本文提出了 UniGRPO,这是一个统一的强化学习框架,旨在通过联合优化自回归(AR)文本生成和流匹配(Flow Matching)视觉生成,提升推理驱动的多模态交错生成质量。该方法在 Bagel 模型基础上实现了 SOTA 的文字-图像对齐效果,并在 GenEval 榜单上达到 0.90 的高分。
TL;DR
字节跳动与香港中文大学联合推出来的 UniGRPO,首次实现了将语言模型的“链式思考”(CoT)与流匹配(Flow Matching)视觉生成过程在同一个强化学习(RL)框架下进行端到端优化。通过将生成过程建模为统一的高效 MDP,模型不仅生成的图像更漂亮,更重要的是,它能通过“思考”准确理解复杂的空间和属性指令,在 GenEval 榜单上刷出了 0.90 的顶级战绩。
背景定位:多模态后训练的新坐标
当前 AI 社区正逐渐收敛到一种架构共识:用自回归(AR)模型处理文本,用流匹配(Flow Matching)处理图像。然而,如何让这两者真正“心往一处想”? UniGRPO 的出现,填补了这一空白。它不像以前的工作那样将逻辑推理(Text)和像素合成(Image)拆开练,而是通过 Group Relative Policy Optimization (GRPO) 算法,根据最终的图像质量反馈,强制模型在生成图像前“想清楚”该画什么。
痛点深挖:为什么以前的 RL 练不好图文生成?
- 奖励欺骗 (Reward Hacking):在扩散或流模型中,稍微过度优化就会导致色彩过饱和或出现诡异的网格伪影。
- CFG 的计算灾难:为了效果,推理通常需要 Classifier-Free Guidance,但 RL 训练时的多次分支采样会让显存直接爆炸,难以扩展到多轮对话。
- 模态断层:SFT 后的模型虽然会写
<think>,但它的思考内容往往跟后面画的图没啥关系。
UniGRPO 核心方法论:极简而有力
UniGRPO 采用了“简约而不简单”的设计哲学,将 Prompt -> Thinking -> Image 统一为一个 MDP。为了解决上述痛点,作者提出了两个关键的技术改造:
1. 速度场正则化 (Velocity-Based Regularization)
传统的 KL 散度在流模型中由于时间步噪声不均,容易留下“漏洞”让模型钻空子(即 Reward Hacking)。UniGRPO 创新地在 速度场 (Velocity Fields) 上直接施加 MSE 惩罚:
L_MSE = || v_θ(x_t, t, y) - v_ref(x_t, t, y) ||²
这种方法在所有噪声水平上提供了均匀的约束,实验证明它能有效抑制伪影,让图像保持 photorealistic。
2. 彻底摆脱 CFG
为了工程化扩展,UniGRPO 在训练阶段完全去掉了 CFG。
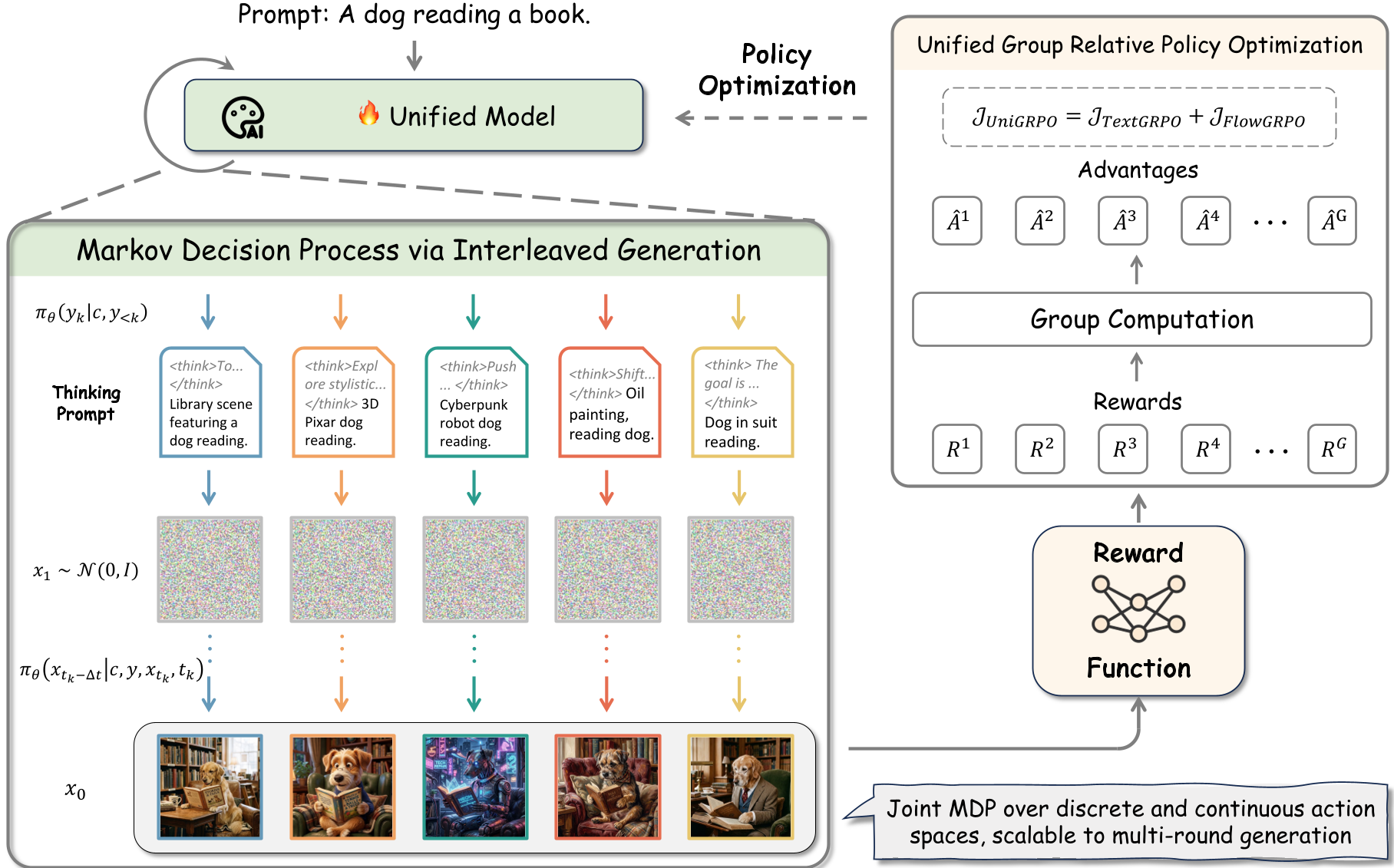 图 1:UniGRPO 概览。通过统一 MDP 联合优化离散语言动作和连续视觉动作。
图 1:UniGRPO 概览。通过统一 MDP 联合优化离散语言动作和连续视觉动作。
这样做的好处是生成过程变成了线性的、无分支的(Unbranched),极大降低了计算开销。神奇的是,因为 RL 显式优化了对齐奖励,模型在不开启 CFG 的情况下,对齐能力反而比开启 CFG 的基线更强。
实验与战绩
作者在 Bagel 模型上进行了验证。在包含 150 个复杂多样提示词的 TA Benchmark 上,UniGRPO 显著超越了 ReFL 和 DPO 等强基线。
| 方法 | Thinking | TA Score (对齐) | GenEval (综合) | | :--- | :--- | :--- | :--- | | Bagel Basline | ✓ | 0.7132 | 0.79 | | SFT 增强版 | ✓ | 0.7769 | 0.82 | | UniGRPO (Ours) | ✓ | 0.8381 | 0.90 |
 图 2:UniGRPO 生成示例。即便面对“三座领奖台不同高度和数字”这种高难度逻辑,也能精准复现。
图 2:UniGRPO 生成示例。即便面对“三座领奖台不同高度和数字”这种高难度逻辑,也能精准复现。
推理链的进化
通过对比可以发现,SFT 模型的推理往往是“废话”,而 UniGRPO 训练后的推理过程变得非常任务导向。例如在处理“六个杯子俯视图”时,模型会先在 <think> 里明确指出“目标是展示六个陶瓷杯,整齐分布在两行三列”,然后在图像生成阶段严格执行这一逻辑。
深度洞察:为什么这很重要?
UniGRPO 告诉我们:视觉模型不需要 CFG 这种“补丁”技术也可以画得很好,前提是你有足够大、足够稳的 RL 框架。同时,它证明了 LLM 的推理能力可以被“泵入”到像素级生成中。
局限性与展望
文章客观提到,目前的奖励仍然是终端稀疏奖励(只看最后出的图好不好)。这可能导致“歪打正着”的情况——推理错了但图画对了。未来的研究方向将引入 多模态过程奖励模型 (PRM),对每一段“思考”进行打分,这将进一步提升推理的合规性和模型的可靠性。
总结:UniGRPO 为多模态模型的 Post-training 指明了方向:不要分别优化,要通过一个统一的 MDP 让语言和视觉在 RL 的洪流中共同进化。