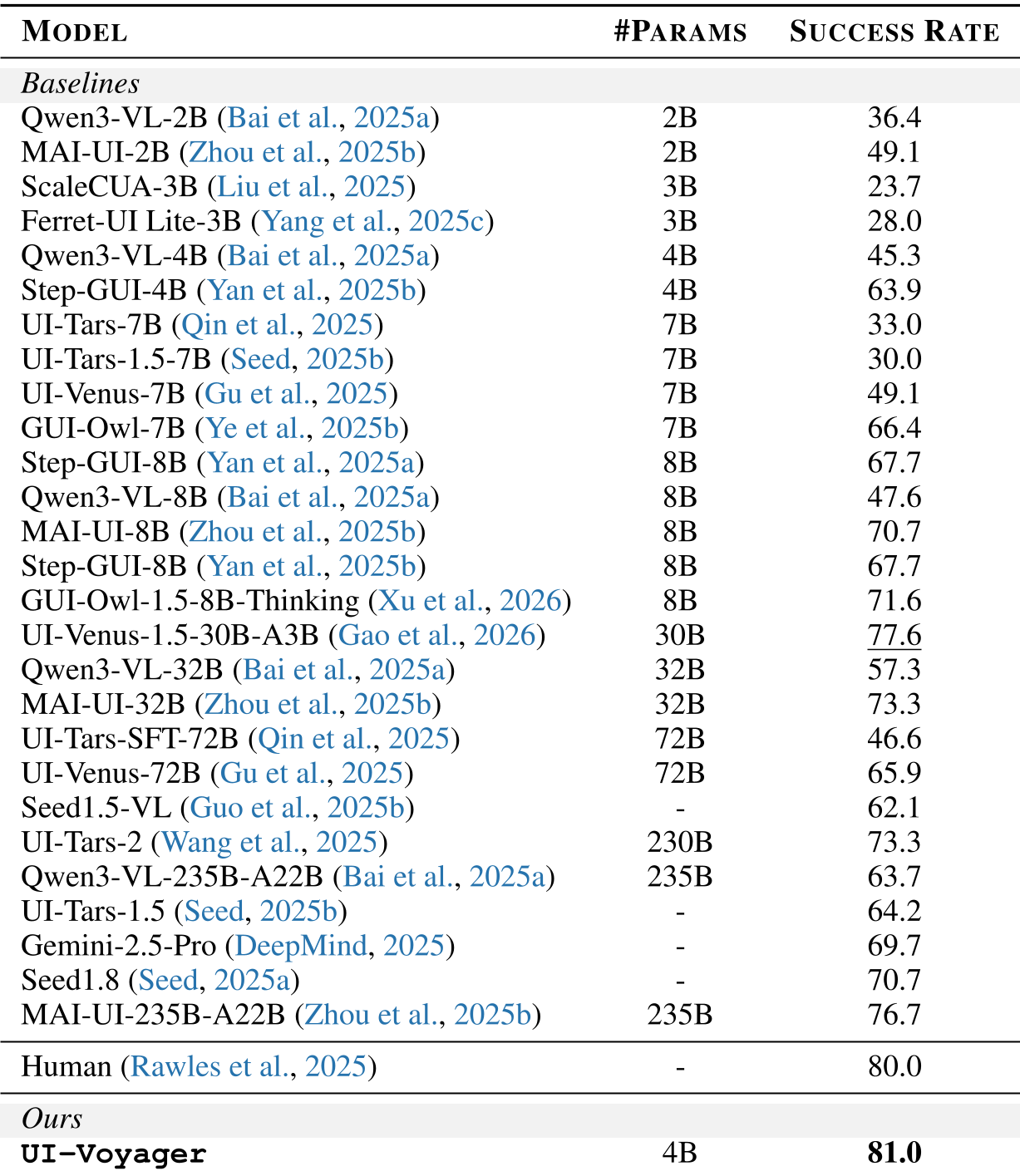
本文提出了 UI-Voyager,一个专为移动 GUI 自动化设计的两阶段自演进训练框架。该框架结合了拒绝微调(RFT)和创新的群体相对自蒸馏(GRSD)机制,在 AndroidWorld 基准测试中,仅凭 4B 参数量的模型便达到了 81.0% 的 Pass@1 成功率,超越了人类水平及众多巨型参数模型。
TL;DR
移动端 GUI 自动化长期受制于长路径决策中的“反馈稀疏”问题。腾讯混元团队提出的 UI-Voyager 演示了如何通过 RFT(拒绝微调) 和 GRSD(群体相对自蒸馏) 两阶段框架,让 4B 参数的模型在 AndroidWorld 榜单上跑出了 81.0% 的惊人成绩,不仅干掉了 235B 的大模型,甚至超过了人类 80% 的平均成功率。
背景:为什么 GUI Agent 总是“差临门一脚”?
传统的 GUI 智能体训练主要依赖模仿学习(SFT)或强化学习(RL)。但在实际应用中,开发者面临两个极其头疼的问题:
- 信用分配难题:一个需要 30 步的操作,如果第 5 步点错了导致最后失败,传统的强化学习只会给整条路径打 0 分,模型根本不知道哪里错了。
- 数据极度浪费:在探索过程中,智能体会产生海量的失败记录,这些记录通常被直接废弃,导致学习效率极低。
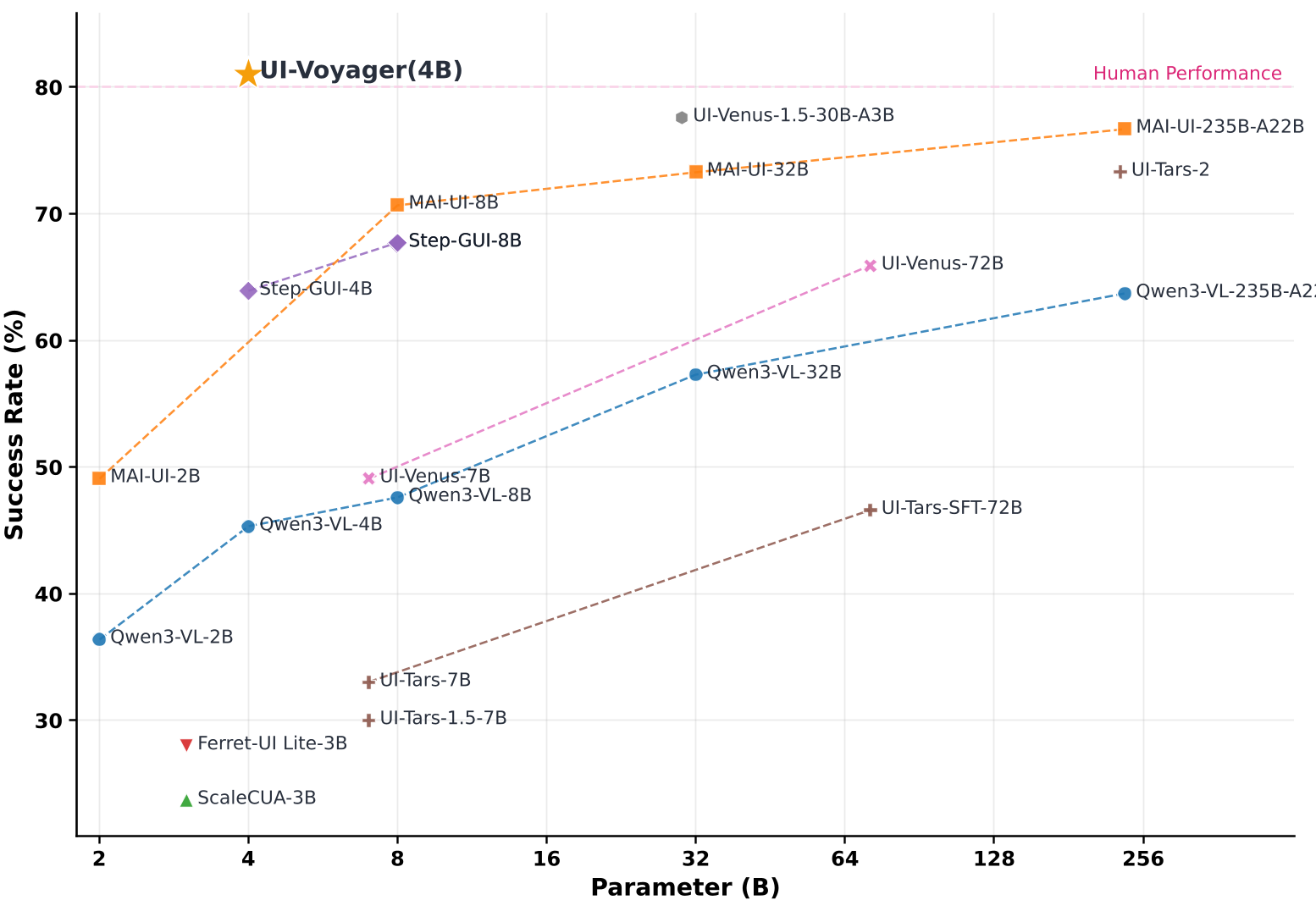
核心机制:UI-Voyager 的自进化之路
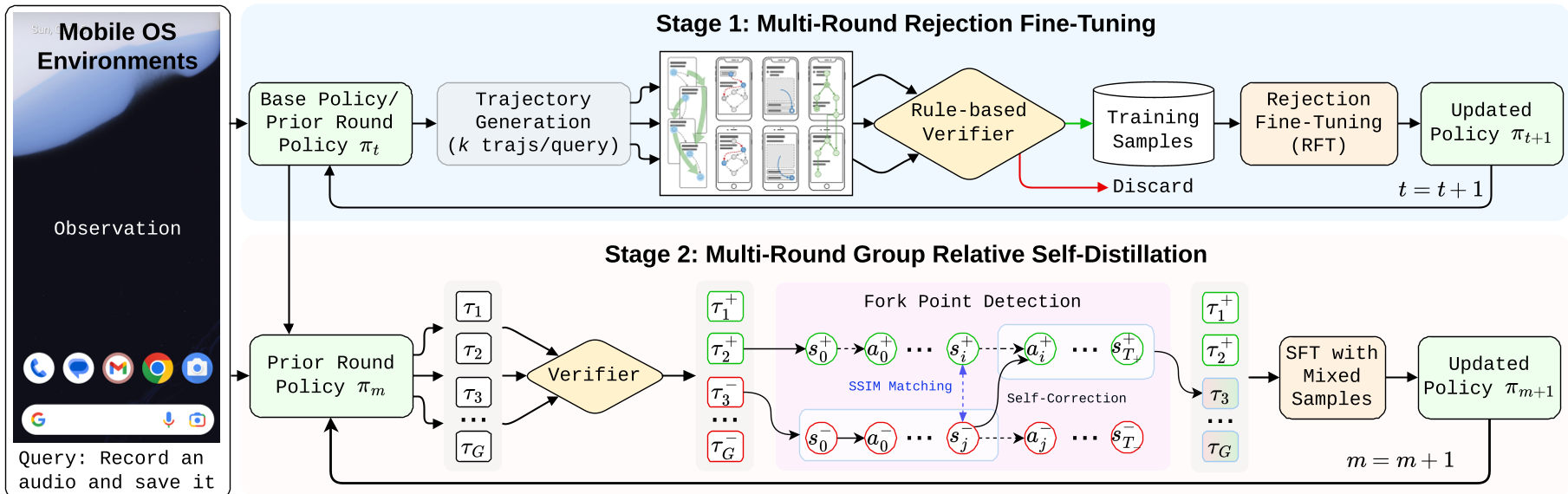
UI-Voyager 的核心在于一个闭环的自演进管线,分为 RFT 和 GRSD 两个维度:
1. Rejection Fine-Tuning (RFT) —— 优胜劣汰
通过种子任务生成器产生大量新任务,让模型自主尝试。只有那些最终成功的轨迹(通过 rule-based verifier 验证)才会被喂回模型进行微调。这一阶段完成了模型从“能看懂 UI”到“能做对任务”的基础跨越。
2. Group Relative Self-Distillation (GRSD) —— 失败是成功之母
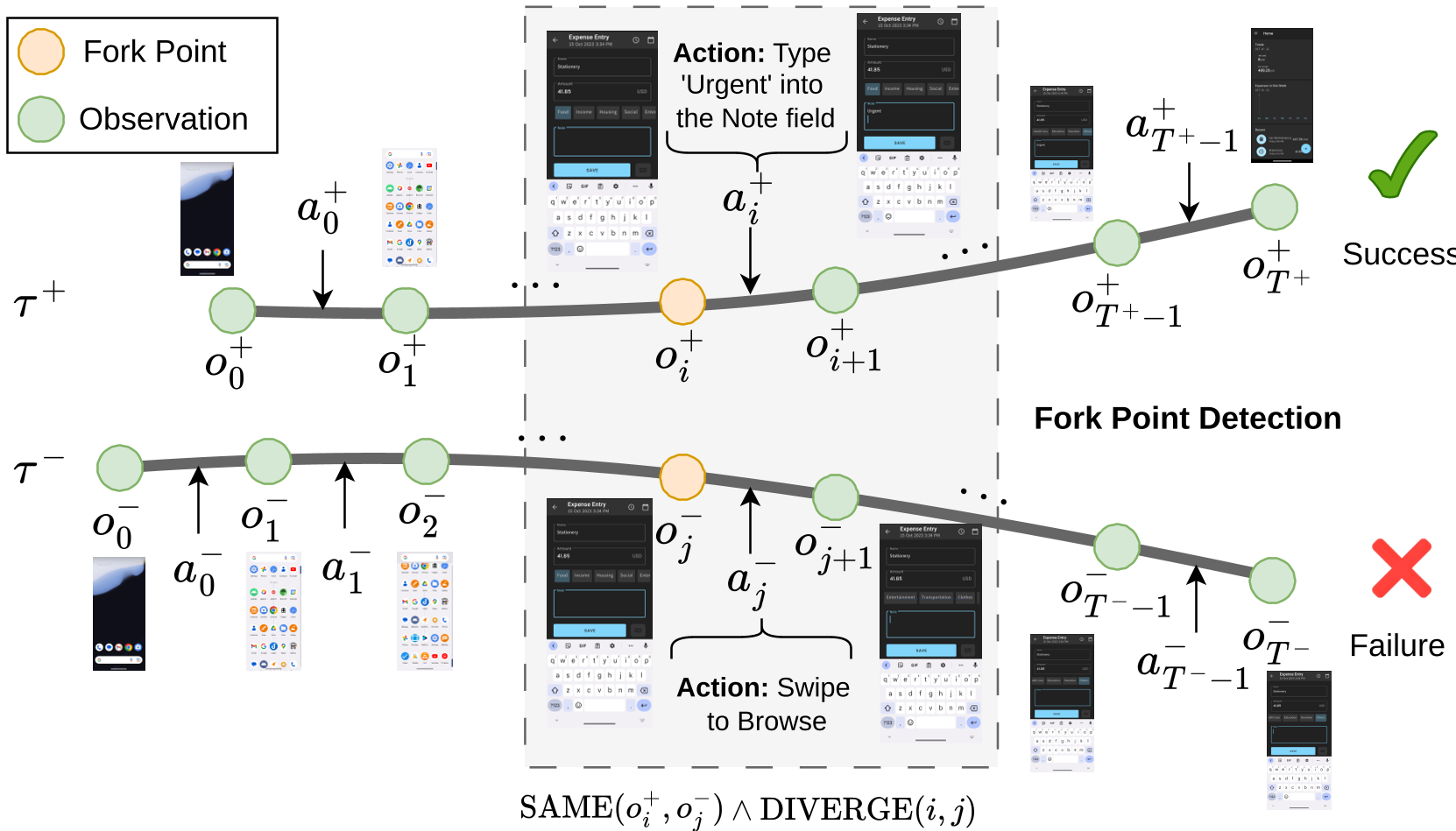
这是本文最具启发性的部分。当同一任务下,模型跑出了几条轨迹,有些成功了,有些失败了,UI-Voyager 并不只是丢掉失败的,而是进行分叉点检测(Fork Point Detection):
- 状态对齐:使用 SSIM(结构相似度算法)对比失败轨迹和成功轨迹的屏幕截图。
- 定位分歧:如果两个轨迹在同一个界面(State)下,成功路径往左点,失败路径往右点,那么这个点就是“分叉点”。
- 原地纠错:将成功路径在该点的“正确决策”提取出来,作为标签去监督失败路径在该点的“错误思维”。
实验分析:精准纠错的力量
在 AndroidWorld 的测试中,UI-Voyager (4B) 的表现堪称惊艳。
- 效率碾压:相比 GRPO 和 PPO 这种通用的强化学习算法,GRSD 能够利用失败轨迹中的“局部正确性”,提供更稠密的监督信号。实验证明,GRSD 后的模型在面对低成功率的困难任务(如 BrowserMaze)时,提升幅度远超传统 RL。
- 分叉点可视化:通过对
SystemBluetoothTurnOff等任务的复盘,发现模型能够精准定位到是因为初始滑动方向(向上滑还是向下滑通知栏)导致的分歧,并通过蒸馏快速修正了这一行为。
深度洞察:小模型的逆袭
UI-Voyager 的成功向行业传递了一个信号:数据质量与反馈精度优于模型参数量。
很多 70B 甚至 235B 的模型在 GUI 任务上折戟,是因为它们空有推理能力,却不理解 UI 交互中的微小状态变化。UI-Voyager 通过 SSIM 这种简单的物理直觉(图像结构相似度)找到了最廉价且有效的状态对齐方式,从而实现了高效的自蒸馏。
总结与未来展望
UI-Voyager 成功在 AndroidWorld 上刷到了 81% 的 SOTA。尽管目前仍面临实时执行中的异步性挑战(如 SSIM 对动画效果敏感),但其提出的 GRSD 框架为解决 Agent 的长路径决策问题提供了新的范式。
未来的移动 GUI 智能体,或许不再需要昂贵的人工演示标注,而是在不断的自尝试、自纠错中,进化成比用户更懂手机的“原生管家”。