V-JEPA 2.1 is a self-supervised learning framework that achieves state-of-the-art dense and global representations for images and videos using a Joint-Embedding Predictive Architecture. It introduces a Dense Predictive Loss and Deep Self-Supervision, scaling up to a 2B parameter ViT-G model that sets new benchmarks in short-term object interaction anticipation (7.71 mAP on Ego4D) and monocular depth estimation (0.307 RMSE on NYUv2).
TL;DR
V-JEPA 2.1 transforms Video Joint-Embedding Predictive Architectures into a powerhouse for both high-level action recognition and low-level dense tasks (like depth estimation and robotic grasping). By supervising all tokens—even the visible ones—and applying the loss across multiple encoder layers, Meta's FAIR team has created a model that doesn't just "guess" what's missing, but deeply understands the spatial and temporal geometry of the world.
The Motivation: Why JEPA Features Were "Noisy"
While the V-JEPA family has always been great at "seeing the big picture" (global dynamics), their local feature maps were notoriously messy. If you visualized the patch features using PCA, they looked like fragmented noise compared to image-only models like DINOv2.
The authors identified the culprit: The Masking Paradox. In standard JEPA, the loss is only calculated on masked tokens. The "context" (visible) tokens were left unsupervised, allowing them to act as "registers" that ignored local spatial structure to focus purely on helping the predictor solve the masked patches. V-JEPA 2.1 fixes this by saying: Every token must be grounded in its own representation.
Methodology: The Core Ingredients
V-JEPA 2.1 introduces four critical architectural and algorithmic shifts:
- Dense Predictive Loss: Instead of just predicting the "holes," the model predicts a representation for every patch. To prevent the model from simply "copying" input data, they use a distance-weighted L1 loss that emphasizes context tokens near the masked boundaries.
- Deep Self-Supervision: The loss isn't just at the end of the 48-layer ViT-G. It is applied to four intermediate levels. This forces local structural information to flow through the entire network, rather than getting lost in the deeper layers.
- Multi-Modal Tokenizer: Images are finally treated as images (2D convolutions) and videos as videos (3D convolutions), allowing a single shared encoder to scale effectively across 163M mixed samples.
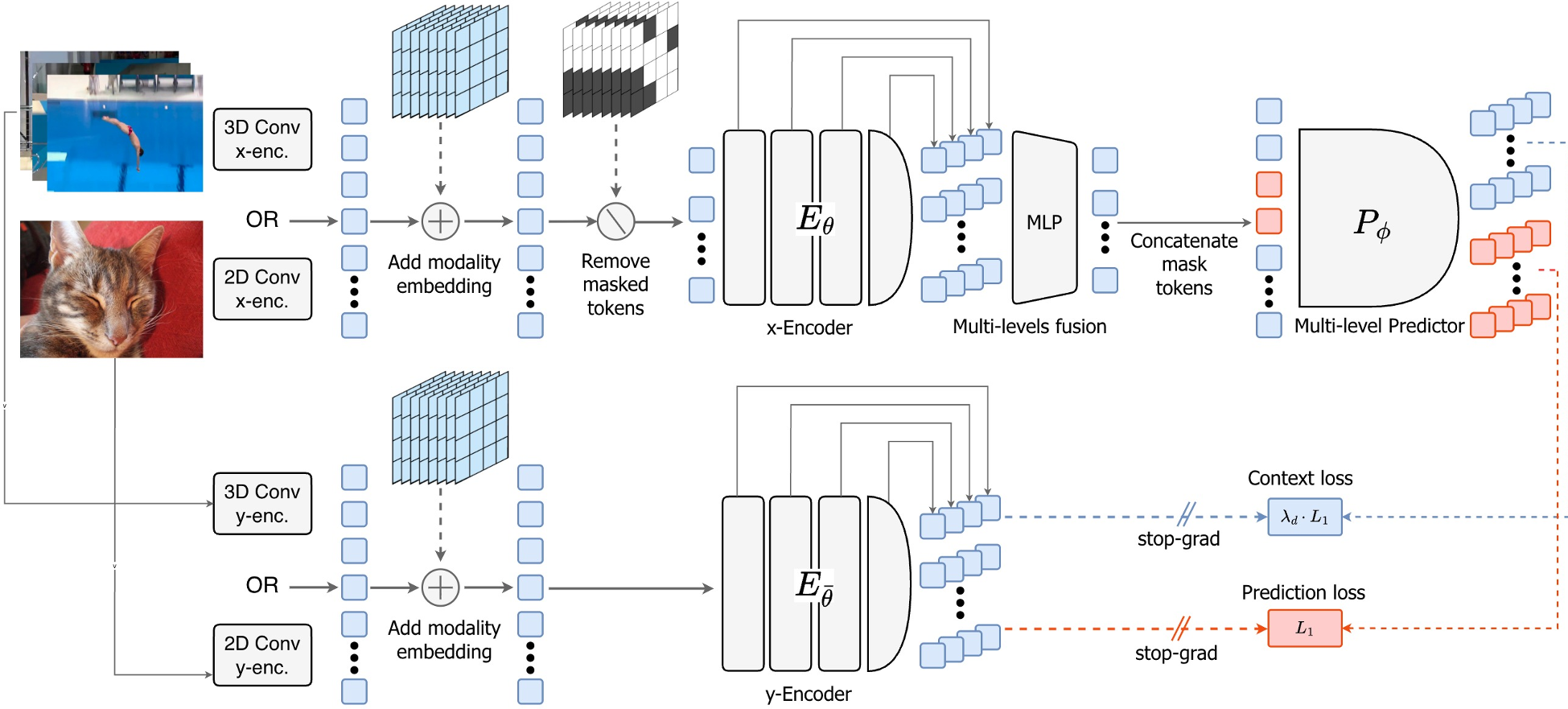 Figure 1: The V-JEPA 2.1 architecture featuring multi-level prediction and dense loss application.
Figure 1: The V-JEPA 2.1 architecture featuring multi-level prediction and dense loss application.
Experiments: SOTA Across the Board
The results are staggering because they impact two very different worlds: Semantic Recognition and Geometric Understanding.
- Robotics: V-JEPA 2.1 increased zero-shot real-robot grasping success by 20% compared to its predecessor.
- Geometry: On the NYUv2 depth estimation benchmark, the model achieved a 0.307 RMSE, outperforming specialized image encoders and slashing the error rate of V-JEPA 2 in half.
- Predictive Power: It dominates the Ego4D Short-Term Anticipation (STA) task, which requires predicting where and when an interaction will happen in the future.
 Figure 2: PCA visualizations show that V-JEPA 2.1 (right) learns semantically coherent features where similar objects (like car wheels or dog heads) map to the same colors, unlike the fragmented V-JEPA 2 (left).
Figure 2: PCA visualizations show that V-JEPA 2.1 (right) learns semantically coherent features where similar objects (like car wheels or dog heads) map to the same colors, unlike the fragmented V-JEPA 2 (left).
Deep Insight: A New Foundation for World Models
The shift from V-JEPA 2 to 2.1 represents a philosophical change in SSL. We are moving away from the idea that "masking is enough." To truly model the physical world for an agent—whether it's a robot arm or an autonomous car—the model needs a dense state estimator.
By supervising context tokens, the model learns an Inductive Bias for continuity. The PCA visualizations in the paper (see Figure 15 in the original text) show that the model tracksCamouflaged animals and moving objects with a temporal consistency that was previously only seen in models specifically designed for tracking.
Conclusion & Future Outlook
V-JEPA 2.1 serves as a definitive argument for scaling JEPA-based world models. It proves that we don't need generative pixel-prediction (which is computationally expensive) to get high-quality dense features.
Wait, what’s next? The authors hint at scaling even further—to 7B parameters—and further integrating these dense "world-state" representations into planning and reinforcement learning loops. For the robotics community, V-JEPA 2.1 might just be the robust visual backbone they've been waiting for.