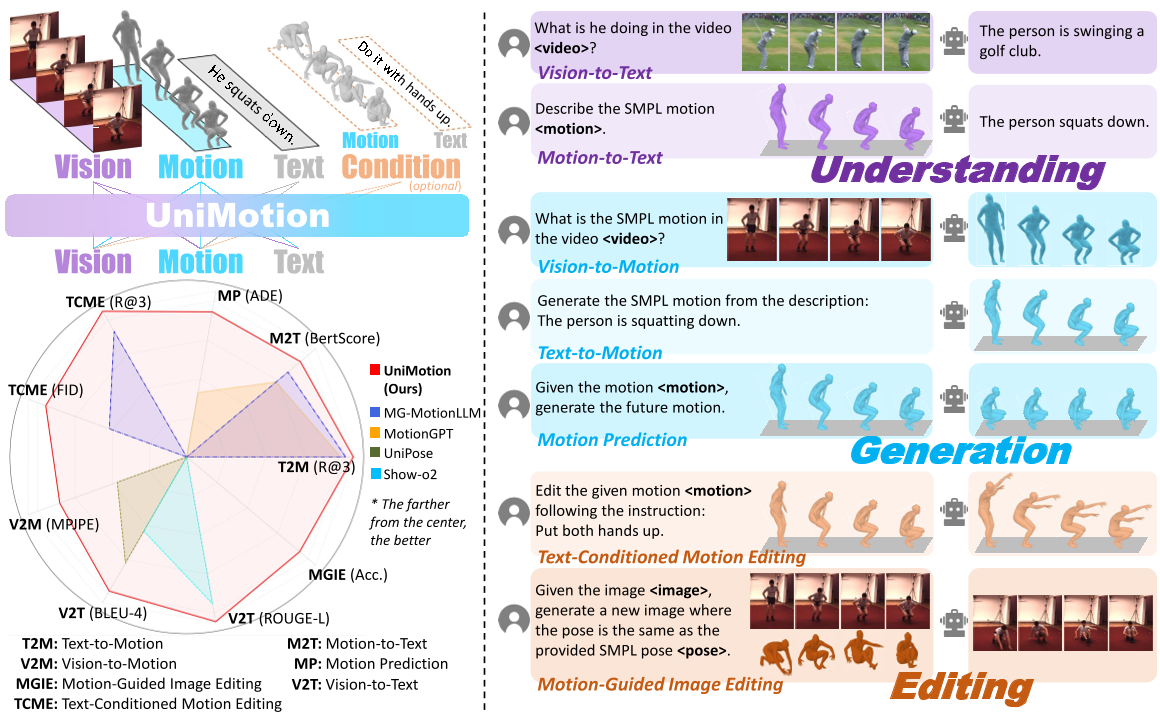
本文提出了 UniMotion,这是首个在统一架构下实现人体运动(Motion)、自然语言(Text)和 RGB 图像(Vision)全模态理解与生成的框架。通过将运动视为与图像平等的连续模态,UniMotion 在包括 T2M、V2M、M2T 在内的 7 项全模态任务上达到了 SOTA 水平。
TL;DR
在过去的一年中,虽然文本和图像的统一模型(如 Show-o, Janus)取得了长足进步,但人体运动(Human Motion)这一关键动态模态始终被排除在主流 MLLM 之外。UniMotion 横空出世,它是第一个在单一架构内实现运动-文本-图像“全对全”(Any-to-Any)理解与生成的统一框架。它摒弃了导致动作僵硬的离散 Token 方案,转而采用全连续路径设计,在 7 项跨模态任务中横扫 SOTA。
痛点深挖:为什么“运动”这么难搞?
现有的工作(如 MotionGPT 或 UniPose)通常面临两个核心瓶颈:
- 量化误差的代价:大多数模型使用 VQ-VAE 将运动转化为类似单词的离散 Token。通过这种方式,运动虽然能像语言一样喂给 LLM,但不可避免地引入了量化误差,导致生成的动作出现“抖动”(Jitter)和细节丢失。
- 监督信号的稀疏性:文本描述(如“一个人在走路”)非常抽象,而运动数据是极其密集的时空坐标。仅靠稀疏的文本去训练模型生成复杂的动作,会导致模型“理解不足”,难以捕捉步幅、协调性等细微特征。
核心方法论:UniMotion 的三项关键创新
1. 连续模态:CMA-VAE 与双路径 Embedder
UniMotion 的核心直觉是:运动应该像图像一样,作为连续特征进行处理。 作者设计了 CMA-VAE (Cross-Modal Aligned Motion VAE)。不同于标准的 VAE,它引入了 DPA (Dual-Posterior KL Alignment) 机制。在训练时,模型同时拥有一个“视觉融合编码器”和一个“纯运动编码器”,通过 KL 散度让后者去模仿前者。这意味着,即使在推理时没有图像输入,运动编码器也已经提前“学习”到了视觉上的语义空间。
在 Backbone 侧,UniMotion 采用了对称的双路径 Embedder:
- Semantic Branch (语义路):负责理解“他在做什么”,类似于 SigLIP。
- Generation Branch (生成路):负责保留骨骼运动的微小细节,类似于 PatchEmbed。
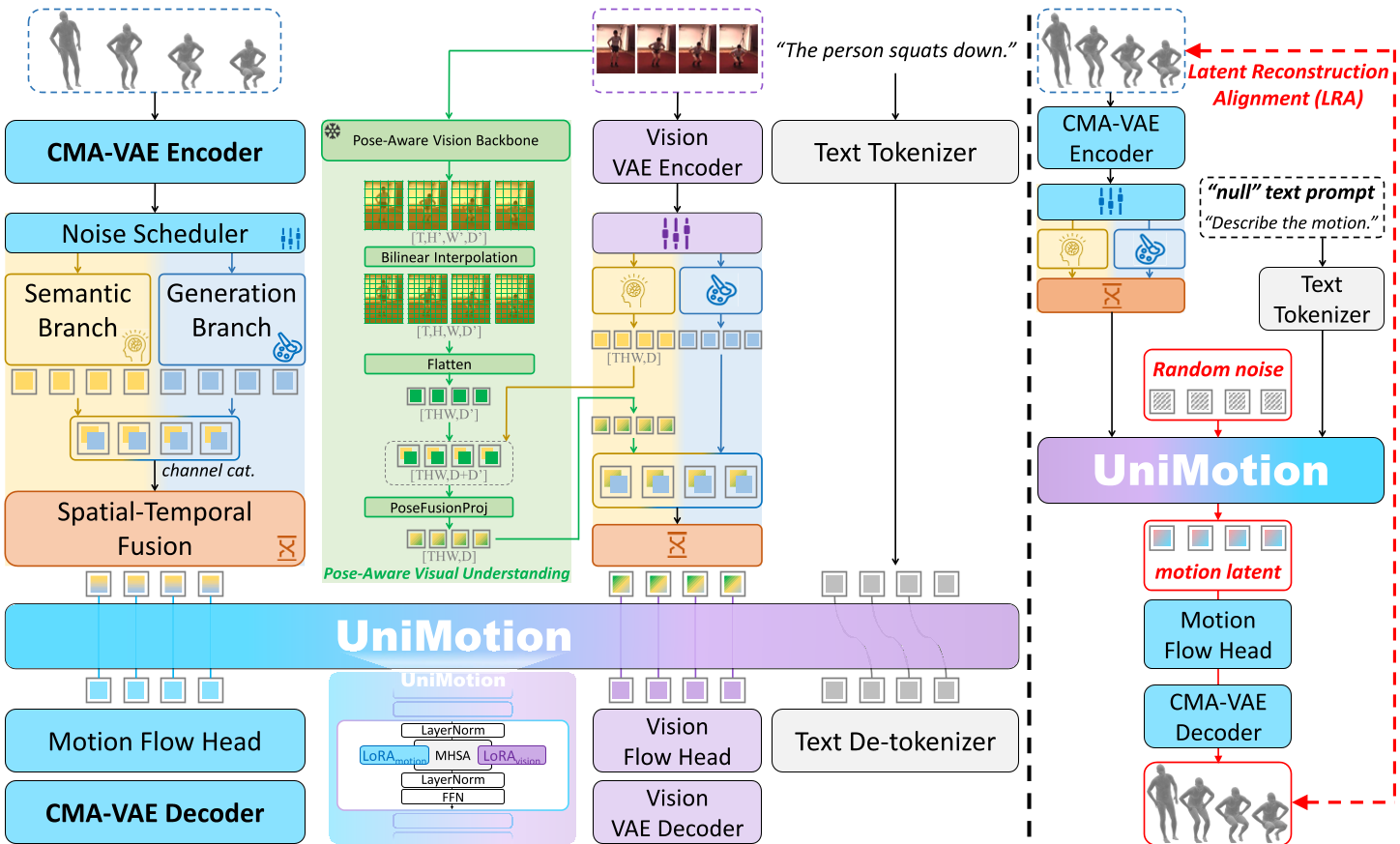
2. 潜在重构对齐 (LRA):解决冷启动问题
模型在刚开始学习“运动”和“文本”对齐时非常痛苦。UniMotion 提出了 LRA (Latent Reconstruction Alignment)。 这是一种自监督预训练策略:让模型尝试从噪声中重构出自身的运动潜变量 $z$。由于 $z$ 本身是密集的运动特征,这种“自我重构”任务为模型提供了精准且无歧义的几何监督,为后续复杂的跨模态对齐打下了坚实的基础。
3. 混合注意力与模态路由 LoRA
为了兼容文本的自回归(Autoregressive)特性和运动生成的流匹配(Flow Matching)特性,UniMotion 引入了:
- Hybrid Attention:在运动 Token 内部允许全局双向关注,而整体序列保持因果序。
- Modality-Routed LoRA:为运动和文本/视觉分别分配独立的低秩适配器(LoRA),极大地提升了多任务下的参数效率。
实验与结果:全维度的统治力
UniMotion 在包括 T2M (文本生运动)、M2T (运动描述)、V2M (视觉提炼运动) 等在内的七项任务中均表现优异。
1. 语义精准度
在 Motion-to-Text 任务中,UniMotion 的 BertScore 达到了 41.2,远超之前的基线模型。这意味着它生成的描述不再是干巴巴的模板,而是能精准捕捉动作的细节(如“逆时针转圈”而非简单的“走路”)。
2. 运动生成质量 (T2M)
通过 CMA-VAE 的连续表征,UniMotion 生成的动作极其平滑且符合物理常识。

3. 突破性任务:MGIE
UniMotion 首次在单一潜空间内实现了运动引导的图像编辑 (MGIE)。用户可以给定一张图片和一个动作序列,模型能够直接生成该人物执行该动作后的图像,而无需显式渲染骨架图或借助中转文本。
深度洞察与总结
为什么 UniMotion 奏效了? 本质上,它解决了跨模态对齐中的“分辨率”失配问题。传统的离散 Token 方案试图强行平滑化运动数据的复杂多样性,而 UniMotion 拥抱了连续性。它的 DPA 和 LRA 策略实际上是在建立一个“视觉-几何-语义”三者交织的流形空间。
局限性: 尽管 1.5B 的参数规模在手机或端侧设备上仍有压力,且对极复杂背景下的视觉运动对齐有待加强,但 UniMotion 为未来更强大的人体感知 AI 描绘了蓝图。
总结: UniMotion 不仅仅是一个刷榜模型,它成功地将人体运动这一“动态语言”编织进了大语言模型的版图中,这对于未来具身智能、元宇宙动画制作以及动作康复领域都具有里程碑式的意义。