本文提出了 UniMesh,这是一个首个将 3D 理解与生成任务深层耦合的统一框架。通过创新的 Mesh Head 接口连接 BAGEL 扩散模型与 Hunyuan3D 解码器,UniMesh 实现了在单一架构内完成 3D 资产的高质量生成、语义编辑(Chain-of-Mesh)及自我反思式文本描述。
TL;DR
UniMesh 是一个将 3D 理解与 3D 生成合二为一的领先框架。它不仅能根据文字生成高清 3D 模型,还能让你像修改文档一样,通过对话不断调整模型的细节(例如“给这个狮子加个王冠”)。通过创新的 Mesh Head 接口和 Chain-of-Mesh (CoM) 迭代机制,UniMesh 实现了 3D 创作中的“感知引导生成”。
背景:碎片化的 3D 愿景坐标系
在当前的 AI 领域,3D 任务被分成了两个互不通气的阵营:
- 生成派:专注于如何从一张图或一段话快速拍出一个 3D 模型。
- 理解派:专注于如何给 3D 模型写简介、做分割。
这种隔离导致了一个尴尬的问题:生成模型就像一个“没有感官”的画家,画完就走,无法根据反馈进行修改;而理解模型空有火眼金睛,却无法直接指导创作。UniMesh 的出现,正是为了建立一个闭环系统。
核心方法论:UniMesh 是如何炼成的?
1. Mesh Head:跨越维度的“翻译官”
传统的 3D 生成往往需要先生成一张 RGB 图片,再根据图片建模。这中间会丢失大量的细节。UniMesh 设计了一个 Mesh Head,它直接在“潜空间(Latent Space)”进行翻译,把 BAGEL 内容模型的信号直接传给 Hunyuan3D 几何解码器,绕过了中间商(RGB 像素),保真度大大提升。
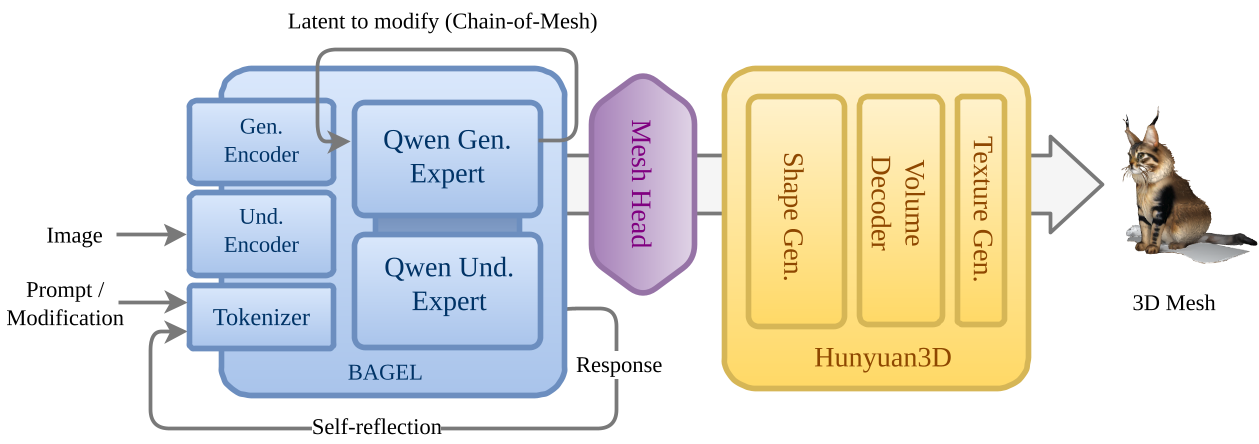 UniMesh 总体架构图:展示了如何通过 Mesh Head 将生成与理解路径打通
UniMesh 总体架构图:展示了如何通过 Mesh Head 将生成与理解路径打通
2. Chain-of-Mesh (CoM):3D 界的思维链
这是本文最惊艳的部分。作者提出了 Chain-of-Mesh (CoM)。当你想修改已生成的 3D 模型时,算法会保留上一步的视觉特征,结合你的新指令(例如“把摩托车改成红色”),在潜空间内进行微调。这个过程不需要重新训练模型,完全是零样本(Zero-shot)的推理过程。
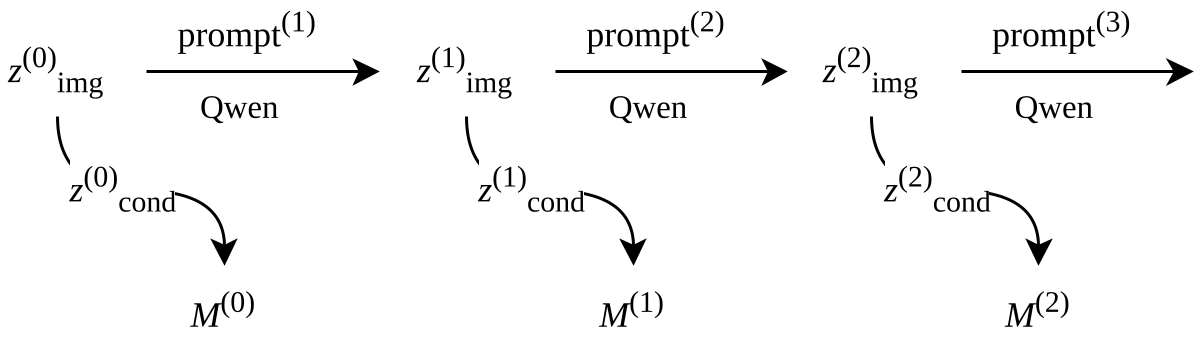 CoM 机制通过“潜空间-提示词-再生成”的闭环,实现了语义级别的 3D 编辑能力
CoM 机制通过“潜空间-提示词-再生成”的闭环,实现了语义级别的 3D 编辑能力
3. 自我反思机制 (Self-Reflection)
在 3D 理解任务(如生成模型描述)中,UniMesh 引入了“演员-评论家”模式。如果生成的文字描述被判定为不准确,系统会进行“内部反省”,分析出错的原因后重新生成。这种自我改进极大提升了模型在复杂场景下的理解准确率。
关键战绩:实力说话
在 3D 生成领域最权威的 DreamFusion 提示词测评中,UniMesh 的表现强劲:
- 语义准确度:CLIP Image-Text 分数达到 0.296,位居所有开源模型首位。
- 理解质量:FID 分数(衡量描述质量与真实值接近程度)仅为 0.113,远低于 LLaVA-3D 等强力对手。
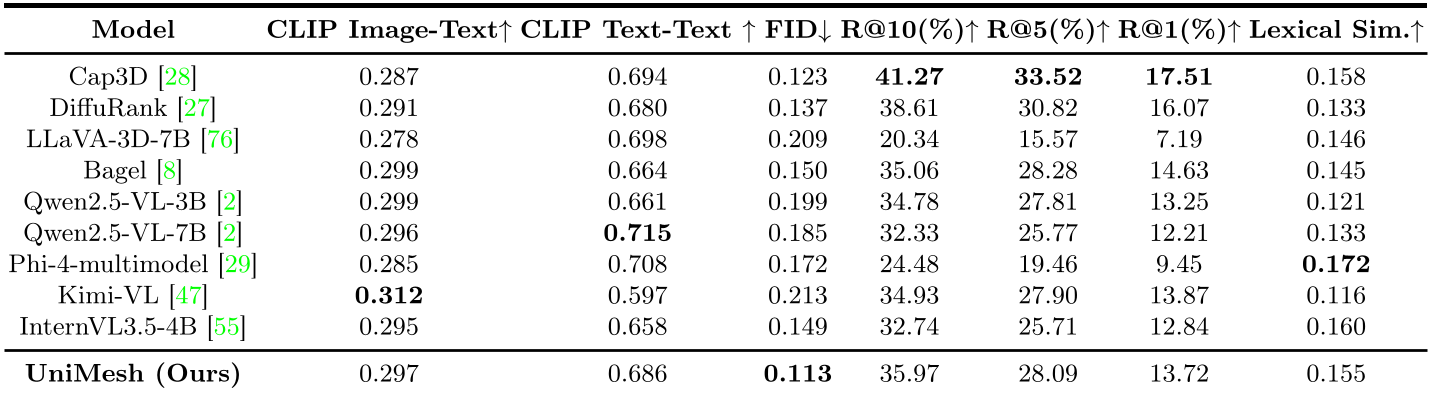 在 3D captioning 任务上,UniMesh 展现出了最均衡的各项指标表现
在 3D captioning 任务上,UniMesh 展现出了最均衡的各项指标表现
深度洞察:为何 UniMesh 能成功?
UniMesh 的成功在于它成功地将 Inductive Bias(归纳偏置) 从单纯的几何规律转向了“语言-视觉-几何”的三重对齐。它告诉我们:一个优秀的 3D AI 不应该只是个建模工具,它必须首先能“读懂” 3D,才能真正“画好” 3D。
总结与未来展望
UniMesh 为实现“全能型 3D 智能”铺平了道路。尽管理论上它仍依赖于 2D 多视角图作为理解的中介,但其在潜空间直接交锋的设计思路极具前瞻性。
结论 (Takeaway):UniMesh 不仅仅是一个新的 SOTA。它通过 Chain-of-Mesh 将 3D 开发从“开盲盒”变成了“可控协作”,这是 3D AIGC 向生产力工具迈进的关键一步。