UniSD is a unified self-distillation framework that enables Large Language Models (LLMs) to improve their performance without external teacher models by learning from their own self-generated trajectories. The integrated version, UniSD*, achieves state-of-the-art results across six benchmarks, improving the base model by +5.4 points and outperforming the strongest baselines by +2.8 points.
TL;DR
The current paradigm of LLM adaptation is stuck in a "teacher-student" loop, often requiring a larger, closed-source model to teach a smaller one. UniSD (Unified Self-Distillation) flips the script. It is a systematic framework that allows LLMs to use their own outputs as supervision. By integrating reliability filtering, representation alignment, and stabilization techniques, the authors' flagship variant UniSD* boosts model performance by +5.4 points over raw baselines, proving that models don't always need a smarter teacher—they just need a better way to learn from themselves.
The Problem: The High Cost of External Expertise
Why do we still rely on GPT-4 to fine-tune smaller open-source models? While effective, this "imitation learning" has three fatal flaws:
- Cost & Privacy: Constant API calls are expensive and leak sensitive data.
- The "Ceiling" Effect: A student model can rarely surpass its teacher's fundamental reasoning logic through simple imitation.
- Noise: Autoregressive models generate free-form text. If a model tries to learn from its own mistakes without a filter, it risks "model collapse" where errors are reinforced.
Existing self-distillation methods were scattered and poorly understood. UniSD provides the first unified "operating system" for self-improvement.
Methodology: The Three Pillars of UniSD
The authors break down Self-Distillation into three critical axes. Instead of just "matching the next token," UniSD controls what is learned, how it's represented, and how fast the model updates.
1. Supervision Reliability (The Filter)
- Multi-Teacher Agreement: The model looks at its own output through different "lenses" (e.g., different few-shot prompts). If all views agree the output is good, the signal is trusted.
- Token-Level Contrastive Learning: It doesn't just learn what is right; it explicitly learns why a plausible-looking but incorrect answer is wrong.
2. Training Stability (The Anchor)
Self-supervision is inherently shaky. To fix this, UniSD uses an EMA (Exponential Moving Average) Teacher. Think of this as a "long-term memory" version of the model that changes slowly, preventing the student from chasing every random generation error.
3. Representation Alignment (The Soul)
Beyond just picking the right words (Logits), UniSD uses Feature Matching to ensure the internal "thought process" (hidden states) of the student aligns with the stabilized teacher.
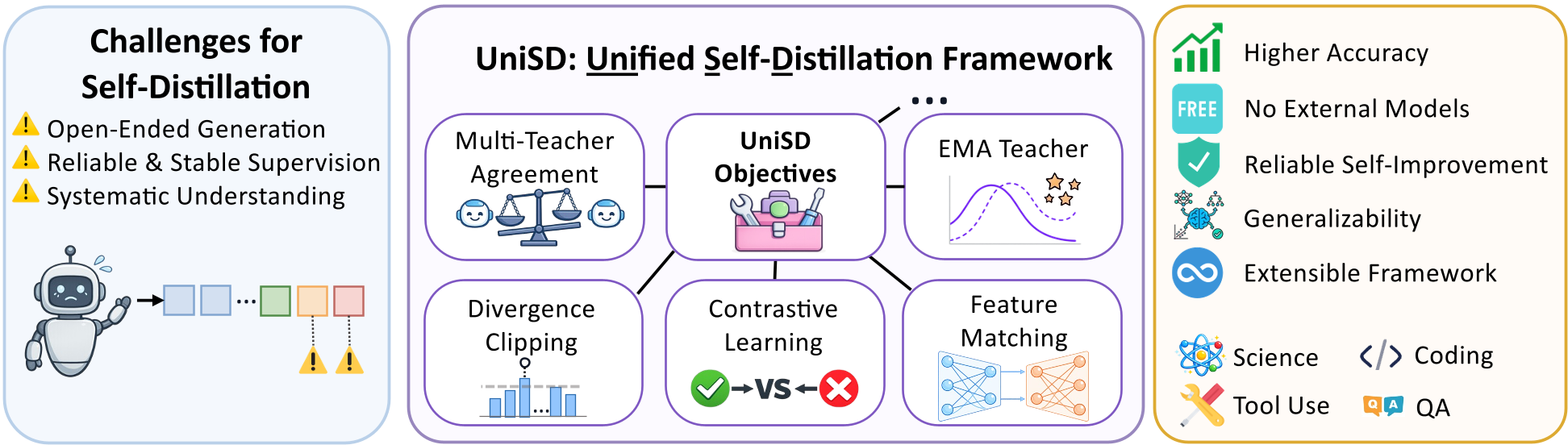 Figure 1: The UniSD Framework components working in concert to enable reliability-aware self-correction.
Figure 1: The UniSD Framework components working in concert to enable reliability-aware self-correction.
Experiments: Superior Gains Across the Board
The researchers tested UniSD on everything from Science QA to Python coding. The results were clear: UniSD consistently wins.*
- Domain Mastery: On ToolAlpaca (tool usage), UniSD* achieved a massive +16.1 improvement over the raw model.
- Zero-Shot Generalization: On GPQA (Expert-level physics/bio), the model showed it could transfer its self-learned logic to harder, unseen problems better than any baseline.
- Preserving the "Base" Model: One common fear in fine-tuning is "catastrophic forgetting." UniSD* actually reduces distribution drift. As shown in the figures below, UniSD* completions remain much closer to the base model's natural distribution compared to standard SFT.
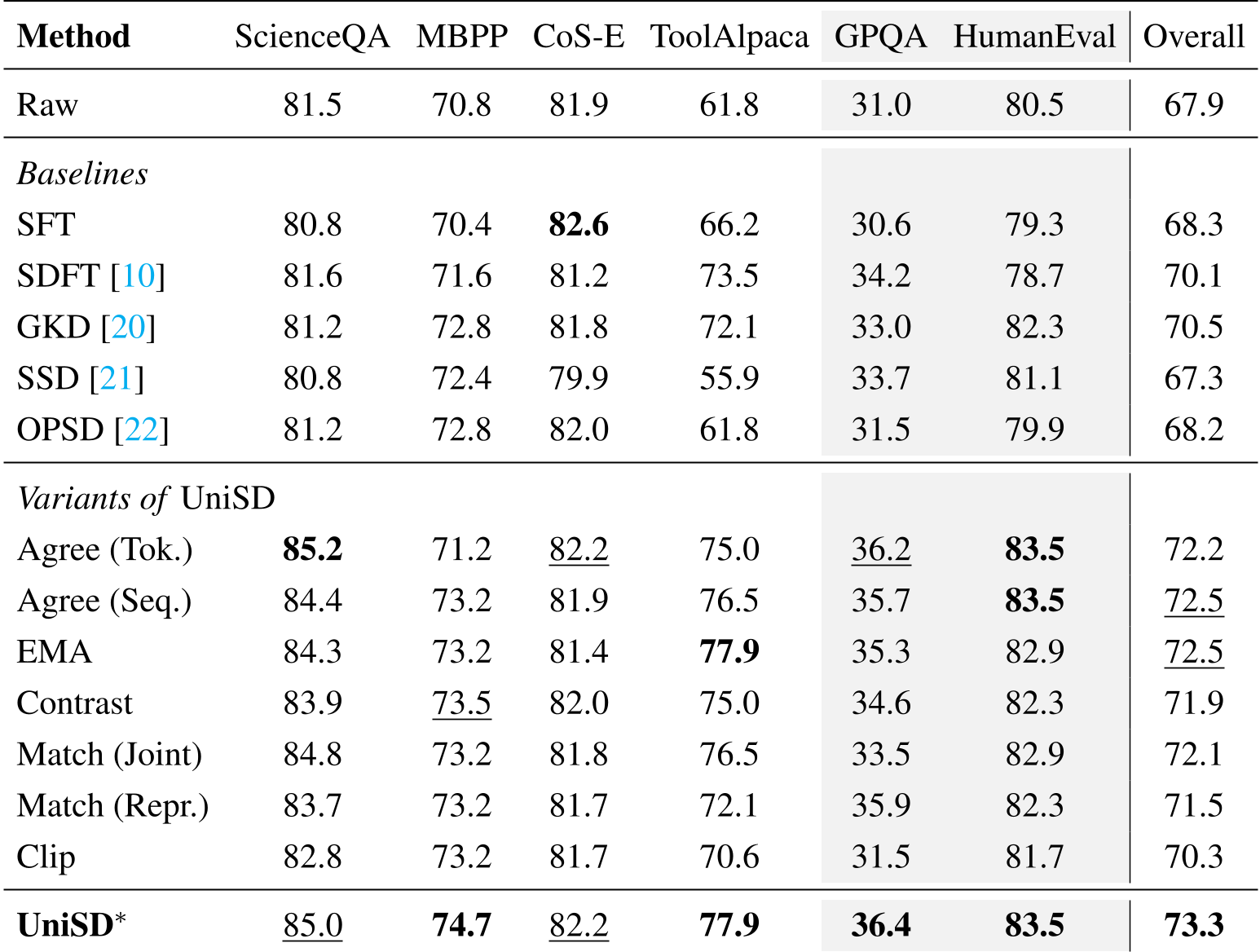 Table 1: Benchmark performance showing UniSD outperforming SFT and prior self-distillation SOTA like GKD.*
Table 1: Benchmark performance showing UniSD outperforming SFT and prior self-distillation SOTA like GKD.*
Deep Insight: Why EMA and Agreement Matter
The study reveals a fascinating trade-off. Token-level agreement is aggressive and finds high-quality local signals, but Sequence-level agreement is more stable for general tasks. Interestingly, the EMA Teacher emerged as the strongest single component for stability, proving that in self-evolution, "slow and steady" updates prevent the model from spiraling into hallucinations.
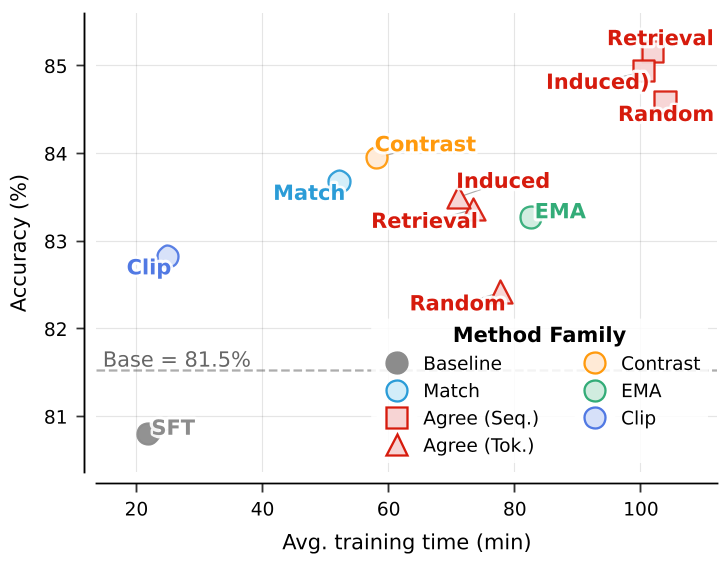 Figure 2: Component effectiveness and loss curve analysis. UniSD (full framework) provides the most robust path to accuracy.*
Figure 2: Component effectiveness and loss curve analysis. UniSD (full framework) provides the most robust path to accuracy.*
Conclusion & Future Outlook
UniSD proves that LLMs contain more latent knowledge than they let on. By using self-distillation, we can "unravel" this knowledge without needing a trillion-parameter overseer.
Limitations: The primary bottleneck is compute. Multi-teacher agreement requires multiple passes, making it roughly 5x slower than standard SFT. However, the authors suggest this can be optimized by only using expensive "agreement checks" on high-uncertainty samples.
The path to truly autonomous AI involves models that can critique and refine themselves. UniSD is a major step toward that self-sustaining future.