本文提出了 UniScale,一个针对搜索排序模型 Scaling Law 的协同设计框架。该框架同步扩展全空间(Entire-Space)数据规模并优化模型架构,在阿里巴巴淘宝搜索的大规模工业场景中显著突破了纯模型参数缩放的性能瓶颈。
TL;DR
在 LLM 时代,Scaling Law(缩放法则)被视为提升模型能力的金科玉律。然而在工业级搜索排序领域,单纯堆砌参数往往会撞上“收益递减”的南墙。阿里巴巴团队在 UniScale 论文中指出:由于训练样本的局限性,强大的架构往往在贫瘠的数据上无用武之地。 UniScale 通过 ES3 数据系统将全空间(搜索+推荐+广告等)异构数据注入训练集,并通过 HHSFT 架构解决数据冲突,从而在淘宝搜索中实现了 GMV 2.04% 的显著提升。
1. 痛点:为什么单纯增加参数不灵了?
传统的搜索排序模型(Ranking Models)通常只在“已曝光”的样本上训练。这导致两个致命问题:
- 样本选择偏置 (Selection Bias):模型只见过被筛选出的商品,没见过海量的未曝光商品,导致推理时对全量候选集的预测不准。
- 信息容量瓶颈:搜索域的点击数据相对于用户的全域行为(如在推荐页的浏览)只是冰山一角。单纯扩大模型,就像在枯竭的油井里安装更强大的抽油机,效率不升反降。
2. ES3:全空间数据的“炼金术”
为了给模型提供更充足的“燃料”,作者设计了 ES3 (Entire-Space Sample System)。
样本与标签的双重扩张
ES3 不满足于只看搜索点击。它引入了:
- 域内样本扩展:将请求上下文中的“未曝光”商品作为训练样本,通过层级标签归因将跨域的转化信号(比如在推荐页买了搜索过的东西)反馈给这些样本。
- 跨域样本“搜索化” (Searchification):这是最有创意的部分。作者将推荐系统中的交互记录转化为“伪搜索”样本。通过构建负样本和生成语义匹配的虚拟 Query,扩充了训练集的覆盖面。
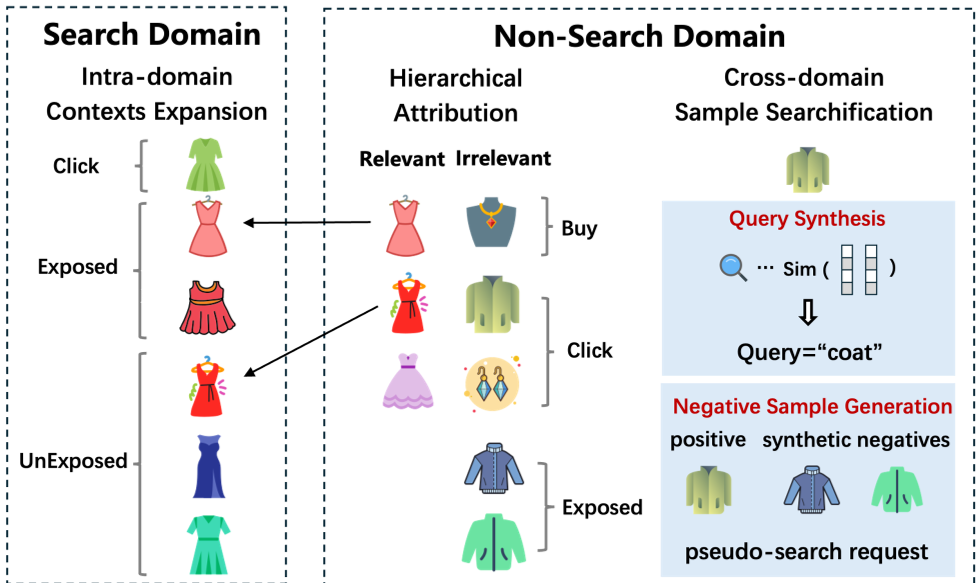 图 1:ES3 系统如何将搜索内与跨域样本进行统一建模
图 1:ES3 系统如何将搜索内与跨域样本进行统一建模
3. HHSFT:为异构数据打造的“变压器”
引入了跨域数据后,分布不一致(Negative Transfer)成了新挑战。作者提出了 HHSFT (Heterogeneous Hierarchical Sample Fusion Transformer)。
核心机制拆解:
- HHFI (异构层级特征交互):针对 e-commerce 中的 ID 特征、数值特征、序列特征,HHSFT 摒弃了传统的共享 QKV 映射。它为每种特征块(Block)分配独立的投影矩阵和 FFN,保留了特征的原始语义空间,随后再进行全局 Attention 融合。
- ESUIF (全空间兴趣融合):
- Domain-Routed Expert Fusion (DREF):采用硬路由(Hard Routing)机制。共享专家学习通用模式,域专属专家学习特定分布,从根源上隔离噪声。
- DAPGA (领域感知个性化门控):利用用户静态特征和领域特征生成门控向量,自适应地调节跨域知识向搜索主任务的迁移比例。
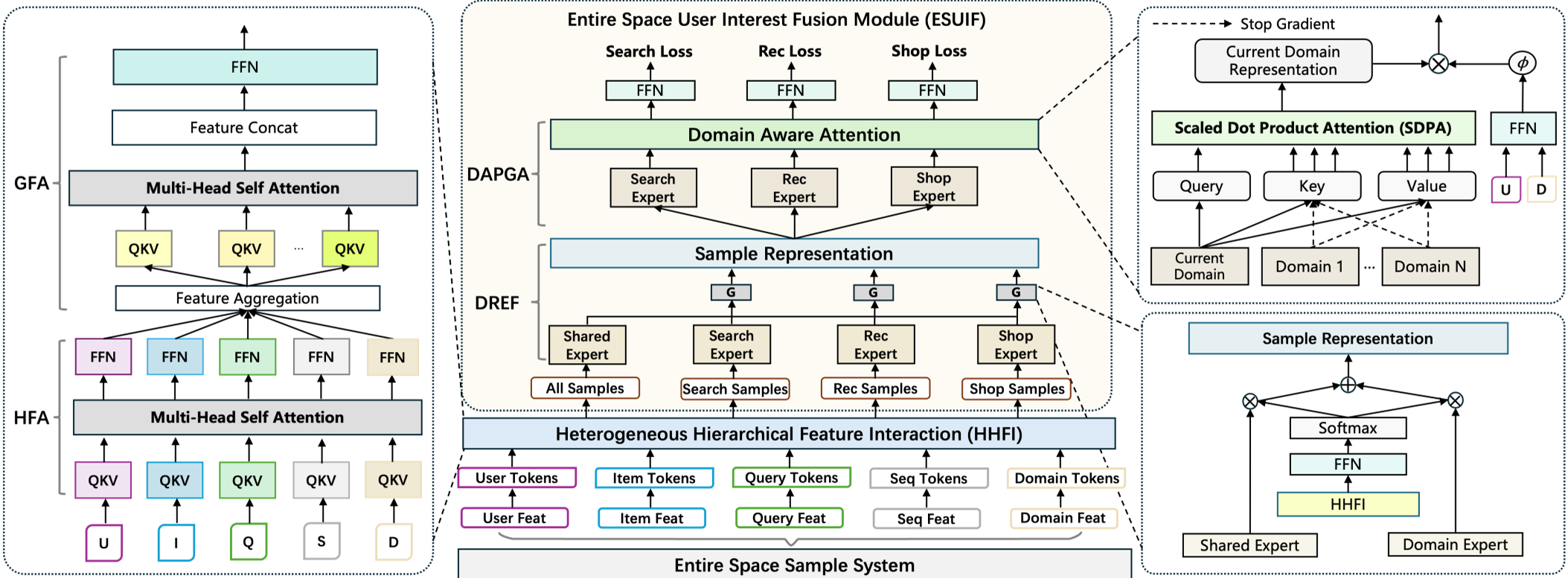 图 2:HHSFT 架构,展示了从特征分词到多域专家融合的完整链路
图 2:HHSFT 架构,展示了从特征分词到多域专家融合的完整链路
4. 实验验证:协同缩放的力量
论文中最令人印象深刻的结论在于协同效应 (Synergistic Effect)。
如下图所示,当使用 ES3 全空间数据时(红色曲线),随着模型参数规模的扩大,其 AUC 的提升幅度(+0.32%)远高于仅使用搜索数据(橙色曲线,+0.12%)。这证明了:更强的数据需要更强的模型去消化,而更强的模型只有在更丰富的数据下才能体现其价值。
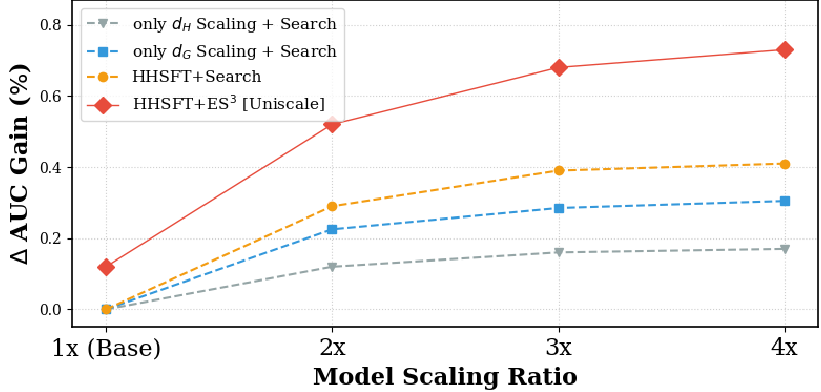 图 3:不同样本设置下,模型性能随参数缩放的变化趋势
图 3:不同样本设置下,模型性能随参数缩放的变化趋势
5. 总结与启示
UniScale 的成功证明了,在工业互联网场景下,Scaling Law 的未来在于 Trinity Scaling(三位一体缩放):样本(Sample)、特征(Feature)与架构(Architecture)的深度协同。对于开发者而言,如何利用好全链路、全空间的异构数据,可能比单纯追求 Transformer 层数更有实际业务产出。
局限性
尽管 UniScale 在提升搜索排序上表现卓越,但其依赖于复杂的线上数据日志采集和跨域对齐系统,且由于引入了 Transformer 架构,对线上推理性能提出了极高要求(虽然文中提到了多项工程优化,但硬件成本依然是不小的门槛)。