本文提出了 TouchAnything,一个利用预训练 2D 视觉扩散模型作为几何先验,通过机器人稀疏触觉测量重建 3D 物体全几何结构的框架。该方法无需类别特定的触觉训练,在稀疏接触约束下实现了 SOTA 级的开源世界(Open-world)物体重建。
TL;DR
卡内基梅隆大学与清华大学的研究者提出了一种名为 TouchAnything 的新框架。它打破了触觉重建需要海量标注数据的僵局,通过将大名鼎鼎的 Stable Diffusion 用作“几何老师”,让机器人在只通过少量(Sparse)物理接触的情况下,就能脑补出物体完整的 3D 轮廓。即使在完全黑暗或遮挡的环境下,机器人也能靠着几下触摸重建出从未见过的相机、电钻或可乐罐。
背景定位:从“看”到“摸”的跨模态进化
在计算机视觉中,3D 重建通常依赖视角丰富的图片或深度图。但在机器人抓取或弱光环境下,视觉往往失效。触觉(Tactile Sensing)作为物理世界的“直接真相”,虽然真实但极其稀疏——你摸到了相机的镜头,但你无法知道它背后的屏幕长什么样。
传统方法往往通过训练“类别专属”的模型(比如专门学怎么重构瓶子的模型),这在面对开源世界(Open-world)中的多样物体时显得捉襟见肘。TouchAnything 的核心直觉是:2D 扩散模型在模仿亿万图片的过程中,已经深刻理解了什么是“合理的 3D 结构”。 如果能把这种 2D 先验迁移到触觉域,重建问题将迎刃而解。
痛点深挖:稀疏触觉的局部性 vs. 几何补全的全局性
触觉传感器(如 GelSight)只能提供触碰点的局部梯度和深度。
- 欠定挑战:只有几个点的约束,SDF(有符号距离函数)场有无数种解。
- 训练成本:直接在触觉数据上预训练生成模型需要极高的实验成本,且难以覆盖所有物体类别。
核心方法:TouchAnything 的两阶段炼金术
1. 触觉转视觉 (Deriving Local Geometry)
研究人员首先将 GelSight 传感器获取的图像,通过 U-Net 转换为局部深度图和法向图。随后,他们巧妙地将每次触摸点模拟为一个虚拟摄像机 (Virtual Camera),将触觉读数转化为具备空间位姿的视觉特征。
2. 第一阶段:粗糙几何优化 (Coarse Geometry)
采用 Neuralangelo 风格的哈希网格(Hash-grid)表示 SDF。
- 物理约束:强制模型生成的表面必须通过触摸点(Tactile Consistency)。
- 扩散制导:引入 Score Distillation Sampling (SDS)。通过随机采样视角渲染物体的法向图,并利用 Stable Diffusion 计算其与文本描述(如 "a camera")的语义偏离度,反向更新几何。
3. 第二阶段:精细细节修复 (Fine Refinement)
隐式 MLP 在高分辨率渲染时非常慢。研究团队在第二阶段将其转化为显式四面体网格 (DMTet)。
- 通过可微分光栅化技术,将渲染分辨率从 64x64 提升至 512x512。
- 利用扩散模型的高频先验,找回了如相机防滑纹理、牛油果粗糙表面的真实细节。
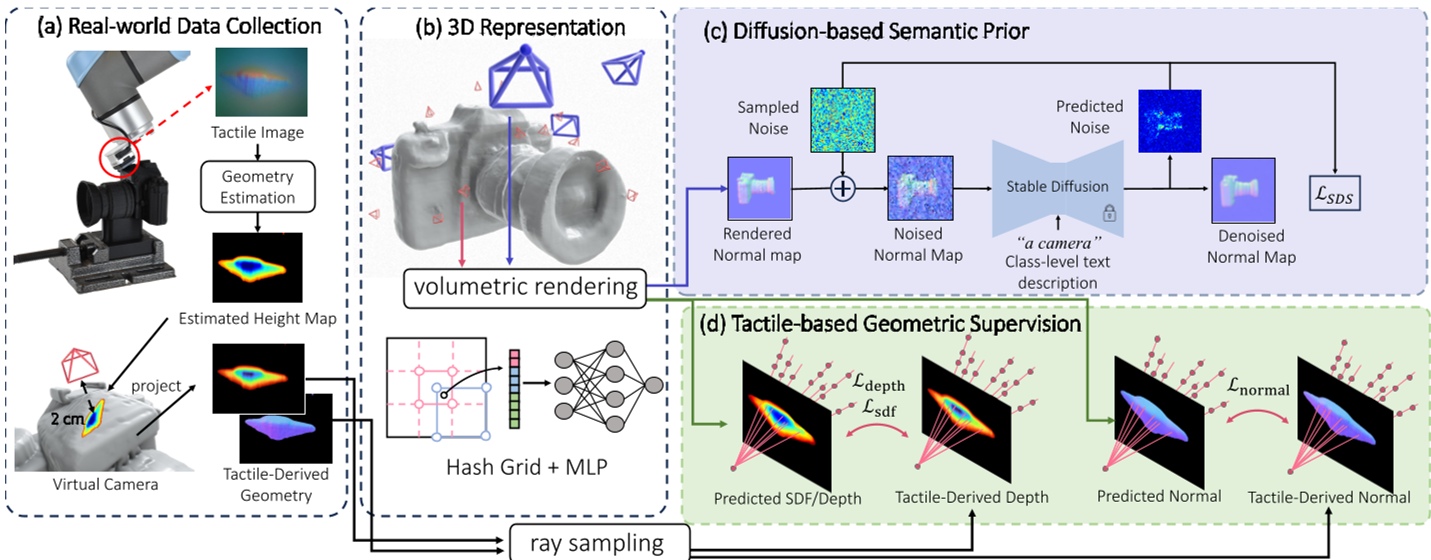 图1:TouchAnything 整体流程,展示了从触觉采集到扩散模型指导优化的闭环
图1:TouchAnything 整体流程,展示了从触觉采集到扩散模型指导优化的闭环
实验战绩:开源世界的泛化能力
在仿真实验(ShapeNet)中,TouchAnything 在瓶子、相机、吉他等多种类别上的 EMD(陆地移动距离)表现均显著优于传统的 TouchSDF。
关键发现:
- 提示词的力量:如果你给模型错误的提示(摸的是相机,告诉它是飞机),模型会产生“幻觉”,在没摸到的地方长出机翼。这反向证明了扩散模型作为几何先验的强大主导作用。
- 少即是多:实验显示,即使只有 20 次触摸,结合正确的类级别描述("a bottle"),也能重建出极其接近真实的形状。
 图2:真实世界中各种复杂物体的重建结果,包括手电钻、可乐瓶等
图2:真实世界中各种复杂物体的重建结果,包括手电钻、可乐瓶等
深度洞察:为什么这种迁移有效?
本文的本质突破在于理解了 Inductive Bias(归纳偏置) 的来源。传统的机器人任务试图从零学习物理属性,而 TouchAnything 借用了人类视觉经验的结晶。
- 视觉-触觉几何共性:物体的法向图(Normal Map)在视觉渲染和触觉深度图中具有一致的物理含义。
- 解耦设计:阶段二的 DMTet 显式表示极大地提升了渲染效率,使得 SDS 能够作用于高分辨率图像,这是获取“精细纹理”而不仅仅是“大块结构”的关键。
总结与局限
TouchAnything 成功将 Generative AI 的浪潮引入了机器人底层感知。
- 局限性:目前仍需人工提供简单的文本描述(Prompt),且重建耗时(约 1.5 小时)尚不支持实时动态环境。
- 未来展望:如果能结合主动学习(Active Learning),让机器人感知到“哪里还没搞清楚”并主动去触摸,重建效率将进一步质变。
致谢:本研究由 CMU, 清华, UIUC 等顶尖学府合作完成,展现了多模态感知与大模型结合的巨大潜力。