本文提出了 UniQueR,一个统一的基于 Query 的 3D 重建前馈框架。该方法通过学习一组紧凑的 3D 锚点作为显式几何查询(Queries),在无需场景优化的情况下,实现了从无位姿图像中高效、准确地生成 3D Gaussian Splatting 表示。
TL;DR
UniQueR 是一款革新性的前馈 3D 重建框架,它放弃了传统的 2.5D 像素对齐逻辑,转而采用 3D 稀疏查询 (Sparse 3D Queries)。该模型能够从几张未经標定的照片中,一秒内“脑补”出完整的 3D 高斯场景(3D Gaussian Splatting),即便是在遮挡区域也能实现精准补全。相比前代 SOTA 方法,它在显存占用减少 40% 的同时,推理速度提升了 2.4 倍。
背景定位:前馈重建的“末梢神经”痛
当前的 3D 重建领域正经历从“逐场景优化”(如原始 3DGS, NeRF)向“通用前馈预测”(Feedforward)的范式转移。然而,像 DUSt3R 或 AnySplat 这样的明星模型,本质上还在做 2.5D 的延伸:它们预测的是像素对齐的点云。
这种方式存在两个致命伤:
- 视角依赖(View-anchored):模型只能看到镜头视野内的表面。如果视角没覆盖到某个角落,重建结果就会出现巨大的“空洞”。
- 冗余噩梦:随着输入分辨率提升,生成的 3D 基元(Primitives)数量呈指数级爆炸,显存动辄溢出。
UniQueR 的核心直觉是:既然 3D 空间是连续且统一的,我们为什么不直接在 3D 空间中布置一组“传感器”(Queries),让它们自己去图像里找特征,然后长出几何体呢?
核心机制:3D Query 与解耦注意力
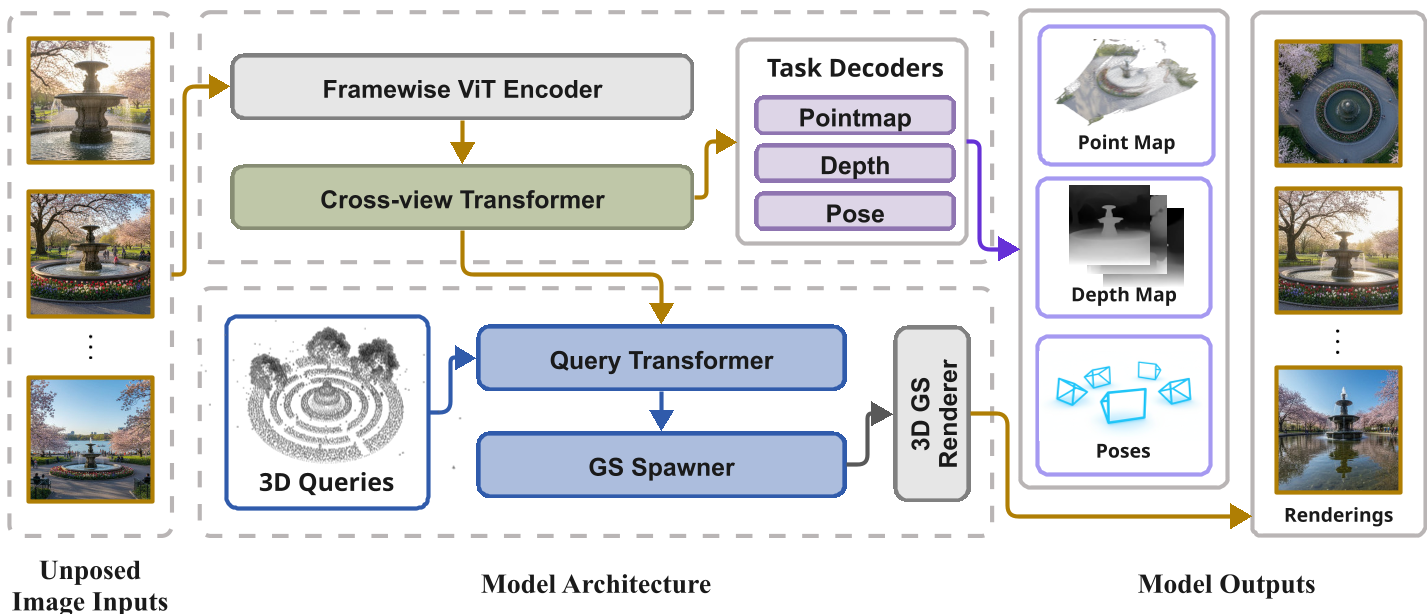
1. 架构逻辑
UniQueR 并不直接预测每个像素的深度,而是维护一组 3D Anchor Points。这些锚点作为 Query,通过 解耦交叉注意力 (Decoupled Cross-attention) 模块,从多张输入图像的 Vision Transformer (ViT) 特征中抽取信息。
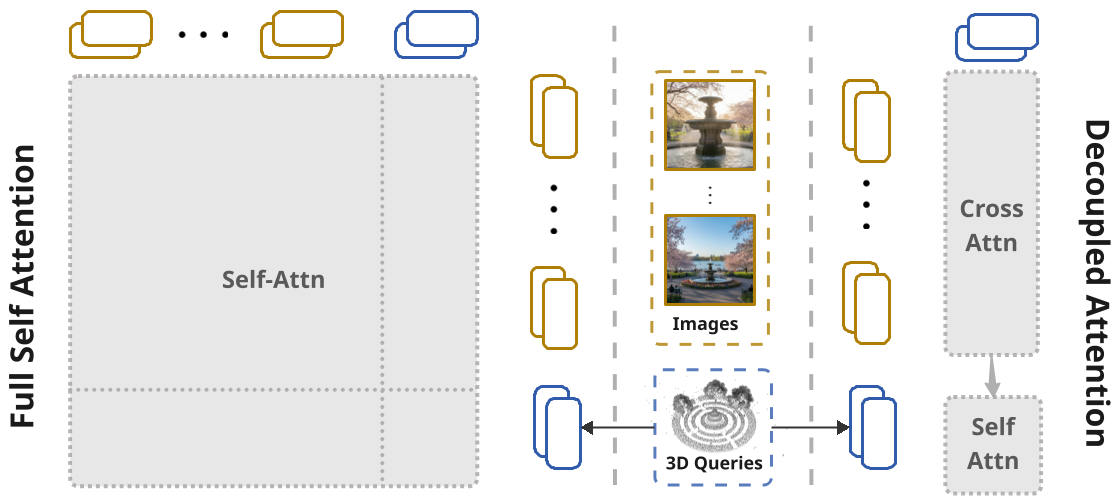
2. 解耦注意力的物理直觉
传统的全注意力机制复杂度是 $O(N^2)$,当图像视角增多时,计算量不可接受。UniQueR 采用了 Queries-to-Images Cross-Attn + Queries Self-Attn 的设计。这种设计让计算开销主要取决于稀疏的 Query 数量,而非密集的图像像素,从而轻松处理 60+ 视角的输入。
3. 混合初始化:让模型更稳
单纯的随机 Query 初始化在 3D 重建中极易崩盘。作者设计了一个“双道初始化”:
- 前半部分:从预训练生成的粗糙点云中采样,确保 Query 落在物体表面。
- 后半部分:在 3D 空间均匀采样,给模型预留探测隐藏区域的“种子”。
实验与结果:小样本下的逆袭
UniQueR 的表现堪称惊艳。即使在只有 3-6 张输入视角的极端情况下,其 NVS(新视角合成)的图像质量依然大幅领先。
关键战绩:
- 精度:在 Mip-NeRF 360 数据集上,PSNR 提升了约 2-4dB。
- 效率:仅需约 260K 个高斯点,而同类方法通常需要数百万个。这使得它在单张 A100 上运行极其顺滑。
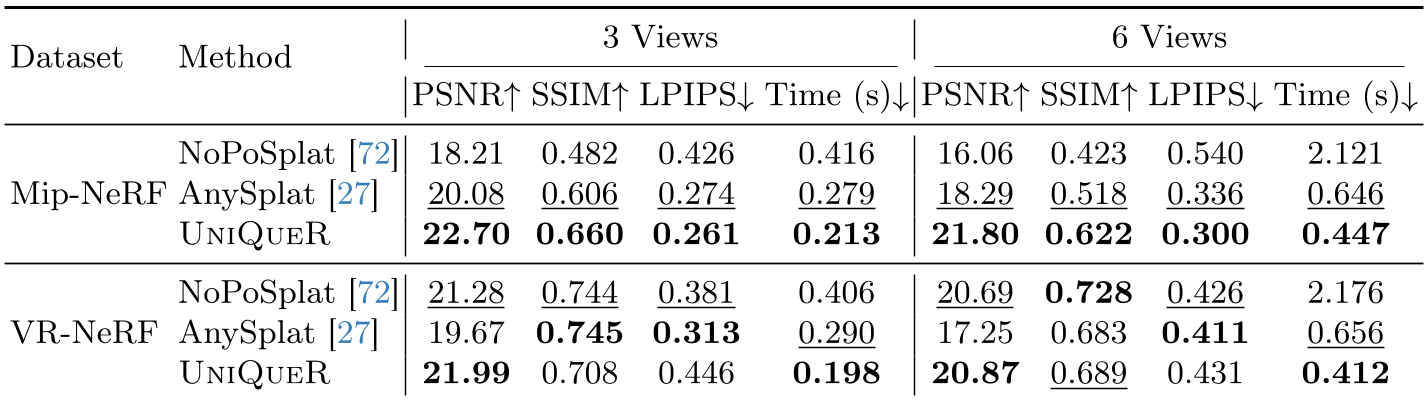
从定性结果看,UniQueR 生成的深度图边缘锐利,且在 AnySplat 产生“空洞”的地方(遮挡区),UniQueR 依然能给出合理的几何填充。
深度洞察:为什么 Query 胜过了像素对齐?
像素对齐(Pixel-aligned)本质上是 Inductive Bias(归纳偏置) 的一种强约束,它假设 3D 结构必须紧贴在 2D 像素后面。这在处理闭塞、稀疏视角时反而成了枷锁。UniQueR 通过 Global 3D Query 解开了一对一的束缚,让模型学习到了更高阶的场景先验——就像人类观察物体,即使只看正面,也能推断出背面大概的样子。
总结与局限
UniQueR 证明了:质量不一定要靠堆砌原语(Primitives)来实现。通过更聪明的 Query 机制和时空解耦,我们可以用更少的代价换取更完整的 3D 世界建模。
局限性:目前 UniQueR 专注于静态场景。在动态物体的实时补全上,如何保持 Query 的一致性,将是下一个值得攻克的学术哨所。
本文主编点评:UniQueR 不仅仅是一个 SOTA 的刷榜工具,它通过 Query 机制重新审视了前馈重建的几何表现力,是 3D 重建向大规模具身智能迈进的重要一步。