本文揭示了视觉语言模型 (VLM) 存在“选择性失明”现象,即模型对图像的关注程度受问题提问方式(Framing)的影响。研究提出了一种基于可学习 Token 的轻量级提示微调方法(Prompt-tuning),旨在对齐不同提问框架下的注意力模式,显著提升了模型在 Qwen, Gemma, LLaVA 等 SOTA 模型上的视觉扎根能力和性能一致性。
TL;DR
最近的研究发现,视觉语言模型(VLMs)不仅对图像理解存在局限,更表现出了惊人的“选择性失明”。本文研究表明:提问的方式(Question Framing)直接决定了模型“看”图像的认真程度。 当你把一个开放式问题(Open-ended)改成判断题(Yes/No)或多选题(MCQ)时,模型对关键视觉区域的注意力会骤减 40% 以上。本文提出的“注意力对齐”技术,通过几枚可学习 Token,成功治愈了这种由“框架效应”引起的视觉失效。
1. 痛点:模型不是看不见,而是“不想看”
在学术界,VLMs(如 LLaVA, Qwen-VL)常被诟病过度依赖文本偏见(Language Prior)。以往开发者认为这是模型架构或预训练数据的静态缺陷。但本文作者发现了一个动态的阴谋:
- 语义等价,视觉不等价:问“图中狗是什么颜色?”和问“图中的狗是棕色的吗?”,模型需要的视觉推理是一样的。
- 注意力塌陷:实验显示,在面对判断题和多选题时,VLMs 会显著减少对图像 Token 的能量分配,转而盯着那些无意义的“Sink Tokens”(如背景或空白区域)。

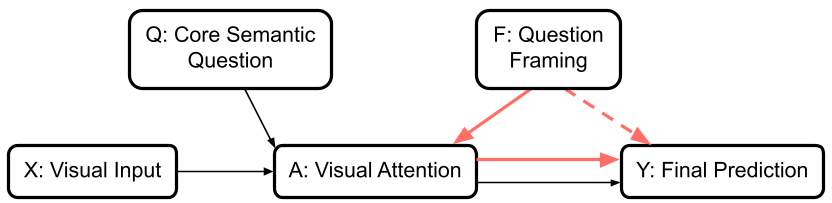
2. 深度机理:F → A → Y 的因果链路
作者提出了一个核心假设:Framing (提问框架) → Attention (注意力分布) → Yield (预测准确率)。
- F → Y (结果层):作者发现,即使模型在开放式提问下答对了,改为判断题后竟然有 15%-20% 的概率改错。
- F → A (过程层):通过 Attention Rollout 技术追踪信息流,研究发现受限提问会导致模型在中间跨模态交互层(Middle Layers)发生视觉能量流失,注意力变得发散且无序。
- A → Y (因果层):作者进行了一个精妙的干预实验——Attention Steering。手动强行把判断题下的注意力图恢复到开放式提问的水平。结果显示:准确率立马回升!这实锤了“提问框架导致的预测失败,本质就是注意力分配错了”。
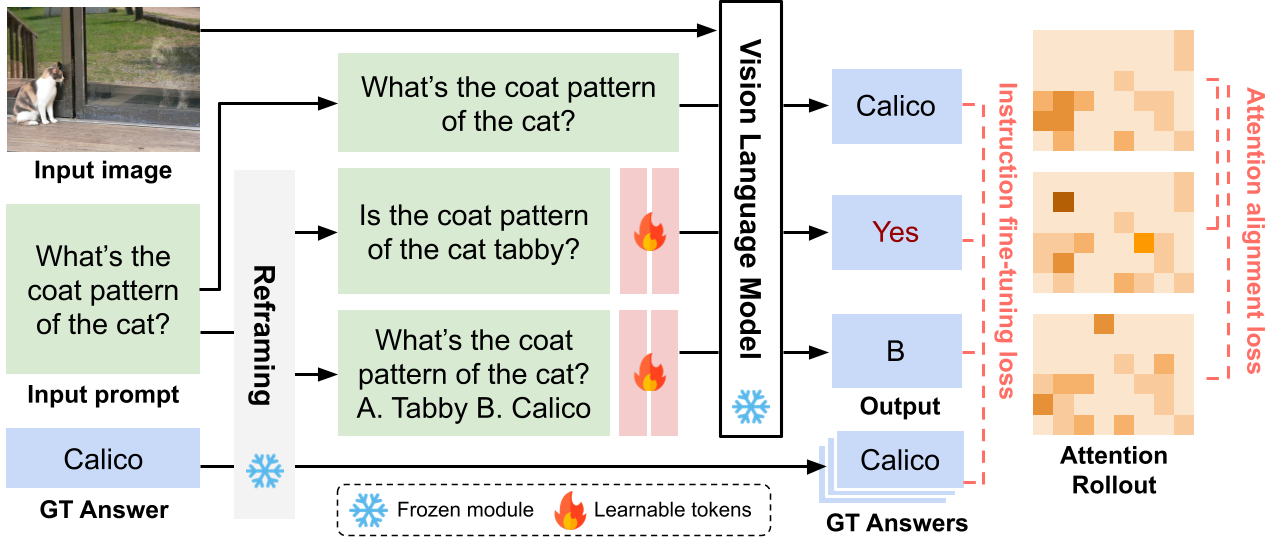
3. 核心方案:基于 Prompt-Tuning 的注意力对齐
既然病根在“框架”导致注意力跑偏,那能不能用一种轻量级的方式把它“拽”回来? 作者引入了 Learnable Soft Tokens (通常为 8 个):
- 对齐训练:让判断题/多选题生成的注意力图去拟合(Mimic)同一个问题在开放式模式下的注意力图。
- 损失函数组合:
- L2 Loss:约束视觉能量的总量(让模型看够图像)。
- KL Divergence:约束空间分布(让模型看对地方)。
- 置信度加权:只学习模型有把握答对的样本,保证监督信号的质量。
4. 实验战绩与洞察
该方法在 Qwen2.5-VL, Gemma3, GLM4.1V 等多个顶级模型上进行了验证:
- 视觉扎根提升:在对视觉定位要求极高的 V* 榜单上,性能稳步提升 2.5% 以上。
- 一致性显著增强:物体计数和空间关系任务中,跨提问方式的一致性大幅改善。
- 可视化证据:对比 Diff Map 可以清晰发现,微调后的模型在处理判断题时,注意力重新聚拢到了物体所在的 Bounding Box 内,而不再是“漫无目的地漂移”。

5. 资深主编点评 (Takeaway)
这篇论文的价值在于它打破了“模型能力=模型权重”的迷思。它告诉我们,当前的 VLM 依然像一个“偷懒的学生”:如果问题太容易(如判断题只有两个选项),它就会选择闭上眼睛凭直觉(文本先验)瞎猜。
对研究者的启示:在评估 VLM 能力时,多选题和判断题的 Baseline 很可能低估了模型的真实视觉潜力。通过轻量级的提示工程对齐注意力分布,是未来提升多模态模型鲁棒性的一个极具性价比的方向。
局限性:目前该研究主要集中在基于 Transformer 的主流架构,对于像 Mamba-based VLM 这种非全注意力模型是否同样存在这种“框架敏感性”,仍待进一步探索。