本文提出了 TextFlow,一种无需训练(Training-free)的场景文本编辑框架。该方法基于 Flow Matching 架构,通过集成 AttnBoost 和 Flow Manifold Steering (FMS) 模块,实现了在不进行任何任务特定微调的情况下,在自然图像中生成高质量、风格一致且文字准确的编辑结果。
TL;DR
传统的场景文本编辑(STE)往往需要在成千上万的配对数据上进行昂贵的微调。TextFlow 彻底打破了这一现状,它通过在预训练的 FLUX/DiT 模型中引入“阶段性引导”,无需任何训练便能修改图片中的文字,同时完美复刻原图的字体风格、光照和背景。
背景定位
场景文本编辑不仅要“改字”,还要“改得像”。在学术坐标系中,TextFlow 属于无需训练的即插即用(Plug-and-play)方法。它巧妙地利用了 DiT(Diffusion Transformer)强大的表征能力,通过数学手段干预去噪轨迹,在性能上首次逼近甚至超越了那些动辄训练数周的重型模型(如 DiffSTE, AnyText)。
核心痛点:为什么“改字”这么难?
- 信噪比非均匀性:在去噪早期,模型决定了大轮廓(背景、布局);后期决定了细枝末节(文字笔画)。现有方法往往“胡子眉毛一把抓”,导致文字准了风格丢了,或者风格保住了文字却是一团浆糊。
- 配对数据稀缺:现实中很难找到两张背景完全相同、仅文字不同的真实照片。
核心方法论:两步走的艺术
TextFlow 的核心直觉是将编辑过程解耦为两个阶段:
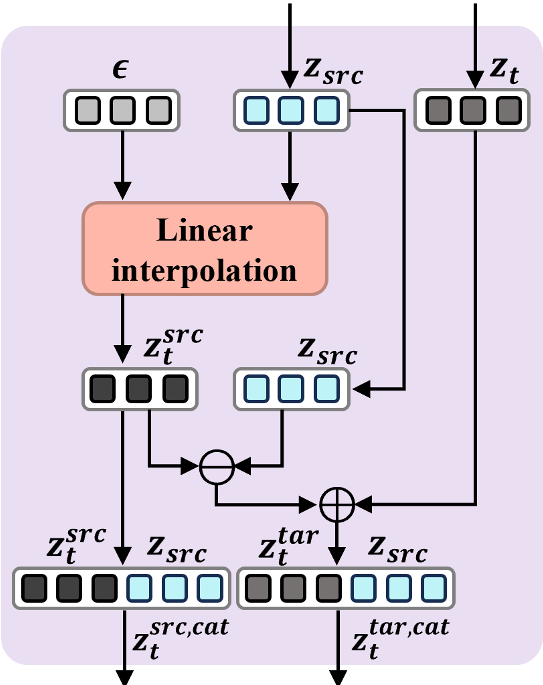
1. 结构化锚定:Flow Manifold Steering (FMS)
在去噪的前半段,FMS 模块大显身手。它通过计算源图像和目标提示词在潜空间中的速度场差异(Velocity Field Differential),补偿噪声注入引起的几何偏移。这就像给生成的潜变量安装了一个“陀螺仪”,确保它在变形时不会偏离原始图像的风格流形。
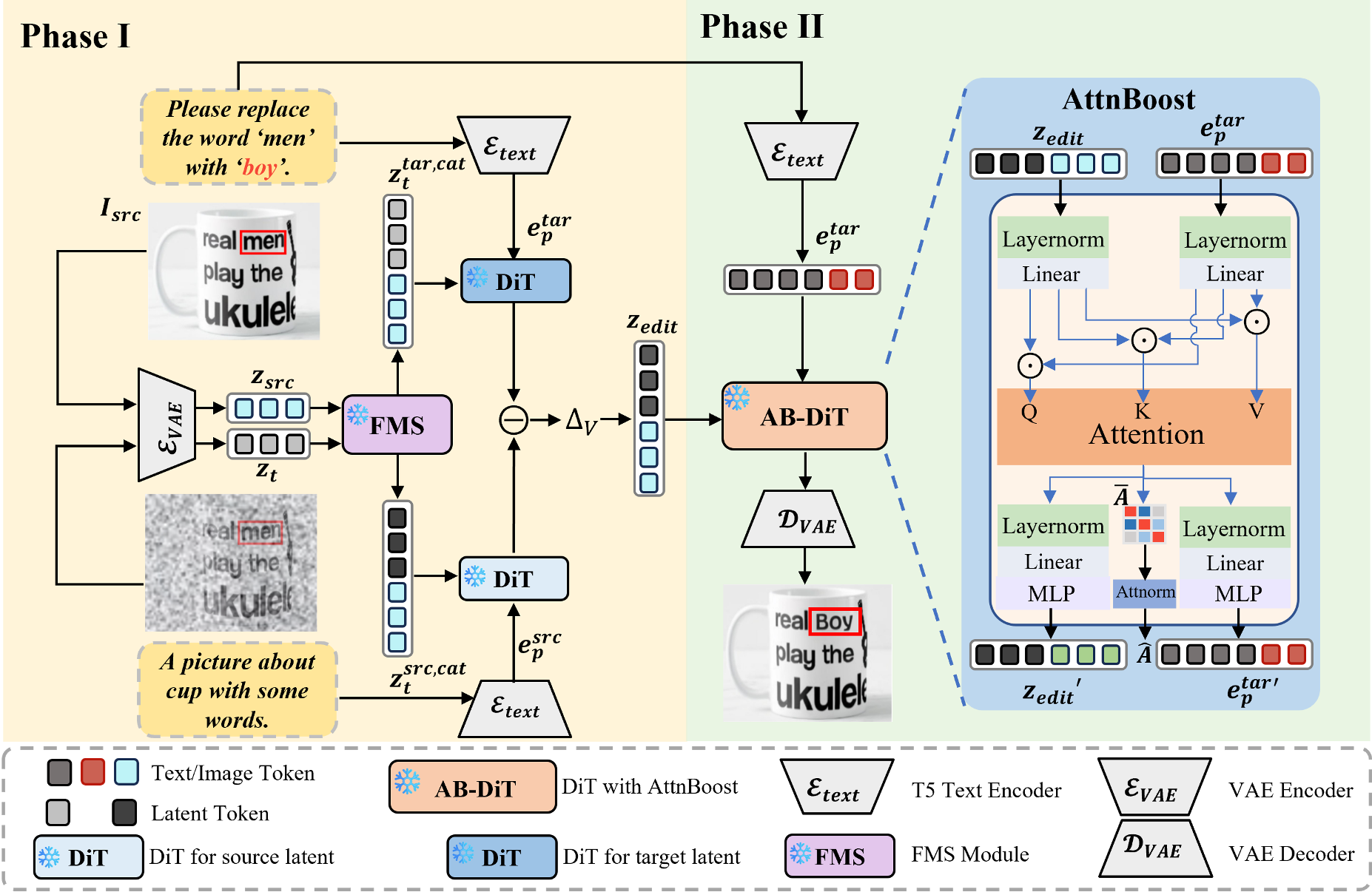
2. 精确渲染:Attention Boost (AttnBoost)
在去噪的后半段,模型开始雕琢文字细节。AttnBoost 通过提取 Cross-Attention Map,动态识别文字区域并进行“过冲(Overshooting)”增强。这种空间感知的引导逻辑,让模型在渲染字符时目标更明确,极大降低了漏字、错字和字符重叠(Artifacts)的概率。
实验与结果:训练型方法的有力竞争者
实验结果令人振奋。在 ScenePair 基准测试中,TextFlow 在多个关键指标上登顶:
- 图像保真度:PSNR 提升至 22.47(此前最优约 20.89),FID 降低至 13.53。
- 文字准确率:在无需配对数据训练的情况下,达到了 79.98% 的准确率,距离最强的训练型方法仅一步之遥。
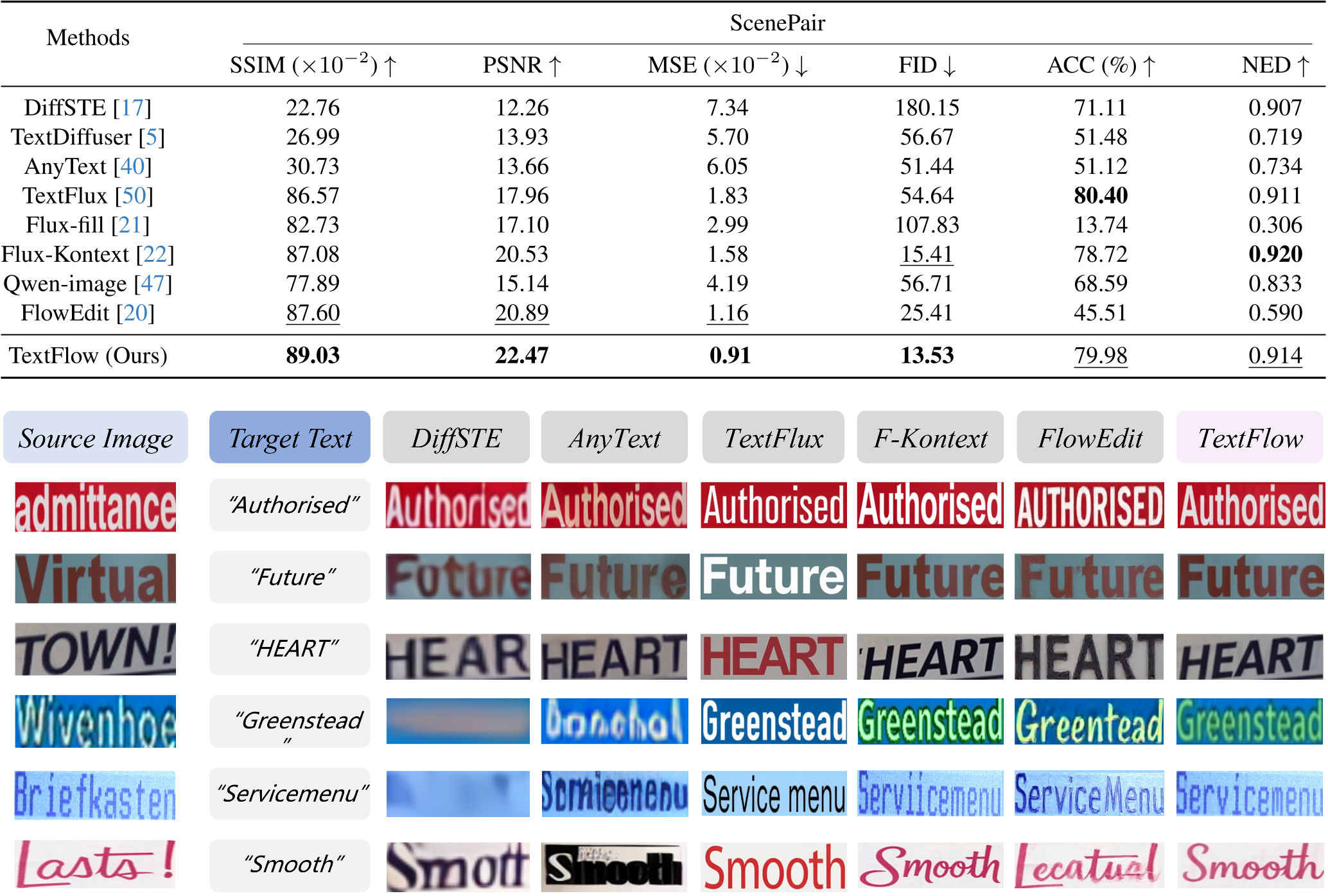
从定性对比图可以看出,TextFlow 在处理如“Servicemenu”这类长单词以及保持光影氛围方面,明显优于 FlowEdit 和 Flux-Kontext。
深度洞察与展望
TextFlow 的成功揭示了一个深刻的学术见解:扩散模型的去噪过程具有明显的层级语义特性。相比于从头训练,如何“优雅地”干预预训练模型的内部状态(如 Attention 和 Velocity Field)可能是更高效的路径。
局限性:尽管表现惊人,TextFlow 在处理具有剧烈透视畸变的文字或极度不规则的手写体时仍显吃力。未来的研究方向可能会集中在如何将多视图几何约束进一步融入无需训练的采样过程中。
总结
TextFlow 为场景文本编辑提供了一个极具吸引力的“平替”方案。它不仅降低了 STE 任务的门槛,也为其他需要保持高度风格一致性的图像编辑任务(如 Logo 替换、广告合成)提供了非常有价值的参考。