本文提出了 TRACE (Textual Representation of Allocentric Context from Egocentric Video),一种通过提示词(Prompting)引导多模态大模型(MLLM)生成场景 3D 结构文本描述,以此作为中间推理链(Reasoning Trace)来提升视频空间理解能力的方法。TRACE 在 VSI-Bench 和 OST-Bench 等 3D 空间推理基准测试中,跨多种模型(如 Gemini, Qwen-VL, MiMo-VL)实现了显著的性能提升。
TL;DR
清华大学与上海人工智能实验室的研究团队发现,MLLM 模型之所以在 3D 空间推理上“抓瞎”,是因为它们在像素和逻辑之间缺少一个结构化的空间屏障。为此,他们提出了 TRACE——一种通过 Prompt 引导模型先写出 3D 环境的“文本简历”(包括地图坐标、运动轨迹、实体登记),再据此回答问题的推理策略。在 VSI-Bench 等基准上,TRACE 显著超越了 CoT 和 ToT 等传统推理技巧。
痛点深挖:为什么 MLLM 是“空间路痴”?
现有的 MLLM(如 GPT-4V, Gemini 3)虽然预训练数据海量,但在面对诸如“洗碗机离哪台冰箱最近?”或“你在视频中行走的路径是什么形状?”等问题时经常出错。
- 2D 捷径偏见:模型倾向于寻找图像中的 2D 纹理关联,而非理解 3D 物理架构。
- 缺乏内部地图:人类在观看视频时会自动在脑中构建“全局坐标框架(Allocentric)”,而模型更像是在被动观察每一帧的“第一视角像素(Egocentric)”。
- 计算效率缺失:标准的文本 Chain-of-Thought (CoT) 擅长逻辑推演,却难以描述复杂的点云、距离或多步位移。
核心方案:TRACE(从第一视角到全局上下文)
作者的核心 Insight 来源于认知科学:人类描述环境是通过物体及其空间关系的层级化抽象。TRACE 强制模型在生成最终答案前,先完成一份符合 YAML 格式的“环境勘察报告”。
1. 结构化模块解析
TRACE 由三个核心元数据组成:
- Meta Context:定义房间的全局坐标轴(例如:以入口为原点,长边为 Y 轴)。
- Camera Trajectory:将第一视角摄像头的移动轨迹离散化为一系列坐标点
[x, y]和朝向。 - Entity Registry:物体的“户口本”,记录了物体的首次出现时间、外观特征、以及估计的物理坐标。
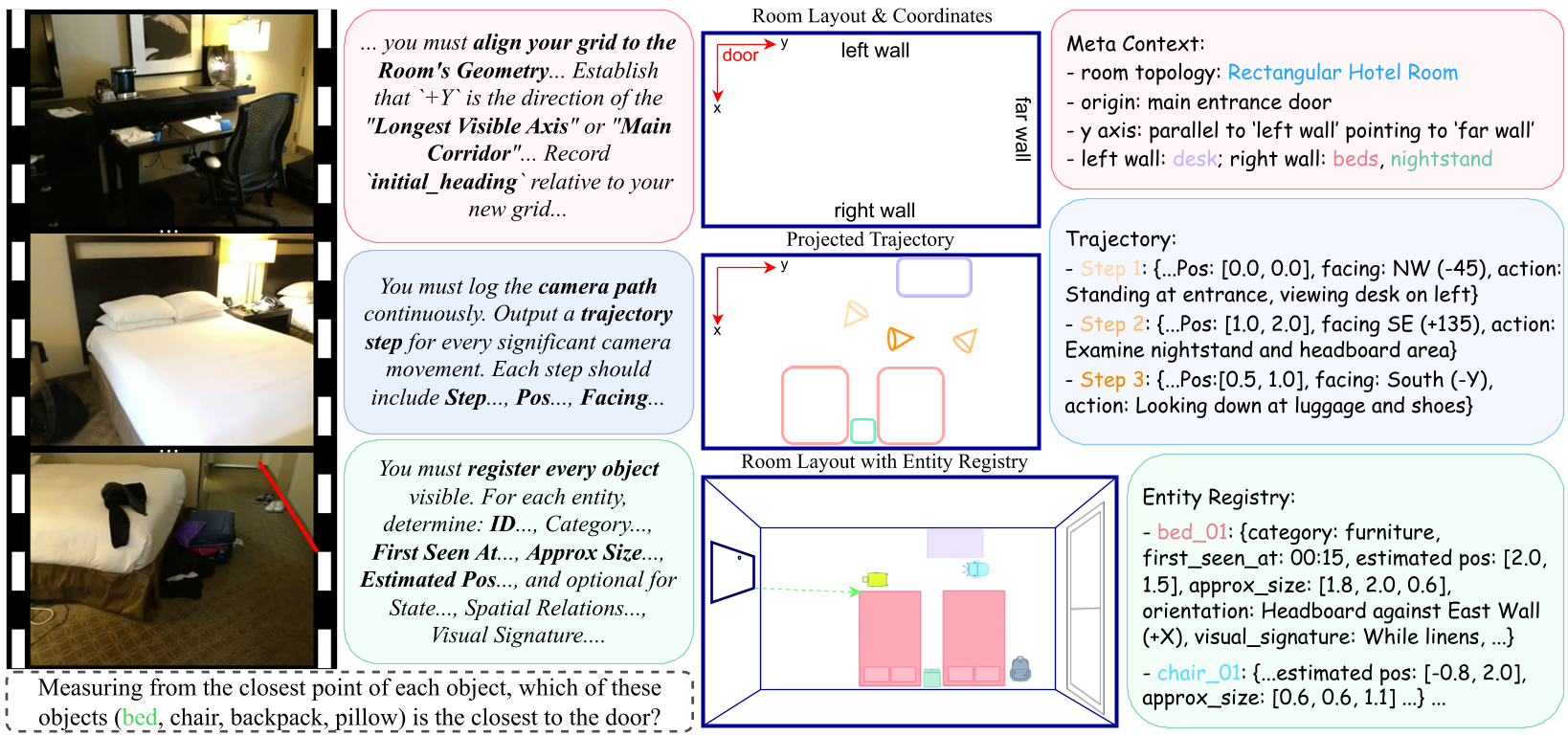
2. 推理直觉
通过这种显式的文本“空间缓存”,模型在回答问题时实际上在执行“文本检索 + 几何计算”而非“端到端黑盒生成”。
实验惊艳:文本比视频更懂空间?
研究人员在 VSI-Bench(视频空间智能基准)上对比了多种 prompting 策略。
| 策略 | 平均准确率提升 (Gemini 3 Pro) | Qwen2.5-72B 增幅 | | :--- | :--- | :--- | | Direct (直接回答) | 52.61 | 36.28 | | CoT (链式思考) | +1.04% | -6.50% (性能反降) | | TRACE (本文) | +7.54% | +3.10% |
深度发现: 有一个有趣的实验(Table 3)显示,如果让一个 LLM 完全不看视频,仅根据另一模型生成的 TRACE 报告来回答问题(Text-Only Inference),其表现竟然与直接看视频的模型相当。这说明 TRACE 成功提取了视频中 3D 理解所需的“信息干货”。
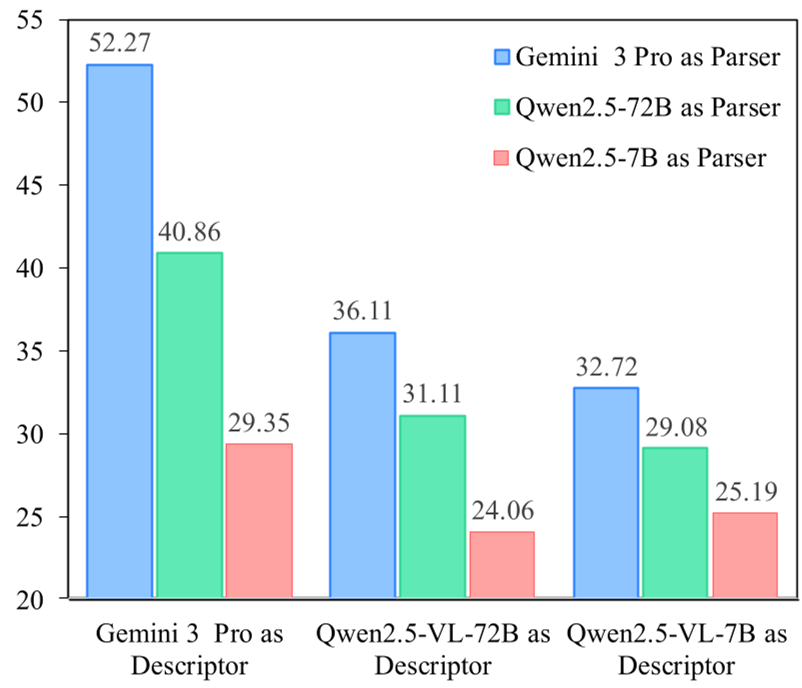
深度洞察:瓶颈在哪里?
作者通过“感知与推理的分解实验”发现了一个有趣的现象:
- 感知瓶颈:更换不同的 Descriptor(负责生成 TRACE 的模型)对结果影响极大。7B 和 72B 级别的模型在 3D 感知(即估算物理坐标)上依然面临挑战。
- 推理冗余:对于复杂任务,仅仅有地图是不够的, Reasoning Parser(负责理解地图的模型)的逻辑能力决定了上限。
总结与局限性
TRACE 的成功意味着我们可能不需要立即追求极其昂贵的 3D 多模态架构大改,通过认知启发式的提示工程(Cognitive-inspired Prompting),现有的视觉模型依然有巨大的潜力未被挖掘。
- 局限性:当前的 TRACE 是静态的(Static Allocentric Representation),在处理超长视频或极速运动场景时,需要进一步解决动态流式更新的问题。
- 未来前景:这种结构化文本表示将来可以作为“数据引擎”,为 Embodied AI 任务自动标注高质量的 3D 推理数据。
本文主编注:TRACE 的核心价值在于将 LLM 强大的自然语言遵循能力引入到了极其“硬核”的几何推理任务中,这种“以柔克刚”的方法论值得工业界关注。