本文提出了 TiCo,一种简单的两阶段后期训练方法,旨在增强语音对话模型(SDMs)的时间控制能力。通过引入语音时间标记(Spoken Time Markers, STM),TiCo 使模型能够在生成过程中感知已用时间并调整回复长度,在 TiCo-Bench 测试中显著优于商业模型和级联系统。
TL;DR
在与语音助手交互时,你是否遇到过它“滔滔不绝”却无法按你要求精简回复的情况?MIT 与台大(NTU)推出的 TiCo (Time-Controllable Training) 框架,通过给模型植入一个“内置时钟”,让其掌握了精准控制回复时长的能力。TiCo 不仅在时控精度上大幅超越 GPT-4 级联系统,还具备极强的跨模态泛化能力。
背景:为什么语音控制比文本控制难得多?
在文本大模型中,控制字数(Length Control)已经很成熟。但在语音领域(SDMs),“控制 15 秒”是一个典型的 Hard Problem:
- 非线性关系:100 个单词在不同语速下可能是 10 秒,也可能是 20 秒。
- 声学变数:停顿、重音、音节构成都会剧烈改动实际时长。
- 缺乏反馈:传统模型在生成中间表示(Intermediate Representation)时,完全不知道这些内容转化成语音后会耗时多久。
核心机制:TiCo 的“两步走”策略
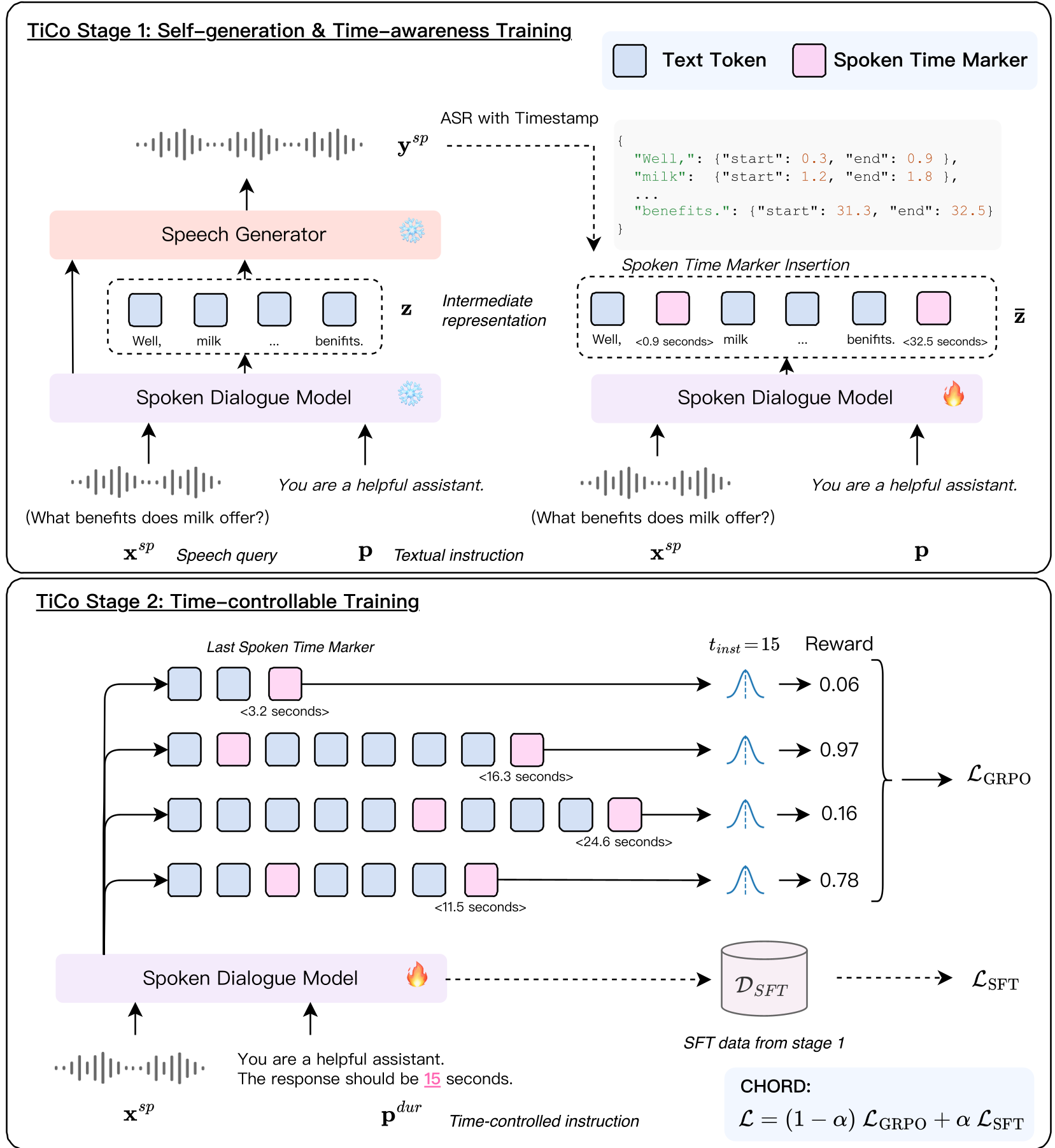
TiCo 并没有改变模型底层的声学合成器,而是改造了模型的“思考方式”。
1. 建立时间感知 (Time-Awareness)
作者引入了 Spoken Time Markers (STM)。在模型生成的中间文本中,每隔一段就会插入一个类似 <6.8 seconds> 的标记。
- 训练数据获取:利用模型自生成(Self-generation)语音,再通过 ASR 语音识别获得对应文本精确的时间戳。
- 意义:这让模型学会了“预估进度”。当它写下某句话时,它能预测到此刻已经过去了多少秒。
2. 精准对齐与强化学习 (RLVR)
有了感知还不够,还需要“执行力”。作者使用了 GRPO (Group Relative Policy Optimization) 强化学习算法。
- 奖励设计:如果生成的最后一个 STM 标记与目标时长(Instruction)越接近,奖励越高。
- 辅助约束:为了防止模型“作弊”(例如乱报时间或者重复说话),作者设计了单调性奖励和惩罚机制,确保时间戳逻辑自洽。
实验战绩:全方位超越级联系统
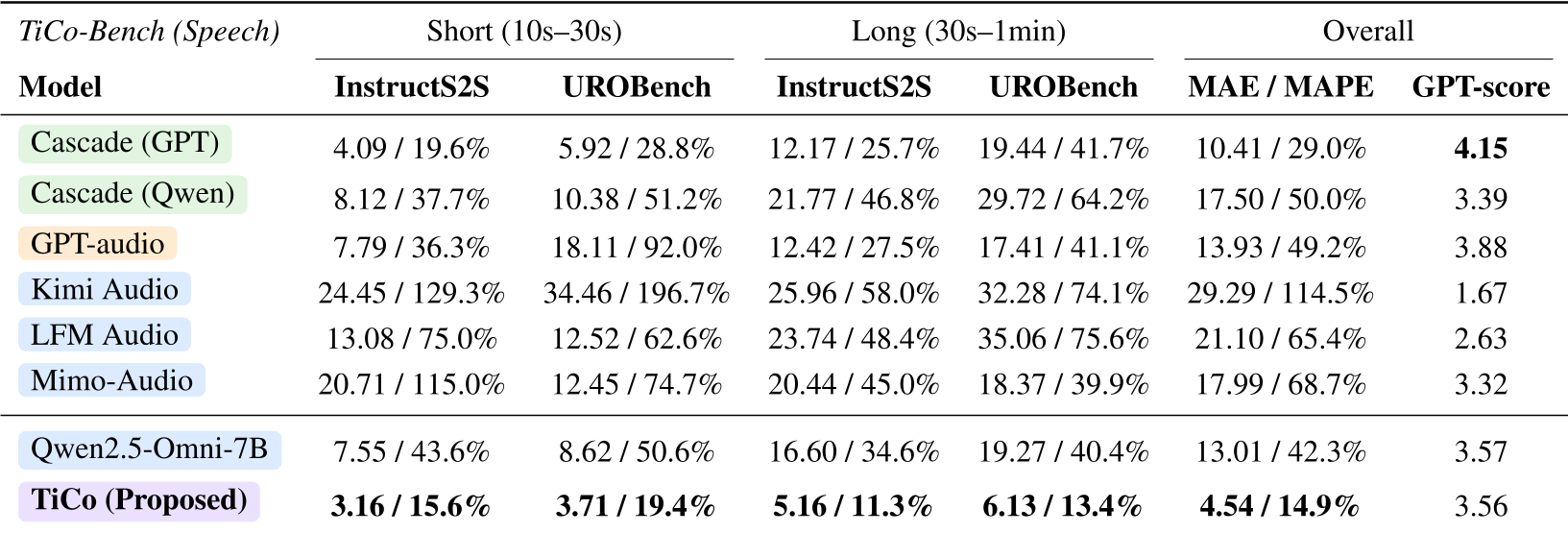
研究团队构建了首个语音时控基准 TiCo-Bench。结果显示:
- 精度飞跃:在短任务(10-30s)中,TiCo 的误差仅为 3.16s,而最强的 Cascade (GPT) 级联系统误差为 4.09s,普通的 Qwen2.5-Omni 误差则高达 7.55s。
- 跨模态泛化:虽然 TiCo 只在“语音输入”上训练,但在“文本输入”测试中(如由文本提问要求语音回答),其 MAE 依然领先,证明了时间控制已内化为一种通用的推理能力。
深度洞察:它是如何“偷时间”的?
通过对生成结果的定性分析(Qualitative Analysis),我们发现 TiCo 学会了人类的沟通技巧:
- 针对短时间目标:模型会变得直击主题,语感简洁。
- 针对长时间目标:模型并不会单纯放慢语速(那会很奇怪),而是会动态增加内容密度——增加背景解释、补充细节或增加结尾引导。
例子:回答“大海有多深?”
- 目标 15s:它会直接告诉你马里亚纳海沟的深度和平均深度。
- 目标 40s:它在说出深度的基础上,会额外解释为什么不同海域深度不同,并询问你是否想了解更多。
总结与未来展望
TiCo 的成功不仅在于它解决了语音时长控制的问题,更在于它展示了一种**“带约束的语义规划”**能力。这种将不可见的物理约束(时间)转化为可见的符号序列(STM)的方法,可以很容易地推广到其他多模态领域。
局限性:目前 TiCo 仍依赖于 intermediate representation(Thinker-Talker 架构),对于完全端到端、无中间文本的语音模型,如何插入此类感知标记仍是一个挑战。
启示:
对于开发者而言,TiCo 提供了一个低成本(仅需少量数据)为现有大模型增加特定属性控制的有效路径——感知先行,强化跟随。