本文提出了 TokenGS,一种基于 Transformer 架构的 3D Gaussian Splatting (3DGS) 前馈重建方法。该方法通过引入可学习的 Gaussian Tokens 和直接 3D 坐标回归机制,实现了 3D 基元预测与输入图像分辨率的解耦,在静态与动态场景的重建质量及效率上均达到了 SOTA 水平。
TL;DR
TokenGS 是一篇来自 NVIDIA 的重磅工作,它打破了当前 3D Gaussian Splatting (3DGS) 前馈重建模型中“一个像素对应一个高斯”的固有模式。通过引入 Learnable Tokens 和 直接 3D 坐标回归,TokenGS 实现了基元数量与输入分辨率的解耦。不仅显著提升了对位姿噪声的鲁棒性,还在动态场景重建和测试时缩放(Test-Time Scaling)上展现出惊人的潜力。
痛点深挖:像素对齐的代价
目前主流的 3DGS 前馈模型(如 GS-LRM, DepthSplat)大多遵循一种“像素对齐”的直觉:将输入图像的每个像素(或 Patch)投影为 3D 空间中的一个高斯点。通过预测深度值,将点锚定在相机射线上。
这种设计虽然直接,但存在三大硬伤:
- 冗余性灾难:如果你有 32 张 512x512 的图,模型会产生超过 800 万个点。而实际上场景复杂度可能根本不需要这么多点。
- 几何僵化:点只能在射线上平移,这导致模型对相机的位姿噪声(Pose Noise)及其敏感,且无法补全视野外的物体。
- 动态性困境:在 4D 视频重建中,物体在运动,固定在像素射线上的点很难自然地处理物体的时空形变。
Methodology:从“射线”中解放出来
TokenGS 的核心哲学是独立性。它抛弃了 Encoder-only 的架构,转向了类似 DETR 的 Encoder-Decoder 结构。
1. 核心架构:Gaussian Tokens
模型不再关心有多少像素,而是定义了 个可学习的 3DGS Tokens。
- Encoder:提取多视角图像特征。
- Decoder:Tokens 作为 Query,通过 Cross-Attention 从图像特征中采集所需信息。
- Output:每个 Token 吐出固定数量的高斯基元(例如一个 Token 产出 64 个高斯,总共 4096 个 Token)。
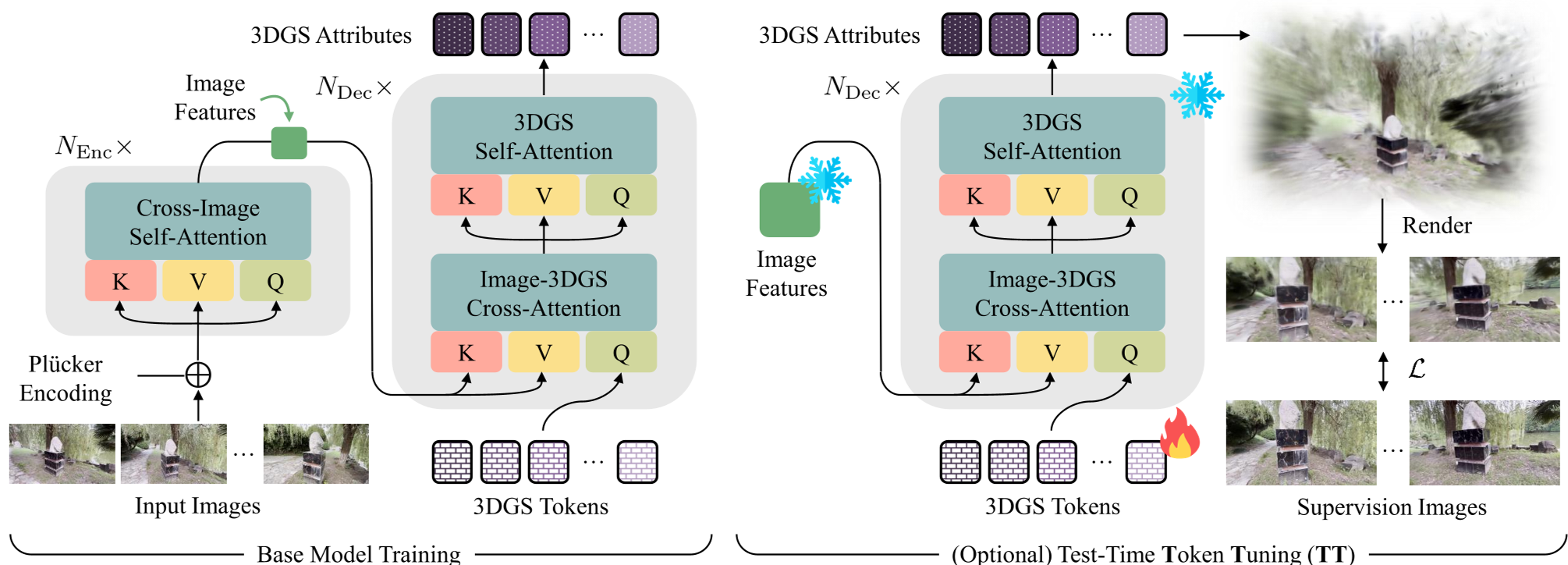
2. 坐标直接回归与 Visibility Loss
TokenGS 不再预测深度,而是直接预测 绝对坐标。为了解决“若高斯点不在相机视锥内则无梯度”的 0-gradient 问题,作者巧妙地引入了 Visibility Loss。它通过惩罚那些投影在所有已知视角之外的点,强制高斯基元分布在可见场景内。
3. 支持动态场景与场景流 (Scene Flow)
通过引入时间戳 Embedding,TokenGS 分离了静态 Token 和动态 Token,并施加因果掩码(Causal Masking),使得动态点能感知静态背景。这不仅实现了 4D 重建,还意外地产生了高质量的 Scene Flow(场景流自适应检测)。
实验与结果
在 RealEstate10K 等数据集上,TokenGS 即使只使用比基线少得多的高斯点,也能获得更好的 PSNR。
- 鲁棒性验证:当给相机位姿加入误差时,TokenGS 的性能下降远小于传统的像素对齐模型(如下表所示)。
- 测试时缩放 (TTS):在推理时,用户可以输入比训练时更多的视图,或者通过几步 Token Tuning 优化 Embedding,重建质量会稳步提升。
 上图展示了 TokenGS 如何消除像素对齐方法中常见的“尖刺”伪影,生成更规整的几何结构。
上图展示了 TokenGS 如何消除像素对齐方法中常见的“尖刺”伪影,生成更规整的几何结构。
深度洞察
TokenGS 的成功证明了 Inductive Bias(归纳偏置) 的重要性。传统的深度图预测赋予了模型太强的先验,但也成为了枷锁。TokenGS 相信 Transformer 本身具备从多视图相关性中推断 3D 空间关系的能力。
总结 (Takeaway): TokenGS 将 3D 重建从一种“图像处理”任务提升到了“基元生成”任务。它不仅快、稳,而且具备极强的灵活性(通过调整 Token 数量控制效果与开销的平衡)。
局限性 (Limitations): 目前对于超大规模环境(如城市级)的泛化能力仍有待验证。此外,Token Tuning 虽然有效,但每帧增加的计算开销对于实时性要求极高的场景仍是挑战。