本文提出了一种基于演化博弈论(EGT)和强化学习(RL)的 AI 治理模型。该模型将“信任”创新性地定义为用户在与 AI 开发者互动中减少监控的行为,探讨了在监控成本和制度惩罚影响下,用户信任策略与开发者安全性选择的共演化动力学。
TL;DR
信任 AI 是一个动态的“猫鼠游戏”吗?本研究通过演化博弈论(EGT)证明:信任本质上是用户为了节省成本而减少对 AI 输出的监控。研究指出,AI 系统能否走向安全,不仅取决于法律罚款的高低,更取决于用户监控 AI 的难度(成本)。如果监控太贵,即便有法律约束,系统也会滑向“不安全”的深渊。
背景定位:从“单次抉择”到“动态共演”
在 AI 治理领域,过去的研究往往把用户是否信任 AI 看作是一个非黑即白的单次选择。但在现实中,我们对 ChatGPT 或自动驾驶的信任是随着一次次使用而变化的。本文将研究视角从静态博弈转向了演化动力学,探讨了用户和 AI 巨头们在长期的博弈中,是如何互相改变对方行为策略的。
痛点深挖:为什么“盲目信任”和“严苛审计”都救不了 AI 安全?
- 监控是有成本的:核查 LLM 生成的代码、审计 AI 模型的偏见都需要人力和算力财力。如果核查成本 过高,用户就会倾向于“盲目相信”,这给开发者提供了偷工减料的空间。
- 制度惩罚的滞后性:如果开发者违规后的罚款 低于其保持安全性所需的开发成本 ,那么在演化压力下,开发者必然会选择不安全路径。
核心机制:信任策略的五种形态
作者在模型中设定了精妙的用户策略矩阵,特别是引入了“信任”与“不信任”的阈值启发式策略:
- TFT(以牙还牙):始终监控,根据开发者上一轮的表现决定下一轮是否采用。
- TUA(信任阶段):如果开发者连续 轮表现良好,用户进入信任状态,降低监控频率。
- DtG(不信任阶段):如果开发者连续表现糟糕,用户进入防御状态,减少采用。
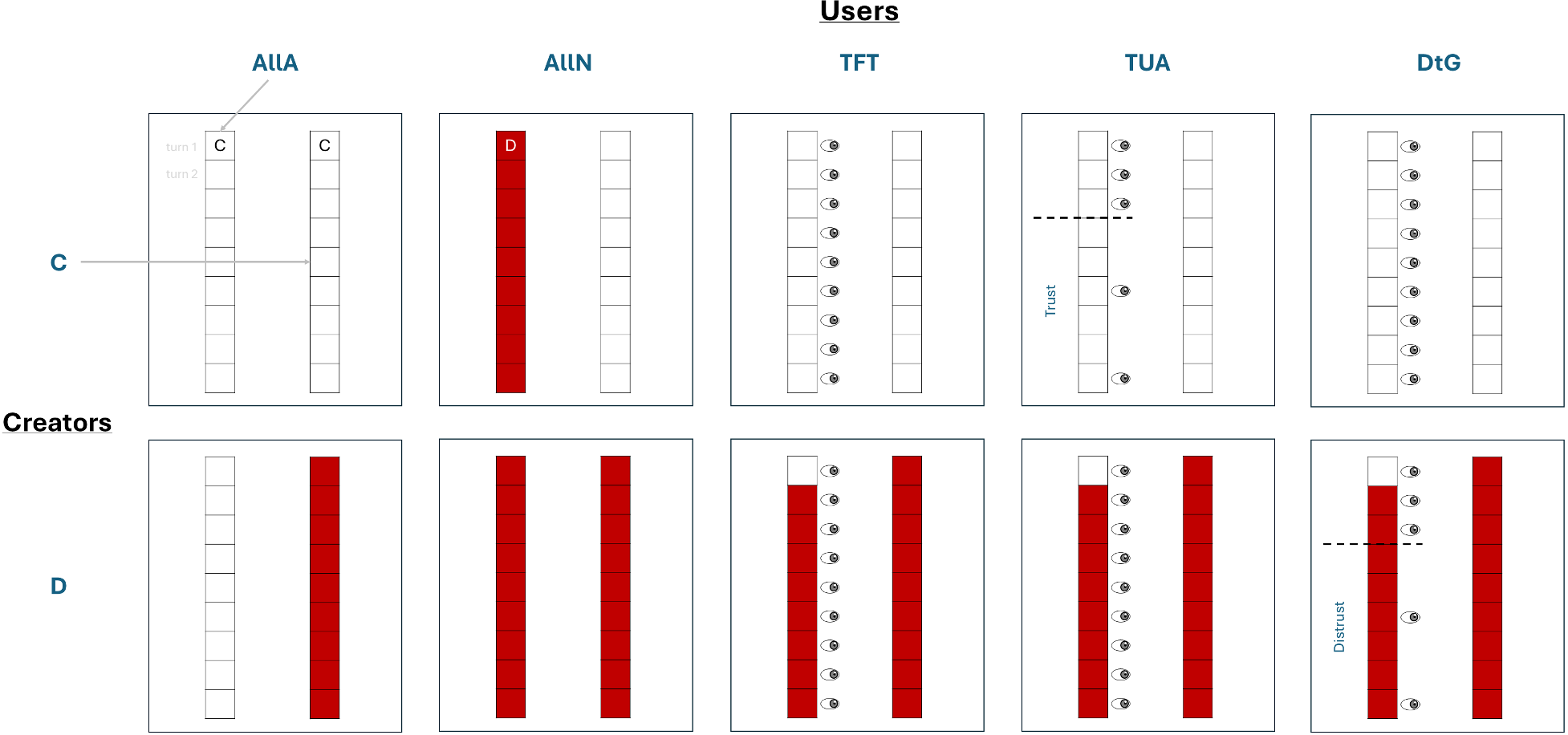 图 1:用户策略(左)与开发者行为(右)的交互逻辑,体现了监控成本如何随信任状态改变。
图 1:用户策略(左)与开发者行为(右)的交互逻辑,体现了监控成本如何随信任状态改变。
实验与结果:监控成本是安全的“呼吸机”
通过对无限群体和有限群体的仿真,研究发现了一个残酷的现实:
- 当监控成本 较低时,基于信任的策略(TUA/DtG)能显著提高用户采用率,并倒逼开发者保持安全。
- 一旦监控成本 升高,系统的稳态会迅速从“安全且采用”崩塌为“不安全”或“拒绝采用”。
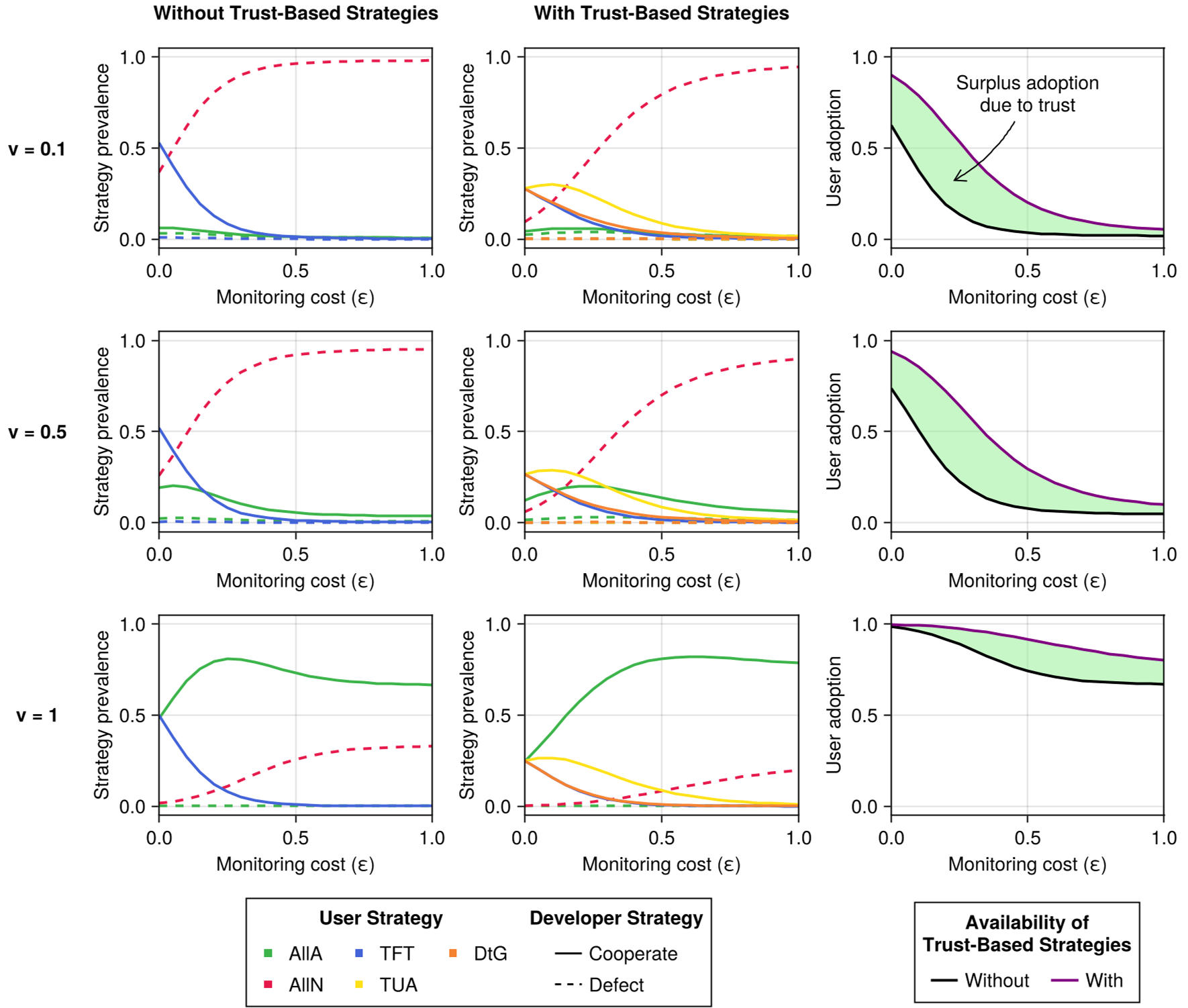 图 2:有限群体下的演化稳定状态。可以看到随监控成本增加(从左往右),用户策略从主动监控转向放弃(AllN)。
图 2:有限群体下的演化稳定状态。可以看到随监控成本增加(从左往右),用户策略从主动监控转向放弃(AllN)。
强化学习(Q-learning)的实验也验证了这一结果:在强化学习智能体(RL Agents)驱动的社会中,高昂的监控成本直接导致了“互害社会”的形成——开发者选择违规,用户选择放弃。
深度洞察:对 AI 治理的启示
这篇论文为政策制定者提供了极为务实的建议:
- 降低审计门槛比单纯加重罚款更重要:如果政府能通过“透明度法案”,让第三方机构或个人能以更低成本验证 AI 的安全性,社会将自发演化出安全生态。
- 拒绝“黑盒信任”:完全的免监控(AllA 策略)是危险的。良性的 AI 生态需要用户保留“偶尔回头看一眼”的能力和动机。
- 动态监管:监管不应是静态的条文,而应是能根据用户监控频率与开发者合规成本动态调整的博弈机制。
总结
该工作跨越了数学、社会学和计算机科学的边界。它告诉我们,AI 安全不只是技术问题,更是经济学和演化生物学问题。开发者和用户之间的信任,不是建立在道德期望上,而是建立在“低成本监控”所形成的威慑平衡之上。
局限性:模型假设用户和开发者群体是同质的,而现实中 Tech Giants 和初创公司的成本结构完全不同。未来的研究应引入多层级的参与者。