本文提出了通用正态嵌入 (Universal Normal Embedding, UNE) 假设,指出生成模型(如 Diffusion)与视觉编码器(如 CLIP, DINO)虽然训练目标不同,但共享一个近似高斯的潜在几何空间。通过引入 NoiseZoo 数据集,作者证明了 DDIM 逆转噪声与语义嵌入之间存在强线性对齐,实现了无需微调的精准语义编辑。
TL;DR
长期以来,AI 界将生成模型(Generative Models)和表征编码器(Encoders)视为两条平行线。然而,来自 Technion 的研究团队在本文中抛出了一个重磅假设:所有的视觉模型都在共享同一个高斯“宇宙”——Universal Normal Embedding (UNE)。研究证明,即便是看似随机的 Diffusion 逆转噪声,也蕴含着极为规律的线性语义。这一发现不仅实现了无需训练的精准图像编辑(如:改笑容、变性别),还为统一计算机视觉的生成与理解提供了全新的几何视角。
1. 痛点:被孤立的潜在空间
在当前的视觉研究中,我们面临一个尴尬的断层:
- 编码器(如 CLIP, DINO):擅长理解语义,但难以直接生成高质量像素。
- 生成模型(如 Stable Diffusion):像素合成能力惊人,但其潜在空间(尤其是初始噪声空间)被认为缺乏语义结构,往往需要复杂的 Prompt Engineering 或 ControlNet 才能控制。
作者追问:既然这些模型都在学习同一个自然图像分布,它们的内心世界(Latent Space)难道没有共通点吗?
2. 核心直觉:UNE 假设与“线性投影”
作者提出了 Universal Normal Embedding (UNE) 假设。其核心物理直觉在于:高斯性(Gaussianity)。
- 生成模型从高斯噪声开始合成。
- 编码器的嵌入在经验上也呈现出高度的高斯分布。
如图 1 所示,作者认为存在一个理想的高斯空间 $Z \sim \mathcal{N}(0, I)$。我们看到的 CLIP 向量或 SD 噪声 $Z_i$,本质上只是这个理想空间经过一个噪声线性投影(Induced Normal Embedding, INE)后的产物: $$\hat{Z}_i = C_i Z + \epsilon_i$$
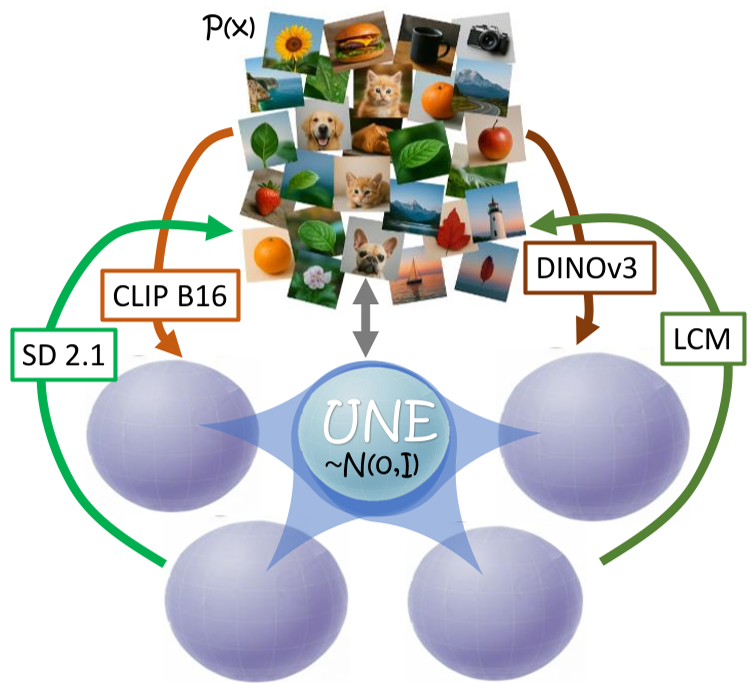 图 1. UNE 概念图:不同的编码器和生成模型只是同一个高斯结构的观测视角。
图 1. UNE 概念图:不同的编码器和生成模型只是同一个高斯结构的观测视角。
3. 实验发现:噪声空间里藏着“语义指南针”
通过构建 NoiseZoo 数据集(包含 CelebA 图像对应的各种模型 Latents),作者得出了惊人的结论:
3.1 线性可分性(Linear Separability)
作者发现,在 DDIM 逆转得到的噪声向量中,通过简单的二分类逻辑回归,就能精准识别出图像属性(如:是否有胡须、是否微笑)。令人意外的是,噪声空间的分类准确率与经过昂贵语义训练的 CLIP 编码器竟然高度正相关。
3.2 跨模型对齐
既然大家都是 UNE 的投影,那么不同模型之间应该可以通过线性变换相互转化。实验证明,从 SD 1.5 的噪声空间线性映射到 CLIP 空间,其特征向量的余弦相似度极高,准确率几乎无损。
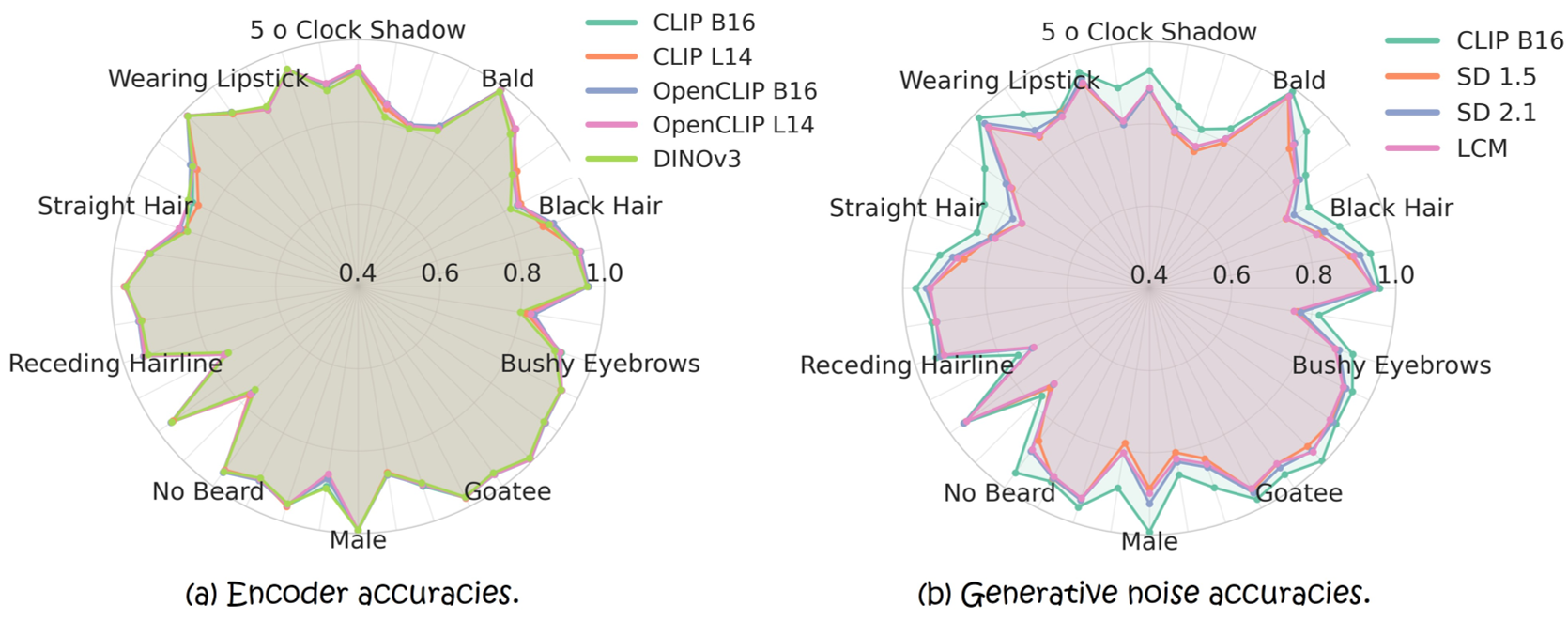 图 3. 线性探针结果:生成模型的噪声空间(b)在属性预测上展现出与语义编码器(a)惊人的一致性。
图 3. 线性探针结果:生成模型的噪声空间(b)在属性预测上展现出与语义编码器(a)惊人的一致性。
4. 落地应用:丝滑的线性编辑
既然语义在噪声空间是线性的,那么编辑图像就变得极其简单:只需沿着分类器的法向量($w$)移动一段距离即可: $$ ilde{z} = z + \alpha w$$
解耦技巧:为了防止“增加山羊胡”的同时意外改变脸型,作者引入了正交化投影。通过将“目标属性”的方向投影到“干扰属性”的零空间,实现了极其纯净的局部编辑,且完全不需要 Prompt 或模型微调。
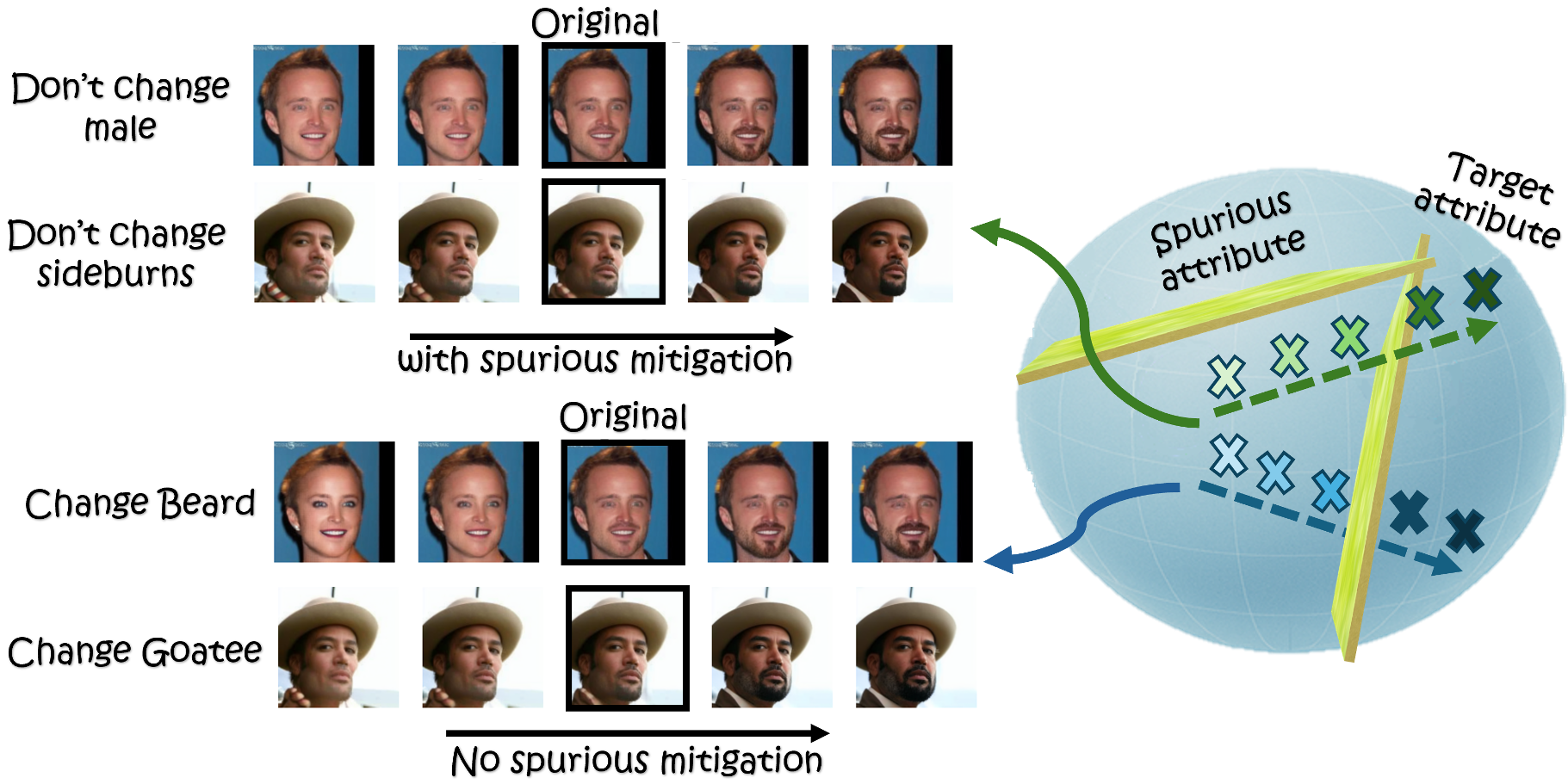 图 5. 通过正交化处理消除属性耦合,实现精准控制。
图 5. 通过正交化处理消除属性耦合,实现精准控制。
5. 资深主编点评 (Critical Analysis)
这篇论文的意义在于它极大地提升了我们对 Diffusion Noise 物理意义的认知。过去我们认为噪声只是生成过程的“种子”,而本文告诉我们:噪声即表征(Noise is Representation)。
- 优势:它提供了一种极其廉价的编辑手段,避开了复杂的反转优化(Optimization)或 LoRA 训练。
- 局限性:虽然线性假设在 CelebA 这种分布较窄的数据集上表现完美,但在长尾分布、复杂场景(如包含多个主体、复杂交互)下的普适性仍需验证。此外,UNE 空间的真实维度 $D$ 仍是一个未解之谜。
一句话总结:这是一篇典型的“以简御繁”的杰作,它用最基本的高斯几何逻辑补齐了生成与理解之间的那块拼图。