Transformer,这是一种通过在隐藏空间(Latent Space)循环调用共享参数的 Transformer 块来实现“垂直思维(Vertical CoT)”的新型架构。该模型通过在推理时增加循环步数,成功在不增加参数量和 context window 消耗的前提下,实现了对复杂组合任务的跨分布(OOD)泛化。
TL;DR
传统的 Transformer 像是一条固定长度的流水线,无论问题难易,处理步数都是恒定的。本文提出了 Depth-Recurrent Transformer,它不再通过水平增加生成的 Token(Horizontal CoT)来思考,而是通过在**隐藏空间(Latent Space)**反复循环同一个 Transformer 模块来加深推理深度(Vertical CoT)。这意味着模型可以在不扩充参数量的情况下,通过在推理时多跑几圈循环,解决比训练时更难的逻辑问题。
背景定位:从水平扩张到垂直深挖
目前 LLM 的主要推理手段是 Chain-of-Thought (CoT),这本质上是将推理过程“外部化”为文本序列。但这种方式有三个致命伤:
- 上下文饥渴:每多想一步,就要多吃掉一个 Token 的位置。
- 深度固定:无论你是算 1+1 还是证费马大定理,32 层的模型永远只跑 32 层。
- 幻觉累积:中间步骤一旦写错,满盘皆输。
本文作者认为,真正的推理应该发生在模型的“潜意识”里。通过权重共享(Weight Sharing)和动态循环,模型可以根据任务难度,在原地进行多次迭代,实现真正的计算缩放。
核心动机与 Insight
作者观察到,很多组合性问题(如多跳图查询、嵌套逻辑)的本质是递归的。如果强制模型在固定深度下解决这些问题,它只能学到一些“统计捷径”,而非真正的“通用算法”。
为了让模型能够稳定地在隐藏层“思考”20 步以上,作者提出了三个至关重要的机制:
- Silent Thinking (宁静致远):不要在中间步骤加 Loss,只看最后结果。这防止了模型学会“投机取巧”去凑中间分,而是逼迫它构建完整的思维链路。
- LayerScale:将初始缩放设为极小的 ,让模型在训练初期几乎表现为恒等映射(Identity Mapping),保护脆弱的逻辑信号不被噪声淹没。
- Identity-Biased Recurrence:使用了类似 GRU 的门控,但初始偏置设为负值,让模型默认先“继承”上一层的信息。
架构拆解:可变深度的核心引擎
模型的逻辑非常清晰:通过一个**感知接口(Perception Interface)将输入转化为初始状态,然后进入不变推理核心(Invariant Reasoning Core)**进行 次迭代。
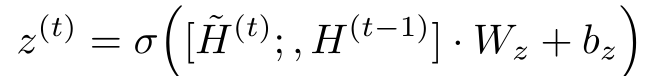 (公式展示了带有门控的隐藏状态更新过程)
(公式展示了带有门控的隐藏状态更新过程)
三种感知接口的博弈
- Topological Masking (强先验):在图路径任务中,直接给 Attention 矩阵套上邻接矩阵的“枷锁”,模拟 GNN 的消息传递。
- RoPE (中等先验):在布尔逻辑中,利用旋转位置编码处理嵌套关系。
- Unstructured Text (零先验):在最难的家谱关系任务中,模型必须在完全乱序的文本中,自己学习如何“路由”信息,找到逻辑指针。
实验发现:计算前沿 (Computational Frontier)
实验结果揭示了一个迷人现象:Accuracy Heatmap(准确率热力图)上存在一条清晰的对角线。
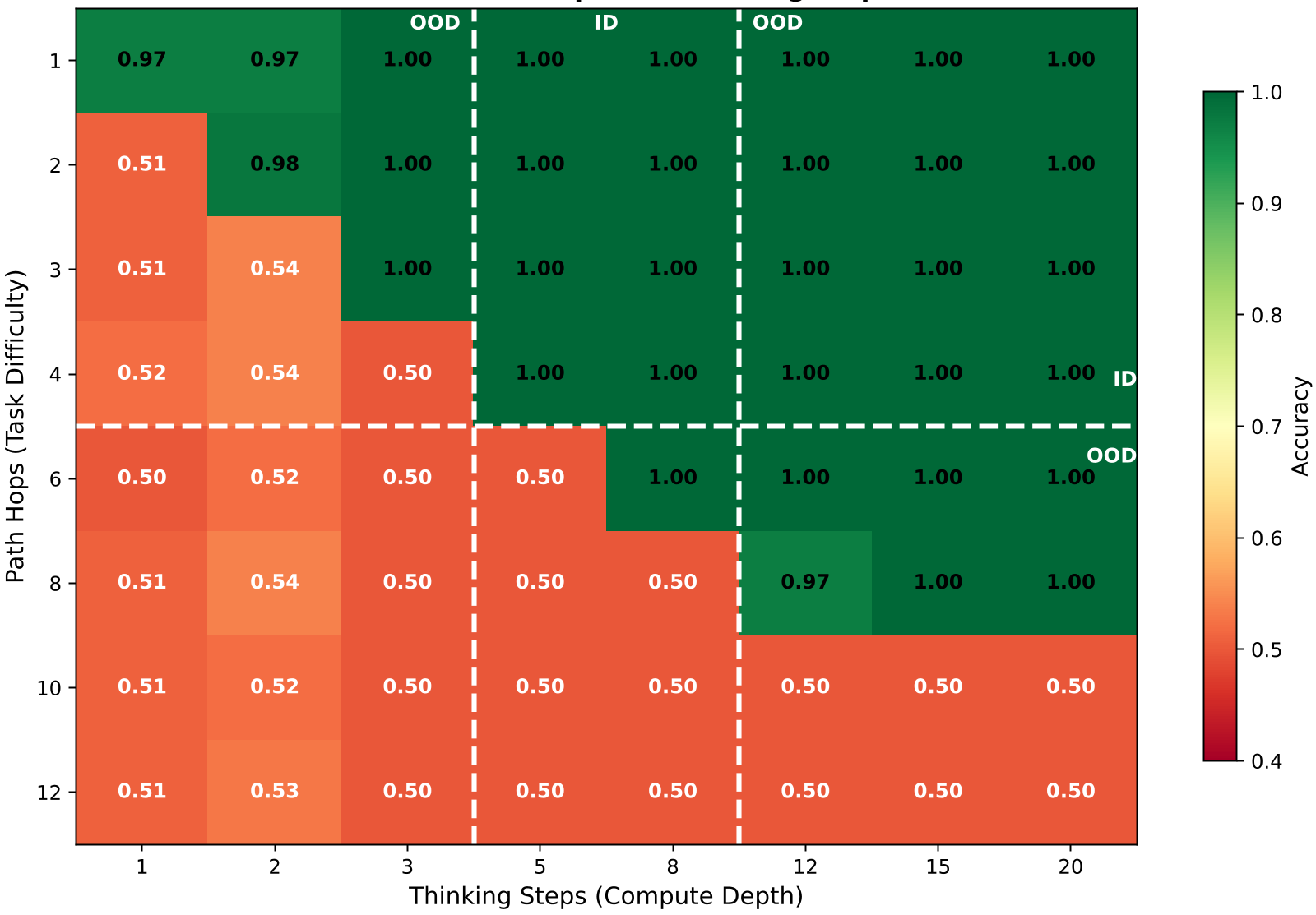 图 1:图可达性任务。可以看到明显的对角线,1 步思考解决 1 跳问题,步数不到则准确率直接归零。
图 1:图可达性任务。可以看到明显的对角线,1 步思考解决 1 跳问题,步数不到则准确率直接归零。
关键结论:
- 超越训练分布的泛化:即便训练时只见过 5-8 步的推理,模型在测试时通过增加到 20 步循环,能完美解决更高难度的 OOD 问题。
- 中间监督的陷阱:消融实验显示,如果你对中间每一步都进行 Loss 监督(Per-step Loss),模型会迅速学会“作弊”,通过统计密度预测结果,而非学习路径搜索。结果在面对 OOD 长路径时,表现会断崖式下跌。
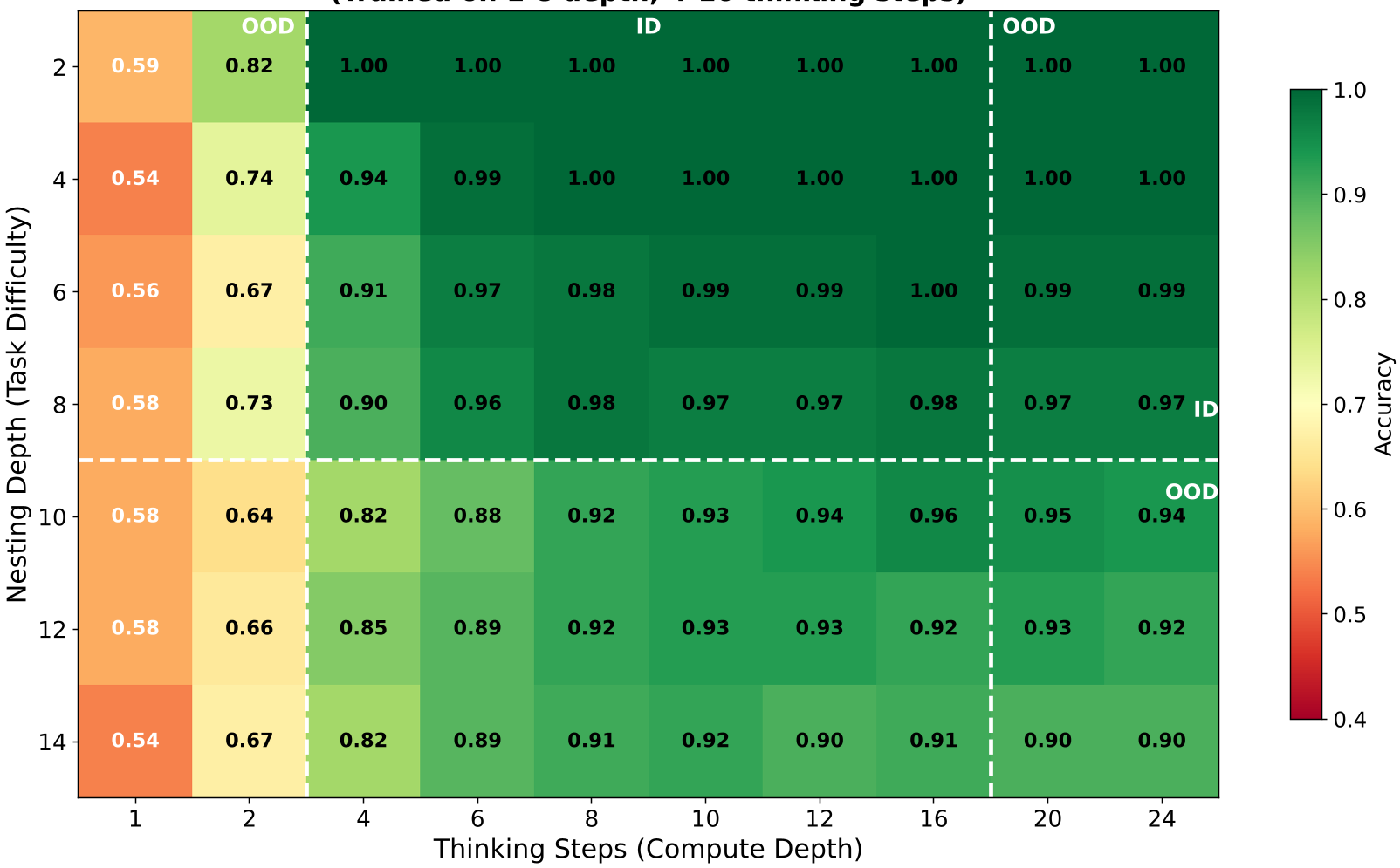 图 2:布尔表达式评估。展示了模型在推理步数超过训练上限(虚线)后的稳健性。
图 2:布尔表达式评估。展示了模型在推理步数超过训练上限(虚线)后的稳健性。
总结与未来展望
Depth-Recurrent Transformer 展示了 AI 推理的另一种可能:Vertical CoT 是对传统 Horizontal CoT 的强力补充。这种“原地思考”的能力,让模型能在有限的参数规模下,通过时间(计算量)换取逻辑深度。
局限性:目前实验主要在 1M 参数级的小模型上完成。 启示:未来的 LLM 可能会内置这种“思维循环”,当它感知到问题困难时,先在潜意识中循环思考 轮,再一击即中输出答案,而不是现在这样边写边想。
Takeaway: 真正的理解不是说得多,而是想得深。深度循环机制可能是通往通用算法推理(Neural Algorithmic Reasoning)的关键一步。