The paper introduces 2Xplat, an end-to-end two-expert framework for pose-free feed-forward 3D Gaussian Splatting (3DGS). By decoupling camera pose estimation (Geometry Expert) from Gaussian synthesis (Appearance Expert), it achieves SOTA results on the DL3DV and RE10K datasets, significantly outperforming unified monolithic architectures in both reconstruction quality and training efficiency.
Executive Summary
The field of 3D reconstruction is rapidly shifting from per-scene optimization (taking minutes or hours) to feed-forward synthesis (taking milliseconds). However, most "pose-free" models attempt to solve camera trajectory and visual appearance simultaneously within a single, monolithic neural network.
2Xplat challenges this "all-in-one" status quo. By explicitly decoupling the task into a Geometry Expert and an Appearance Expert, the authors achieve state-of-the-art (SOTA) results that rival methods using ground-truth poses. Most impressively, the model converges in just 5,000 iterations, whereas existing unified models often require 150,000.
The Problem: The Pitfalls of "All-in-One" Architectures
In a typical pose-free 3D reconstruction pipeline, the model receives uncalibrated images and must guess where the cameras are while simultaneously building a 3D volume. The prevailing paradigm uses a single backbone for both. The authors identify three critical flaws in this design:
- Conflicting Objectives: Perfect geometric accuracy isn't always necessary for perfect visual fidelity. Strict geometric constraints in a shared representation can actually hinder the "rendering" capability of the model.
- Representational Bottleneck: High-fidelity 3D Gaussian generation requires massive spatial reasoning capacity. Cramming this into a "geometry-first" backbone limits its potential.
- Pose Ignorance: Unified models cannot easily use advanced "pose-conditioned" architectures since the pose is only a hidden intermediate or a final output, not a known input that can be used to align features.
Methodology: The Two-Expert Framework
The core philosophy of 2Xplat is explicit decoupling. The pipeline operates in a sequence:
- Geometry Expert (Pose Prediction): Using a pre-trained backbone (like Depth Anything 3), the model estimates the relative rotation ($R$) and translation ($t$) of all input views.
- Appearance Expert (Gaussian Synthesis): These predicted poses are explicitly fed into a Multi-view Pyramid (MVP) Transformer.
- Pose-Aware Alignment: Because the poses are now "known" inputs to the second stage, the model can use PRoPE (Relative Positional Encoding) and other pose-aware mechanisms to align visual features along epipolar lines.
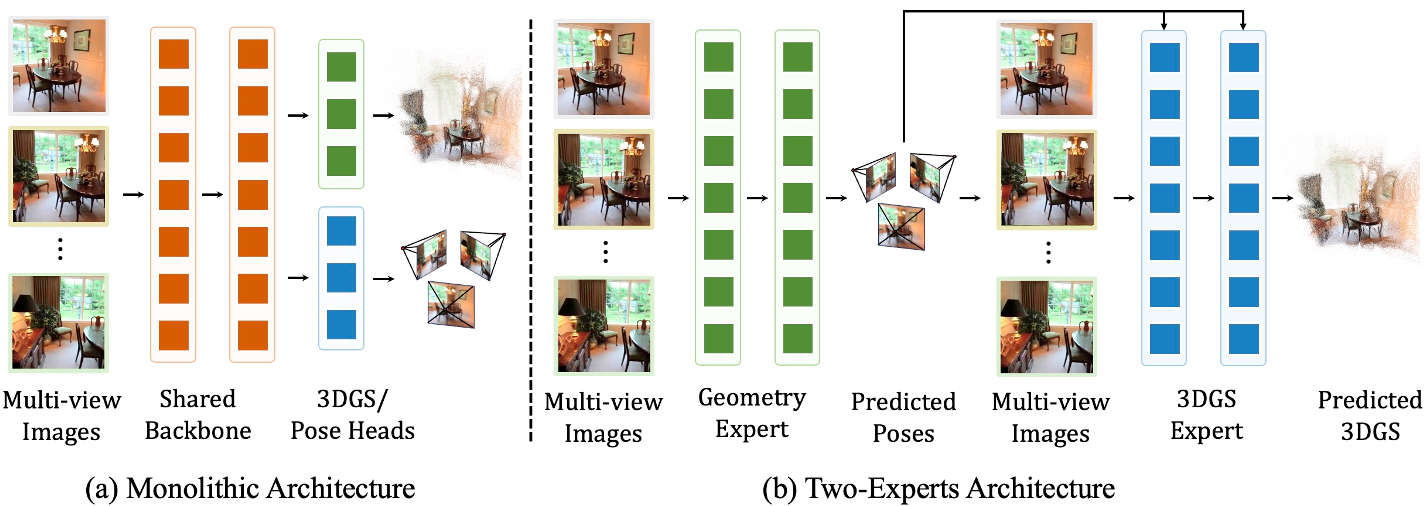 Fig. 2: Comparing the Monolithic (Unified) design vs. the proposed Two-Expert Architecture.
Fig. 2: Comparing the Monolithic (Unified) design vs. the proposed Two-Expert Architecture.
Experiments and Results
2Xplat was tested on challenging datasets like DL3DV and RealEstate10K.
- Higher Fidelity: On the DL3DV dataset with 12 input views, 2Xplat achieved a PSNR of 27.24, outperforming the previous best pose-free method (YoNoSplat) by nearly 7 dB.
- Inference Speed: Despite having two experts, the modular design allows for smaller, more efficient backbones. The "Ours-L" variant is significantly faster than competing 1B+ parameter monolithic models.
- Robustness: Unlike prior methods that degrade as the number of input views increases, 2Xplat actually improves, showing it better utilizes multi-view information.
 Table 1: Quantitative comparison on DL3DV. Note the consistent lead of "Ours" across 6v, 12v, and 24v settings.
Table 1: Quantitative comparison on DL3DV. Note the consistent lead of "Ours" across 6v, 12v, and 24v settings.
Critical Insight: Training Efficiency
Perhaps the most "academic" contribution of this work is the realization that pre-trained experts provide a better starting point than a joint backbone. In monolithic models, new heads are often initialized randomly, forcing the model to re-learn task-specific mappings. In 2Xplat, since both experts start from highly mature pre-trained versions, the end-to-end "fine-tuning" is exceptionally fast. This shifts the focus from "training a 3D model" to "teaching two experts to talk to each other."
Conclusion & Taking it Further
2Xplat proves that modularity is the key to scaling 3D generation. By letting a geometry expert handle the "where" and an appearance expert handle the "what," we solve the entanglement problem.
Limitations: The authors note that pose estimation accuracy is slightly lower than models task-specifically optimized for SLAM, as 2Xplat prioritizes rendering quality. However, for most AR/VR and novel-view synthesis applications, the visual result is the gold standard, making 2Xplat a significant leap forward.