本文提出了 WRITEBACK-RAG,一种将 RAG 系统中的知识库(KB)视为“可训练组件”的框架。该方法通过在标注数据上进行证据蒸馏和回写增强,将散乱的多文档事实融合为精炼的知识单元并重新索引,在 6 个基准测试中平均提升了 2.14% 的表现。
TL;DR
在检索增强生成(RAG)领域,我们习惯于调整检索器(Retriever)或微调生成器(Generator),却往往把知识库(KB)看作是一块由于原始语料(如 Wikipedia)决定的“死石”。WRITEBACK-RAG 颠覆了这一认知,它提出:知识库应该是可训练的。通过离线识别检索中的痛点、蒸馏碎片化事实并“回写”增强文档,它在零推理开销的前提下,显著提升了 LLM 在复杂问答任务中的表现。
痛点深挖:知识的“碎片化”与“噪音”
当前的 RAG 系统普遍面临一个物理瓶颈:原始文档的边界(Document Boundaries)不一定是知识的逻辑边界。
- 碎片化 (Fragmentation):回答一个问题可能需要文档 A 的第一段和文档 B 的最后一段,模型需要跨长上下文进行推理,极易迷失。
- 冗余噪音 (Noise):检索到的 Top-K 文档中,大部分内容往往与当前 Query 无关,干扰了 LLM 的注意力。
作者认为,既然模型参数可以通过数据训练,那么非参数化的外部知识库也应该针对下游任务进行“训练”(即重组和精炼)。
方法论详解:如何“训练”一个知识库?
WRITEBACK-RAG 的核心逻辑是在训练阶段通过“实战检测”来提纯知识。其流程主要分为三个核心模块:
1. 两阶段门控筛选 (Two-stage Gating)
并非所有训练数据都需要回写。
- 效用门控 (Utility Gate):只选择那些“由于检索才答对”或“检索显著提升了答案质量”的样本。如果模型不靠检索就能答对,说明这是参数化知识,无需浪费空间回写。
- 文档门控 (Document Gate):在检索到的 Top-K 文档中,通过逐一对比(Ablation-like logic),剔除那些对最终生成没有贡献甚至起反作用的噪音文档。
2. 证据蒸馏 (Evidence Distillation)
利用性能强大的 LLM 作为蒸馏器,将通过门控筛选的多个证据片段合并成一个单一的、高密度的“知识单元”。这不仅是压缩,更是语义融合——将分散的事实拼成一张完整的版图。
3. 持久化回写 (Write-Back)
蒸馏后的文档被赋予标题,并作为一个独立的索引库与原始库并行存在。
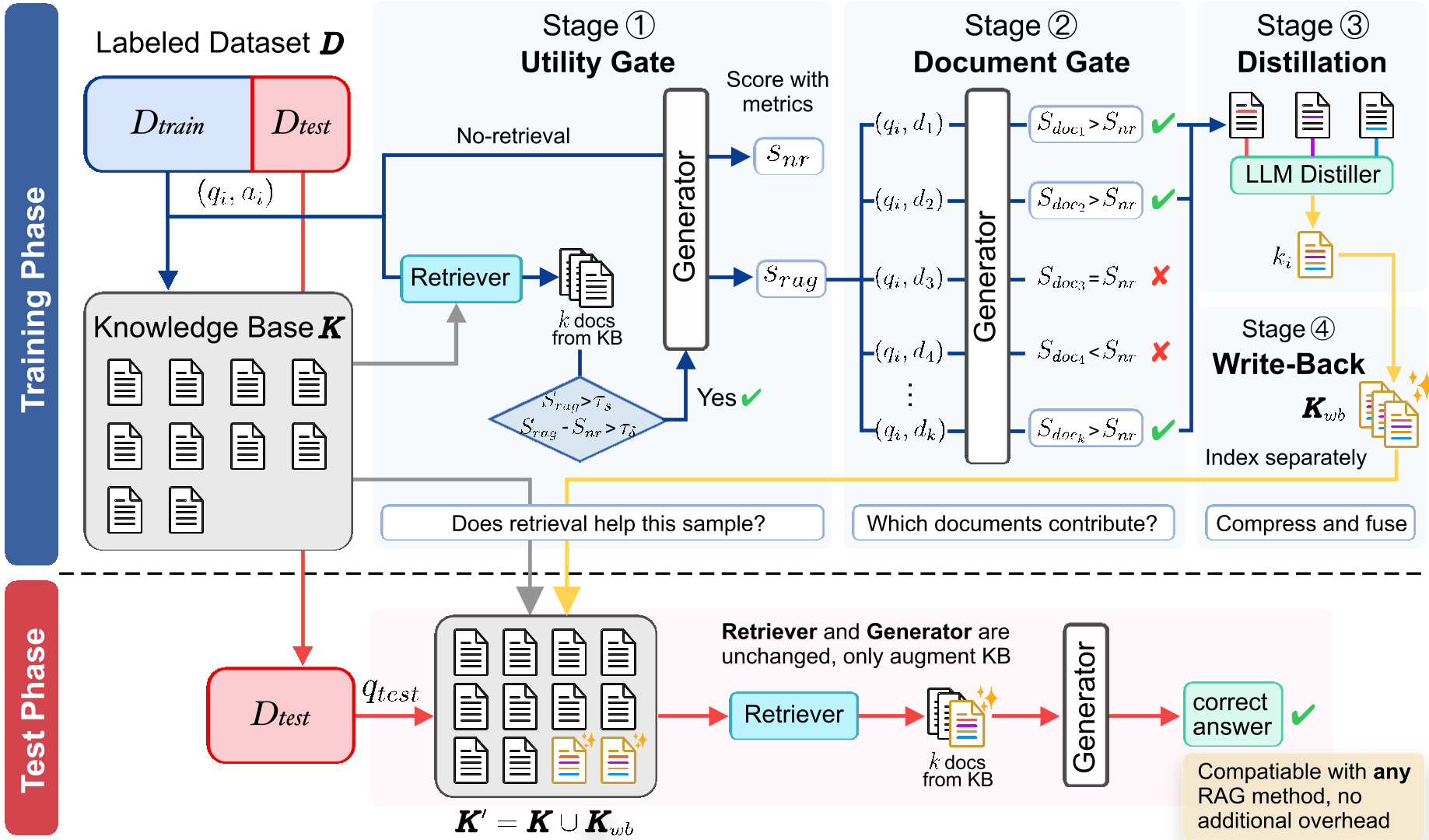 如图所示,WRITEBACK-RAG 在离线阶段生成增强文档,在线推理时仅需搜索合并后的索引。
如图所示,WRITEBACK-RAG 在离线阶段生成增强文档,在线推理时仅需搜索合并后的索引。
实验与结果:全方位的加成
研究团队在 4 种主流 RAG 方法(Naive, RePlug, Self-RAG, FLARE)上进行了详尽实验。
核心战绩:
- 普适性提升:在所有 48 个实验设置中(不同模型、不同方法、不同任务),WRITEBACK-RAG 全部实现了正向提升,平均增益为 +2.14%。
- 复杂推理表现:在需要跨文档推理的 HotpotQA 上,压缩率达到了惊人的 6.79x,说明该方法极擅长处理逻辑复杂的分布式事实。
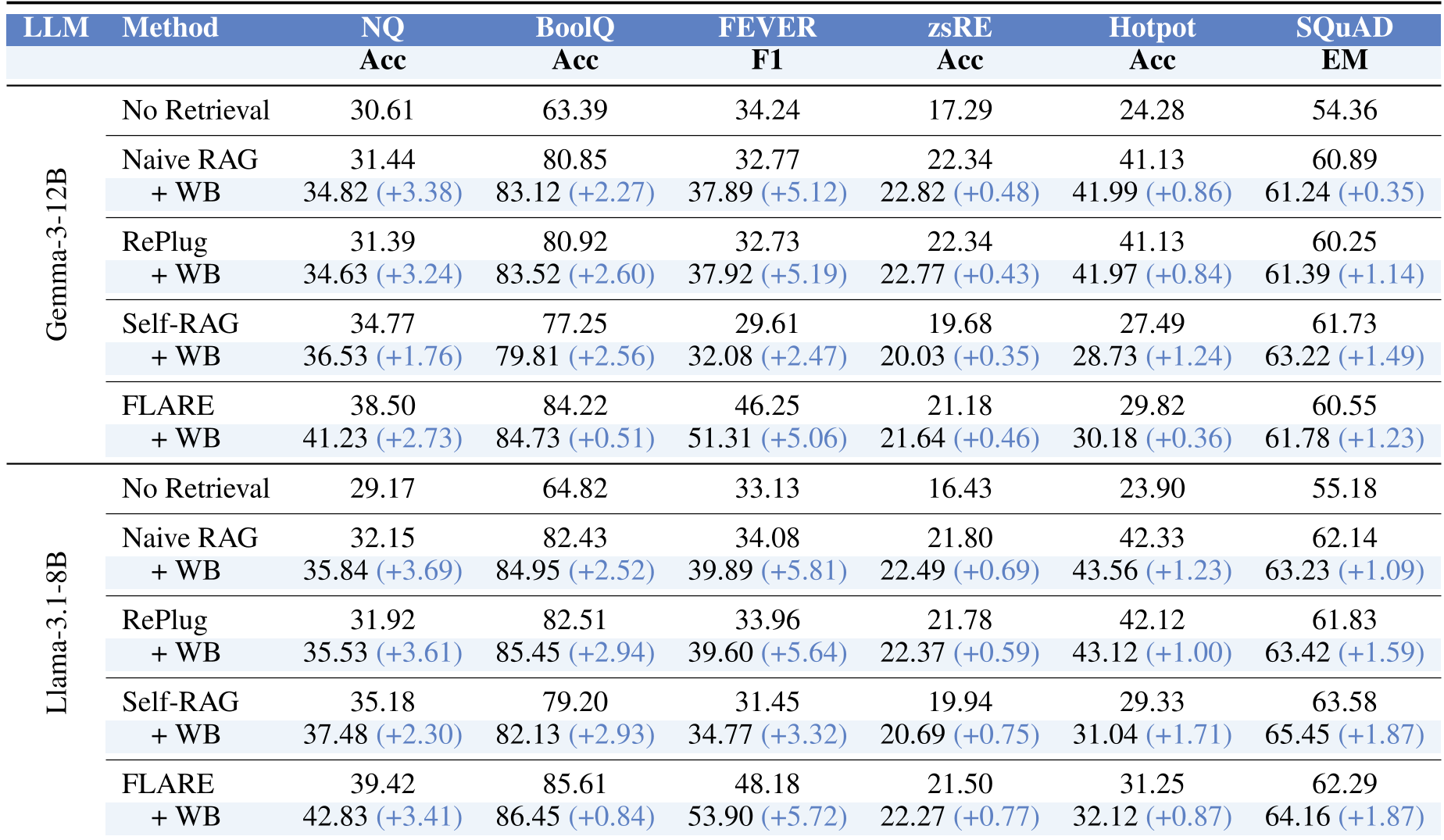 从表中可见,无论是在 Gemma 还是 Llama 架构下,+WB(Write-Back)版本的性能均显著优于原始基线。
从表中可见,无论是在 Gemma 还是 Llama 架构下,+WB(Write-Back)版本的性能均显著优于原始基线。
深度洞察:知识库的“预热”效应
一个有趣的发现是跨方法迁移(Transfer)。用 Naive RAG 标注并蒸馏出来的知识库,给 RePlug 使用时,效果竟然一样好(甚至有时更好)。这有力证明了 WRITEBACK-RAG 提升的是知识本身的表达密度,而不是在过拟合某种特定的检索算法。
深度洞察与总结
为什么它有效? (The "Why")
WRITEBACK-RAG 的本质是一种非参数化的知识对齐。它不仅减少了检索时的维度(从 5 个碎片文档变成 1 个精炼文档),更重要的是,它在离线阶段就预先解决了“跨文档信息检索与整合”这一难题,让在线生成阶段的模型能够“饭来张口”。
局限性与展望
- 训练成本:该方法需要带标签的训练数据进行离线蒸馏,对于完全无监督的情况,可能需要借助 LLM-as-a-Judge 生成伪标签。
- 动态性:目前讨论的是一次性增强。未来如果原始语料库发生更新,如何动态地更新或删除过期回写文档将是关键研究点。
总结 (Takeaway)
WRITEBACK-RAG 为 RAG 系统提供了一个低成本、高回报的优化路径:不要只想着造更好的放大镜(检索器)或更好的眼睛(生成器),去改良被观察的标本(知识库)本身,往往能起到事半功倍的效果。