V-Dreamer is a fully automated framework designed to synthesize large-scale, open-vocabulary robotic manipulation data (scenes and trajectories) from natural language instructions. It combines LLMs, 2D/3D diffusion, and video generation models to create simulation-ready environments and executable expert trajectories, achieving SOTA results in zero-shot sim-to-real transfer.
TL;DR
V-Dreamer is a breakthrough "full-cycle" data engine that automates the generation of robot training data. By asking an AI to "dream" a video of a task and then mathematically mapping that dream into 3D robot instructions, it eliminates the need for manual teleoperation and fixed asset libraries. It achieves successful zero-shot sim-to-real transfer using only a single synthetic demonstration.
Background: The Data Hunger of Generalist Robots
The "ImageNet moment" for robotics has been delayed not by architecture, but by data. Real-world collection is slow, and current simulators are "semantic deserts"—limited to whatever 3D models a human designer manually imported. V-Dreamer changes the paradigm by utilizing Video Generation Priors to solve both the environment diversity and the behavior synthesis problems simultaneously.
The Core Challenge: Why can't we just use AI videos?
Generative models like Sora or Wan2.2 are great at visual storytelling, but they are "physically untethered." In an AI-generated video, a cup might morph into a hand, or a robot arm might pass through a table. V-Dreamer provides the "Physical Grounding" necessary to turn these pixels into precise 6-DoF end-effector trajectories.
Methodology: The V-Dreamer Pipeline
The framework operates in three distinct stages to bridge the gap between a "prompt" and a "motor command."
1. Semantic-to-Physics Scene Synthesis
Instead of picking from a list, V-Dreamer uses LLMs (Qwen-Max) to plan a scene and Flux (Diffusion) to generate unique textures/objects. These are lifted into 3D via a memory-efficient reconstruction module and placed into the Genesis physics engine.
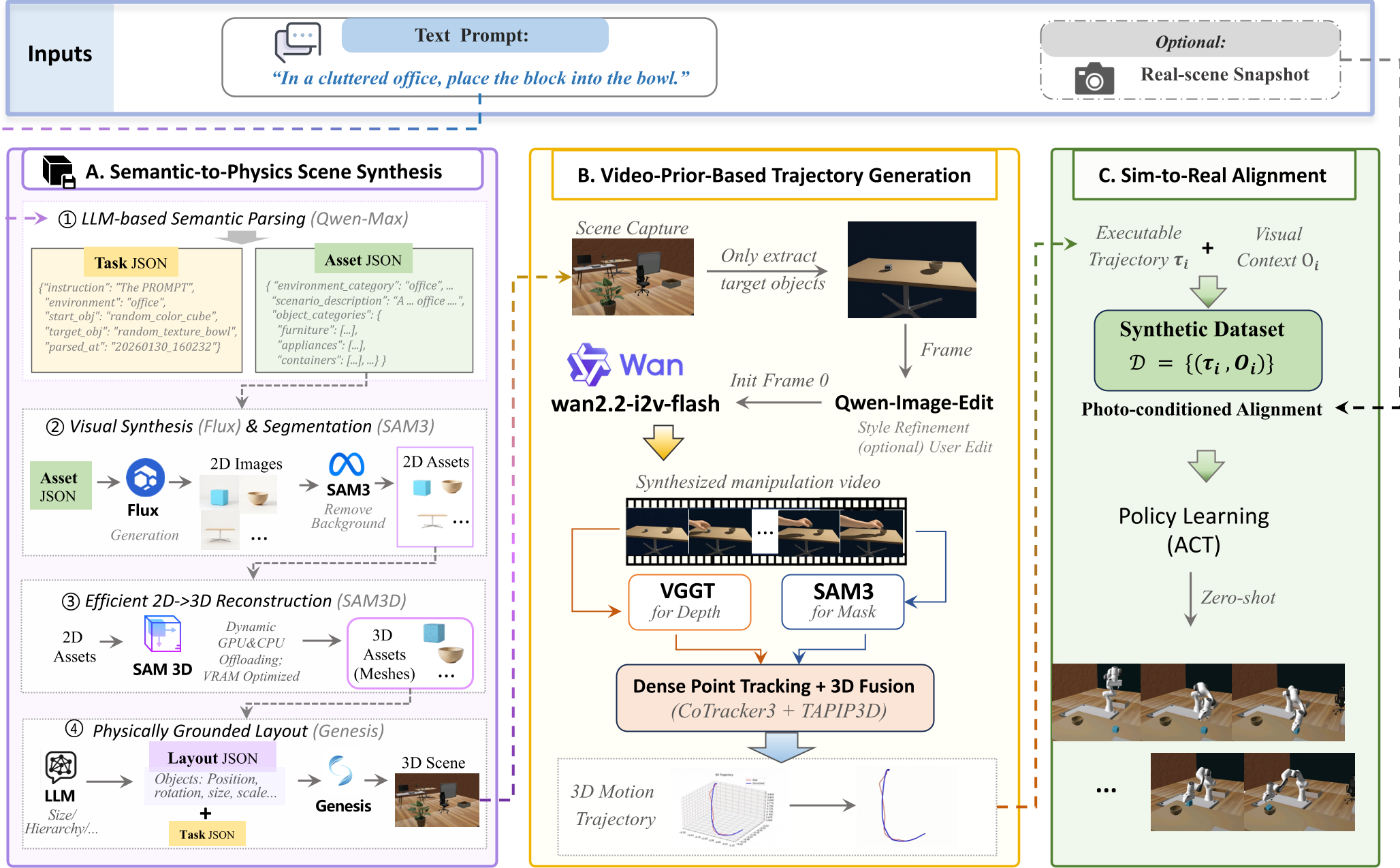
2. Video-Prior-Based Trajectory Generation
Using the generated scene's first frame (), the system prompts a video model (Wan2.2) to "imagine" the manipulation. Crucially, they use Targeted Negative Prompting (e.g., "no camera motion," "no deformation") to force the AI to respect rigid-body physics.
3. Sim-to-Gen Alignment
This is the "special sauce." V-Dreamer uses:
- CoTracker3: To track dense points on the object in the 2D video.
- VGGT: To estimate metric depth.
- TAPIP3D: To lift these tracks into a coherent 3D path. The result? A pixel-perfect motion is converted into a series of coordinates for the robot.
Experimental Performance
The researchers tested the system as a high-throughput data engine on a Piper robotic arm.
Scalability and Diversity
V-Dreamer can generate 600 trajectories per hour on an 8-GPU setup. When the training set size was increased from 500 to 2,500 trajectories, the policy success rate on unseen mug geometries jumped from near-zero to ~37%. This proves the generated data has high "semantic coverage."
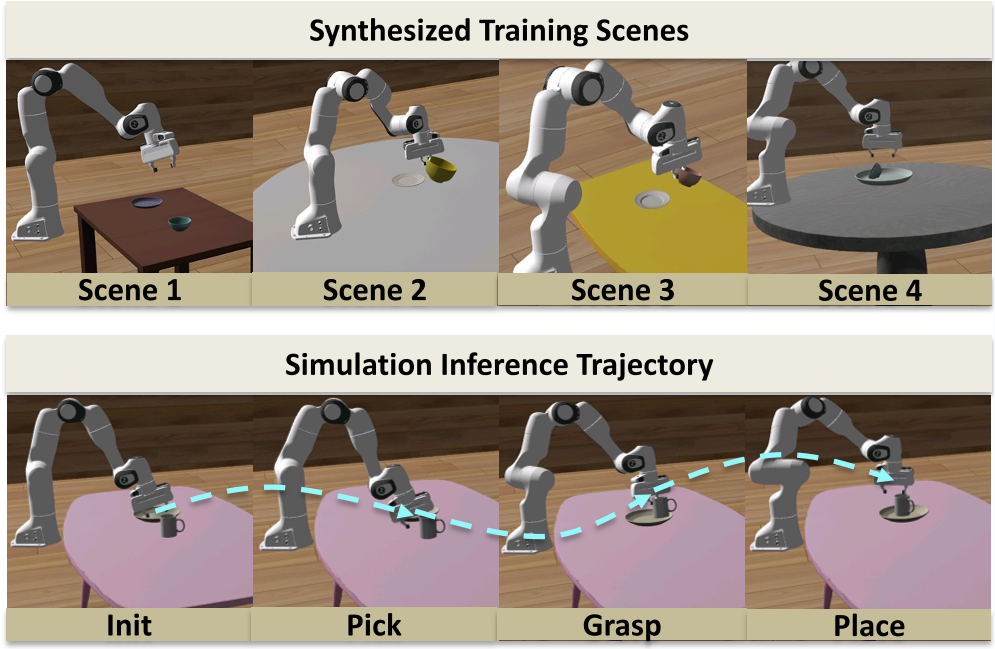
Real-World Robustness
In a "One-Shot Sim-to-Real" test, a policy trained on one single generated trajectory was able to:
- Handle visual distractors (50% SR).
- Manipulate out-of-distribution objects like apples and tape rolls.
- Adjust to spatial perturbations of the goal.
Critical Insights & Future Outlook
The brilliance of V-Dreamer lies in its "Sim-to-Gen-to-Real" workflow. Instead of trying to make simulation look like reality (Sim-to-Real) or making reality look like simulation (Real-to-Sim), it uses a generative "Dream" as the intermediary that understands both.
Limitations: Currently, the system is optimized for rigid-body tabletop tasks. Extending this to "soft" objects (like laundry) or complex "articulated" objects (like scissors) remains the next frontier.
Takeaway: We are entering an era where robot "experience" can be manufactured purely through generative imagination, provided we have the mathematical tools to ground those dreams in 3D geometry.