UMPE (Unified Map Prior Encoder) is a novel architecture designed to integrate heterogeneous map priors—HD/SD vector maps, rasterized maps, and satellite imagery—into autonomous driving pipelines. It achieves a 67.4 mAP (+5.9) on nuScenes mapping and significantly reduces planning trajectory error (L2) from 0.72m to 0.42m.
TL;DR
The Unified Map Prior Encoder (UMPE) breaks the sensor-only bottleneck in autonomous driving by seamlessly integrating four types of map priors: HD/SD vector maps, rasterized maps, and satellite imagery. By introducing an alignment-aware architecture and a "geometry-first" fusion order, UMPE achieves SOTA performance in both online HD mapping (+5.9 mAP) and E2E planning (41% reduction in L2 error), while remaining robust to missing data sources at test time.
Problem & Motivation: The "Prior" Dilemma
While onboard sensors (LiDAR/Camera) are the eyes of an autonomous vehicle, map priors are its "memory." However, using this memory is notoriously difficult:
- Heterogeneity: Vectorized road polylines and rasterized satellite pixel grids are mathematically diverse.
- Pose Drift: Global maps rarely align perfectly with the local BEV (Bird's Eye View) frame of the car.
- Variable Availability: You might have HD maps in San Francisco, but only coarse SD maps or satellite tiles in the suburbs.
Most previous works (like SMERF or SatforHDMap) force-fit a specific prior, failing when conditions change. UMPE's insight is to treat priors as interchangeable signals that can be alignment-corrected and confidence-weighted on the fly.
Methodology: The "Geometry First, Appearance Second" Inductive Bias
UMPE's architecture is split into two specialized streams that reflect a deep understanding of road structures.
1. The Vector Encoder (Geometric Skeleton)
For HD/SD polylines, UMPE first applies a frame-wise SE(2) correction to fix pose drift. It then uses multi-frequency sinusoidal features to tokenize the points. The "secret sauce" here is Confidence-Biased Dual Cross-Attention. Instead of treating all map data as ground truth, the model learns to down-weight uncertain polylines using a log-confidence bias within the softmax layer.
2. The Raster Encoder (Dense Refinement)
Satellite and SD raster images pass through a shared ResNet-18 backbone conditioned by FiLM (Feature-wise Linear Modulation). This allows the same weights to handle different visual domains effectively.
3. Progressive Fusion
UMPE follows a specific order: Vector-then-Raster. This follows the inductive bias that global geometry (lanes/boundaries) provides the structural foundation, while raster data (crosswalk textures) provides local refinement.
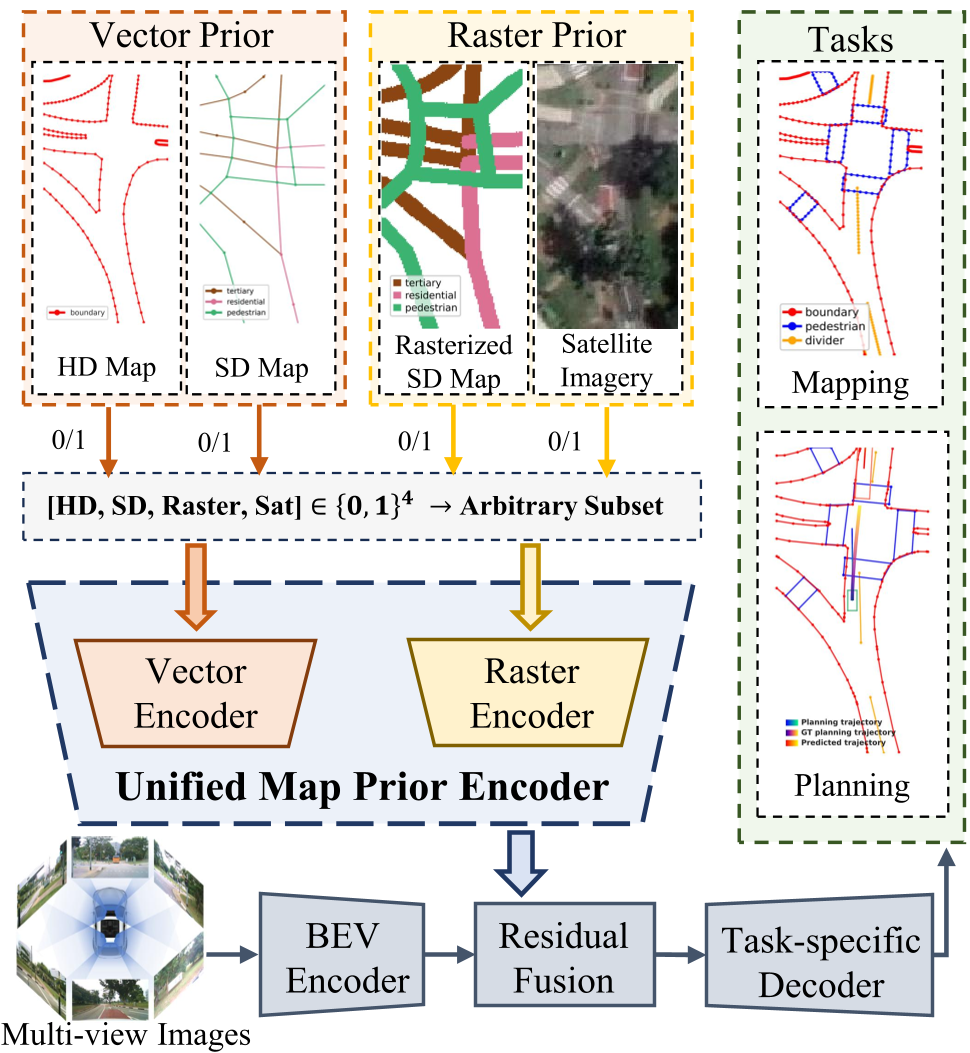 Fig 1. UMPE processes an arbitrary "powerset" of priors, fusing them into a unified BEV representation for downstream heads.
Fig 1. UMPE processes an arbitrary "powerset" of priors, fusing them into a unified BEV representation for downstream heads.
Experiments & Results: Better Mapping, Safer Planning
Mapping Supercharge
UMPE was plugged into strong baselines like MapTRv2 and MapQR.
- nuScenes: +5.9 mAP gain.
- Argoverse2: +4.1 mAP gain.
Interestingly, per-class analysis shows the vector encoder boosts "Dividers/Boundaries" (geometry), while the raster encoder fixes "Pedestrian Crossings" (appearance).
Planning Precision
When integrated into the VAD (Vectorized Autonomous Driving) planner, the results were even more dramatic. Trajectory L2 error dropped from 0.72m to 0.42m.
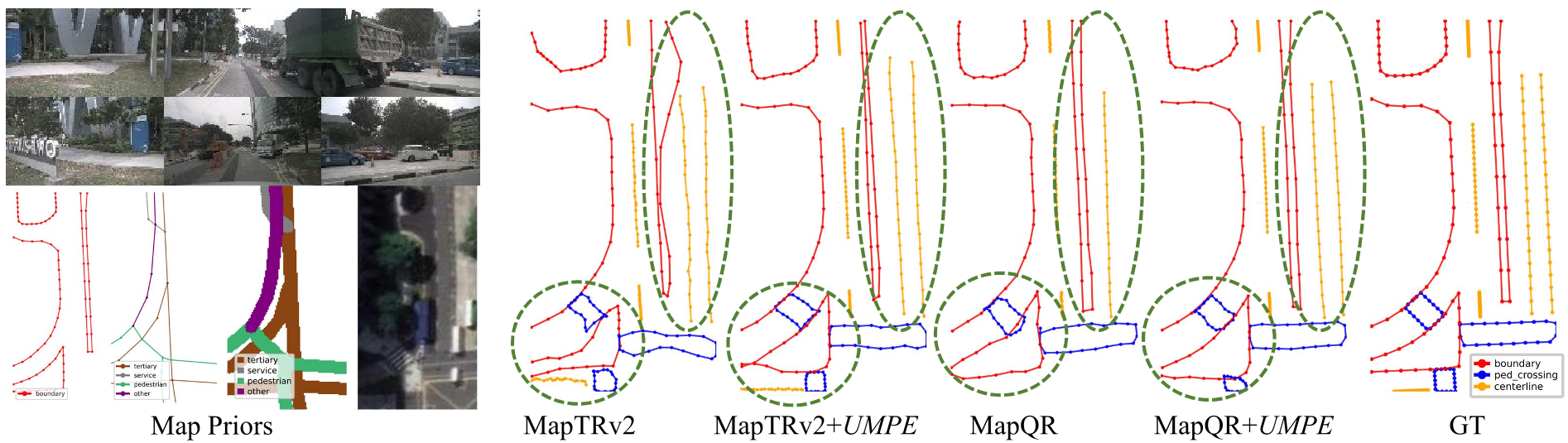 Fig 2. Visualization shows UMPE straightening broken boundaries and restoring missing dividers compared to sensor-only baselines.
Fig 2. Visualization shows UMPE straightening broken boundaries and restoring missing dividers compared to sensor-only baselines.
The "Powerset" Robustness
A standout feature is that a model co-trained with all four priors performs better on any single prior at test time than a model trained specifically for that single prior. This suggests that multi-source co-training helps the model learn a more generalized representation of world geometry.
Depth Insight: Why It Works
The success of UMPE lies in its "Do-No-Harm" initialization. By using zero-initialized residual fusion, the model starts by relying on its cameras (the BEV baseline) and only learns to incorporate map priors where they provide concrete evidence. This prevents "map hallucinations" where the vehicle might follow an outdated map into a construction zone.
Conclusion & Future Work
UMPE proves that we don't need a different model for every map-availability scenario. A unified encoder with smart alignment and confidence gating is sufficient to turn heterogeneous, noisy maps into a reliable safety layer.
The next frontier? Exploring how these priors perform in closed-loop driving, where the agent's decisions actively change its future relationship with the map.
Takeaway for Practitioners:
If you're building a mapping or planning stack, stop treating maps as a static input. Treat them as a noisy latent source that needs its own confidence-aware attention mechanism.