本文提出了一种名为 STTS (Spatio-Temporal Token Scoring) 的轻量级视频视觉语言模型(VLM)剪枝策略。该方法通过统一的评分机制,在 ViT 编码器和 LLM Reasoner 中同步减少 50% 的视觉 Token,在保证性能几乎无损的情况下,将训练和推理效率提升了 62% 以上。
TL;DR
在处理长视频时,Vision-Language Models (VLMs) 往往会因为海量的视觉 Token 而“喘不过气”。本文提出的 STTS (Spatio-Temporal Token Scoring) 模块,是一个可端到端训练的“聪明剪刀”。它能在 ViT 早期阶段识别出哪些像素块是背景、哪些是静止冗余,从而一举剪掉 50% 的 Token,使推理速度提升 1.6x - 2.2x,而 QA 准确率几乎无损。
背景定位:这是针对视频 VLM 计算瓶颈的一次“全路径优化”,打破了业界此前只能在 ViT 或 LLM 单侧剪枝的僵局。
痛点深挖:消失的计算力去哪了?
当前的视频 VLM(如 LLaVA, Molmo 等)通常由一个 ViT 编码每帧图像,再送入 LLM 进行推理。问题在于:
- 时空双重冗余:视频中背景往往是静止的,或者某些帧根本不包含关键动作。
- 两头堵:以前的方法,要么只管 ViT(不管下游任务,剪错了关键信息),要么只在 LLM 前剪(ViT 还是要老老实实在前几层算一遍所有帧)。
- 稀疏性难题:剪枝后的 Token 是稀疏非均匀的,在 PyTorch 等框架下直接计算并不能真正省时间。
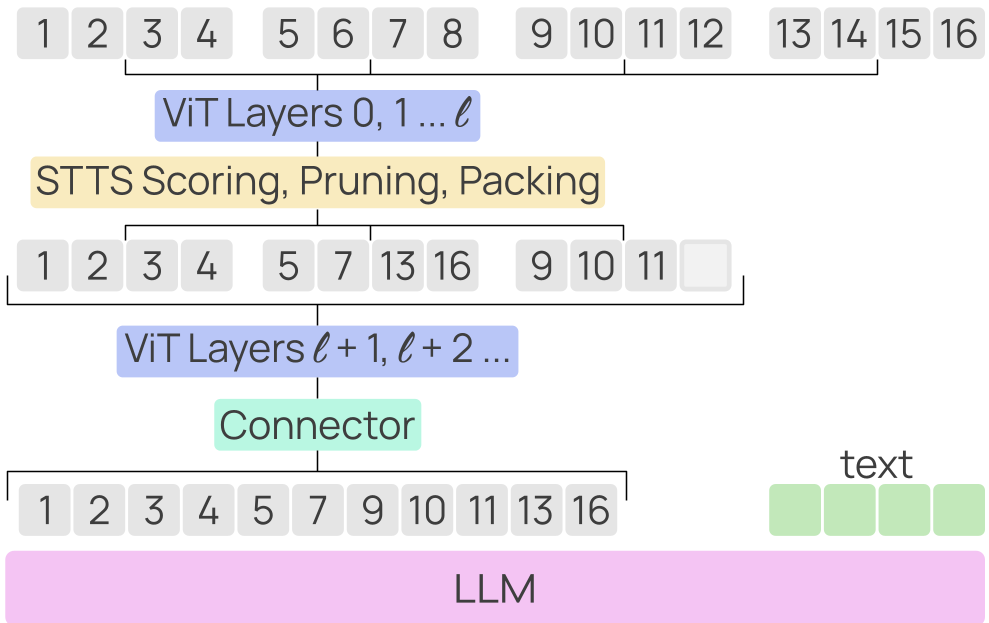
核心方法:TTS 如何实现“内外兼修”?
STTS 不是简单的阈值过滤,它是一个包含评分、打包、约束的三位一体架构。
1. 双轴评分 (Dual-Axis Scoring)
STTS 插入在 ViT 的前几层(如第 3 层)之后。它的评分依据两个维度:
- 空间轴(听 LLM 的话):通过将分数值注入到下一层 ViT 的
Attention Bias中,LLM 的分类/生成梯度可以反向传导给 Scorer。这让模型知道:为了回答问题,哪些区域是关键的“锚点”。 - 时间轴(听余弦相似度的引导):引入一个辅助损失 ,对比前后两帧对应位置的特征。如果两块内容很像,就给低分(视为冗余)。
2. 硬件加速黑科技:Token Packing
为了让剪枝真正转化为速度,作者引入了 First-Fit Descending (FFD) 算法。 由于不同帧被减掉的 Token 数量不等(变长序列),STTS 将这些残留 Token 像塞积木一样,重新打包进整齐的稠密张量中,并生成对应的 Block-diagonal 掩码确保注意力机制不跨样本混淆。
实验结果:速度飞升,精度依然“垂直”
作者在 Molmo2 基础上进行了验证,覆盖了 13 个主流视频评测集(包括 NextQA, VideoMME 等)。
- 甜蜜点 (Sweet Spot):剪枝 30% 时,模型在多项任务上反而超过了 Baseline。这是因为 STTS 过滤掉了视觉噪声,让 LLM 关注力更集中。
- 大负载下的爆发:在处理 256 帧的长视频时,SSM 的优势被无限放大。得益于 Transformer 处理序列的二次复杂度,减一半 Token 能换来 225% 的训练加速。

可视化分析:它到底剪掉了什么?
在下图中,STTS 表现出极强的语义理解力:
- 在游戏视频中,它会保留移动角色和平台,剔除静止背景。
- 在真人视频中,它能精准识别面部微表情的变化,而简单的 Heuristic 算法(启发式)则会误把人脸当背景删掉。

深度洞察:为什么 STTS 能成功?
STTS 的成功在于它解决了“信息损失”与“效率”的矛盾。通过测试时缩放 (Test-Time Scaling),我们可以用同样的算力处理比以前多一倍的帧数(比如从 64 帧扩展到 128 帧),这在长视频 QA 下带来了额外的 1% 性能增益。
局限性:尽管目前在 4B 参数模型上效果显著,但在更大规模(如 70B+)模型上的剪枝行为逻辑是否会发生“突变”,仍需验证。此外, packing 算法虽然在 T 较小时开销可忽略,但在极端长序列下仍有优化空间。
总结
STTS 为我们提供了一个极具参考价值的范式:视觉冗余的消除不应在 LLM 之外独立进行。 只有让视觉编码器“感知”下游需求,让“眼睛”和“脑子”联动,才能在算力荒的时代真正实现高效的视频智能。