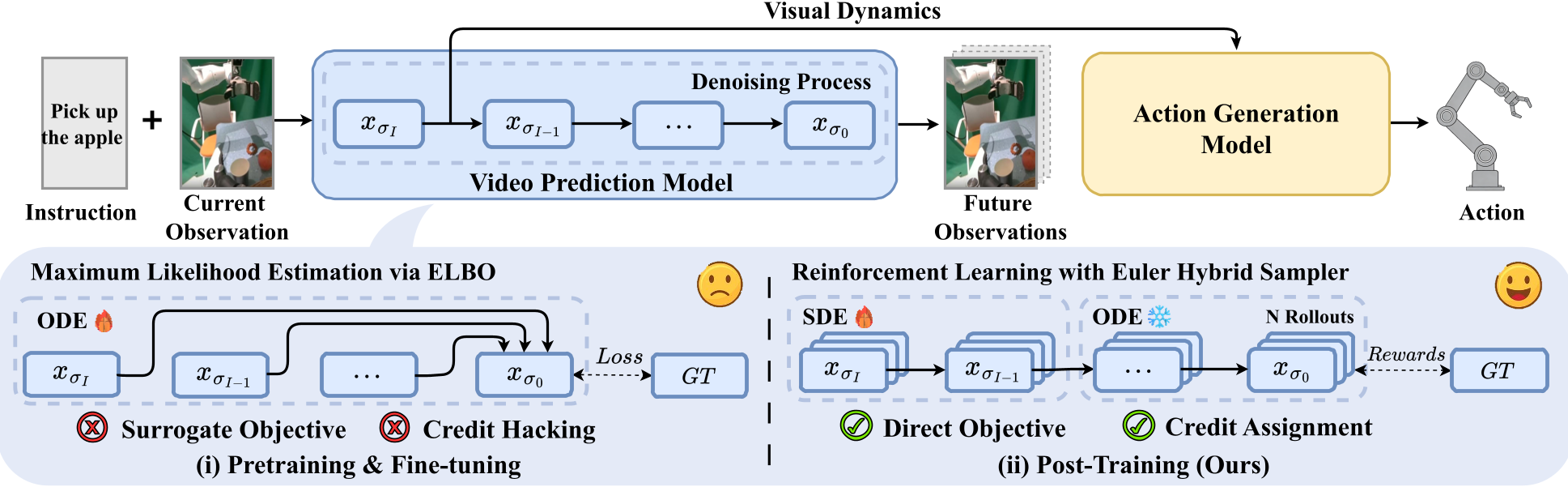
VAMPO (Visual Action Model Policy Optimization) is a post-training framework designed to refine the visual dynamics in diffusion-based video action models. It casts multi-step denoising as a sequential decision process and uses Group Relative Policy Optimization (GRPO) to align predicted latent representations with expert visual dynamics, achieving new SOTA performance on benchmarks like CALVIN.
Executive Summary
Current Vision-Language-Action (VLA) systems often rely on Video Prediction Models (VPM) to act as an internal "mental simulator." However, these models are typically trained using standard likelihood-based diffusion objectives (ELBO), which focus on making images look "realistic" rather than "functionally accurate."
VAMPO (Policy Optimization for Improving Visual Dynamics) addresses this by treating the denoising process of a video model as a controllable policy. By applying RL-based post-training (specifically GRPO), it aligns the model’s latent predictions with expert trajectories. The result? A significant boost in manipulation precision and generalization without changing the underlying architecture.
The "Objective Mismatch" Problem
Why do state-of-the-art video models fail at robot control?
- Prior Work (Likelihood focus): Diffusion models minimize the difference between predicted and added noise. This creates visually pleasing videos but misses the "physics" of the scene. A 2mm gap in a gripper's position might have a negligible impact on the loss function, but it's the difference between success and failure in a grasping task.
- Compounding Errors: Small errors in object pose or contact timing in the VPM are passed to the Action Generation Model (AGM), leading to a "cascade of failure" during real-time execution.
Methodology: Denoising as Sequential Decision Making
VAMPO reformulates the VPM as a Reinforcement Learning agent. In this MDP:
- State: The current noisy latent, timestep, and language instruction.
- Action: The denoising update (the step towards a cleaner latent).
- Reward: A combination of L1 distance and Cosine Similarity between the final denoised latent and the encoded ground truth expert video.
The Euler Hybrid Sampler
A hallmark of VAMPO is its Euler Hybrid Sampler. Standard RL on diffusion (like DDPO) can suffer from high variance and "reward hacking" if noise is injected at every step. VAMPO injects SDE-style stochasticity only at the first step. This provides the "exploration" needed for policy gradients while the subsequent deterministic (ODE) steps ensure the temporal structure remains stable.
Experiments and Insights
SOTA Comparison on CALVIN
VAMPO was tested on the CALVIN benchmark (ABC→D protocol), which tests long-horizon manipulation and generalization to new environments. VAMPO reached an Average Length of 4.56, significantly outperforming the base VPP model and other latent-level VLAs.

Why does it work? Jacobian Rank Analysis
The authors measured the Effective Rank (ER) of the Jacobian (Action w.r.t Visual dynamics). A higher rank indicates that the action generator is extracting more independent, useful information from the visual features.
- Base Policy ER: 29.28
- VAMPO ER: 43.88 This suggests that VAMPO forces the model to encode richer, more decoupled physical interactions in its latent space.
Ablation: What Matters?
- GRPO vs DDPO: GRPO (Group Relative Policy Optimization) proved more stable than DDPO, likely due to its ability to normalize rewards within a group of samples, reducing the impact of noisy trajectories.
- Latent vs Pixel Rewards: Optimizing in the Latent Space produced better results than Pixel Space. The authors argue that pixels contain too much redundant "texture" information, whereas latents focus on the underlying "semantics" and "affordances" of the task.
Critical Analysis & Conclusion
VAMPO represents a shift from Generative Pre-training (which learns what things are) to Policy-based Post-training (which learns how things behave).
Limitations:
- It still relies on the availability of expert videos for the latent reward.
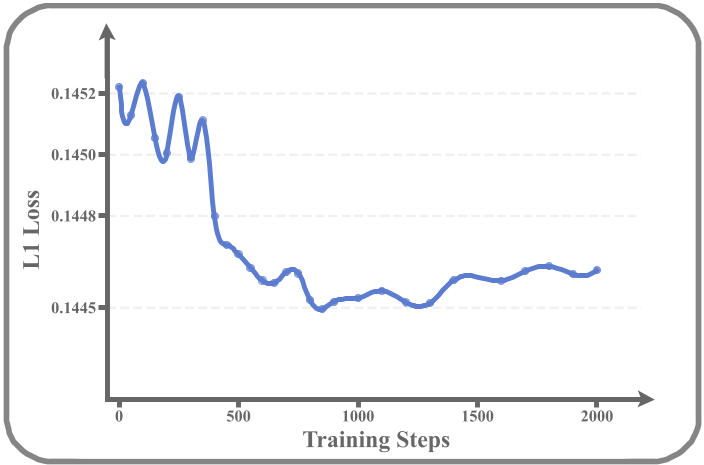
- The training process, while more stable than DDPO, still exhibits some fluctuations in success rates during the 1400-step finetuning.
Future Outlook: The success of VAMPO suggests that the future of robotics lies in "World Model Alignment." Just as we align LLMs with human values via RLHF, we must align Robot World Models with physical constraints via RL-based latent optimization.