The paper introduces TextFlow, a training-free scene text editing (STE) framework that achieves high-fidelity text manipulation without task-specific fine-tuning or paired data. By integrating Flow Manifold Steering (FMS) and Attention Boost (AttnBoost), it establishes a new SOTA for training-free methods, reaching performance levels comparable to specialized training-based models.
TL;DR
Scene Text Editing (STE) has long been dominated by heavy, training-intensive models requiring millions of paired images. TextFlow changes the paradigm by offering a training-free framework that plugs directly into pre-trained Flow Matching models (like FLUX). By decoupling the process into style preservation and fine-grained rendering, it achieves SOTA visual quality and text accuracy without a single weight update.
The "Rigid" Reality of Prior Work
The field of STE has historically faced a binary choice:
- Training-based models (e.g., AnyText, DiffSTE): High quality, but "fixed" and computationally expensive. They struggle to generalize beyond their training distribution.
- Training-free methods (e.g., FlowEdit): Flexible but "blurry." They often lose the original font's identity or fail to spell complex words correctly because they treat text like any other object, ignoring its strict structural requirements.
The authors observed that the diffusion denoising process has different priorities at different stages. Early stages define the layout and style, while later stages define fine-grained details. Existing methods fail because they don't treat these phases differently.
Methodology: The Two-Phased Precision
TextFlow introduces a bi-phasic approach to stabilize the denoising trajectory.
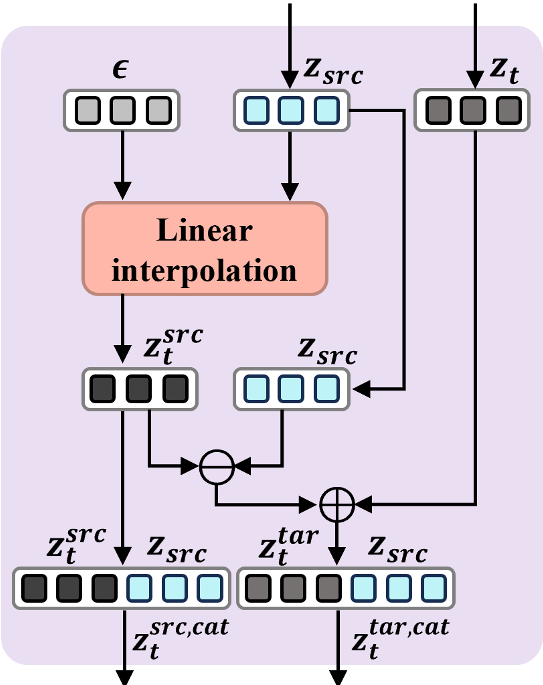
1. Style Preservation via Flow Manifold Steering (FMS)
In the early phase, the goal is to keep the "vibe" of the original image. FMS works by calculating a velocity field differential. It injects noise into the source image and measures how that noise moves the latent representation. It then applies this offset to the target generation, effectively "steering" the target latent toward the source's structural manifold.
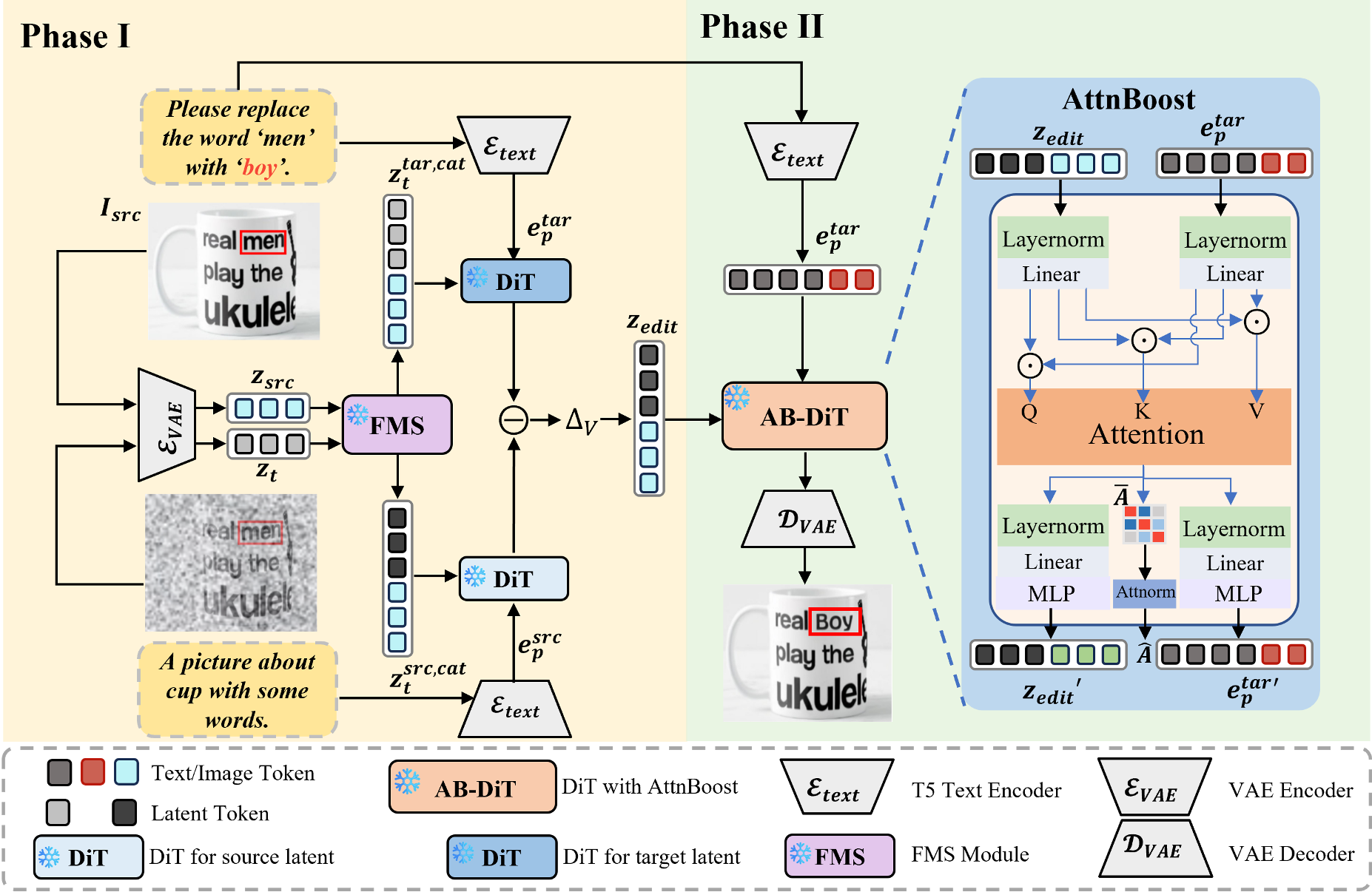
2. Strategic Rendering via AttnBoost
Once the layout is fixed, the "AttnBoost" mechanism takes over. It identifies text-to-image attention maps within the Transformer blocks. By dynamically amplifying these regions and using an Overshoot Scheduler, the model "pushes" the pixels harder toward the correct character glyphs.
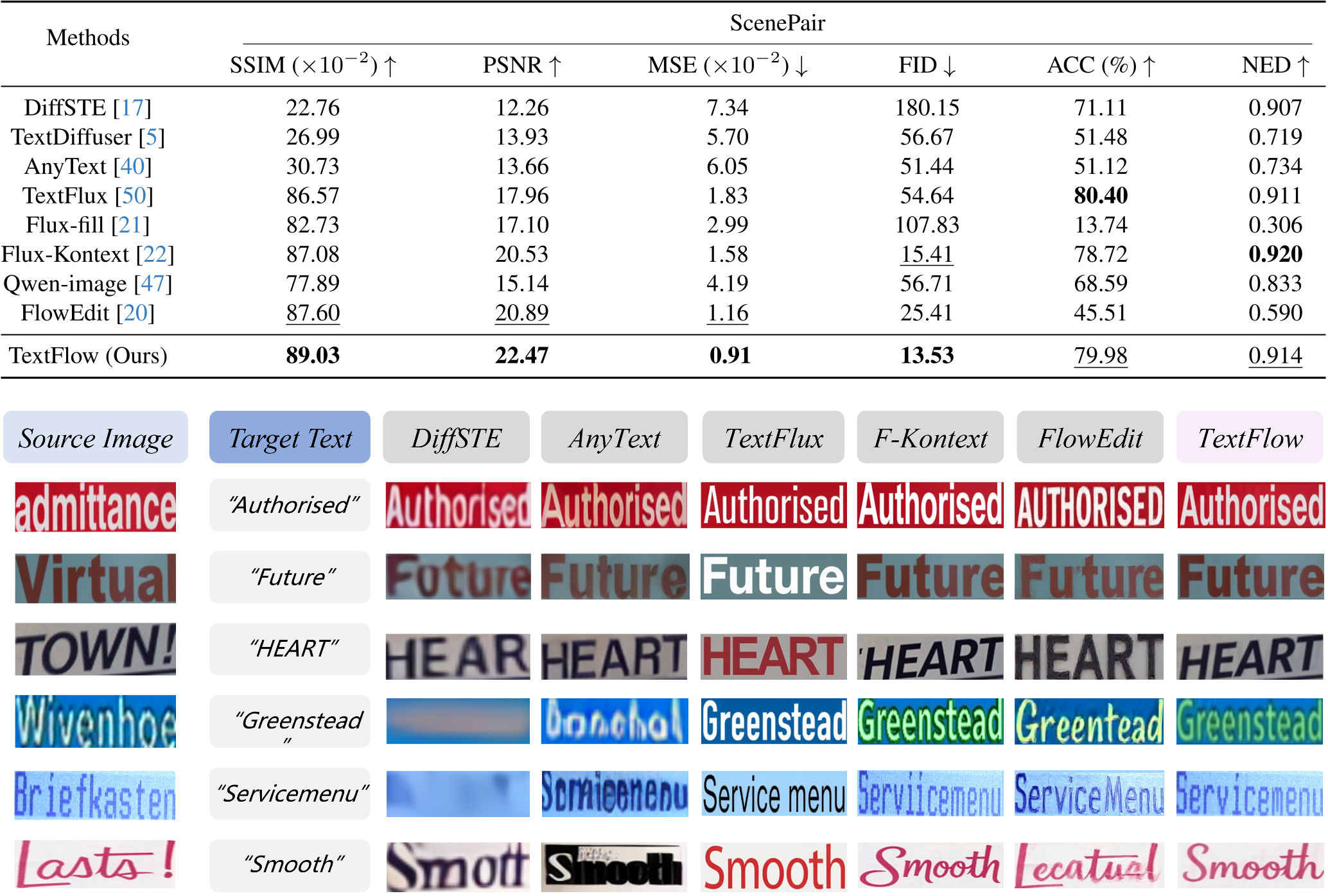
Experiments: Superior Quality, Zero Training
TextFlow was tested on the ScenePair dataset, featuring real-world images from ICDAR and HierText.
- Visual Fidelity: It achieved the highest SSIM (89.03) and lowest MSE (0.91), proving that it preserves the original background better than training-based competitors.
- Text Accuracy: Despite being training-free, its 79.98% accuracy rivaled dedicated models like TextFlux.
Qualitative Edge
Where other models might turn a "Menu" into a distorted blob, TextFlow maintains the metallic texture, the perspective, and the specific font case of the original scene.
Critical Insight & Future Outlook
The brilliance of TextFlow lies in its "Phase-Awareness." It recognizes that generative models are not monolithic processes; they are evolving trajectories. By mathematically correcting the path early (FMS) and sharpening the focus late (AttnBoost), it mimics the precision of a trained model.
Limitations: As noted by the authors, complex multi-line layouts and extreme perspective warping still pose challenges. However, the path it blazes toward "Training-Free Everything" is a significant milestone for efficient AI deployment.
Conclusion
TextFlow proves that we don't always need more data; sometimes, we just need better trajectory control. It stands as a powerful tool for advertisement design, image translation, and privacy-focused content redaction.