[CVPR 2026] VFig: Bridging the Gap Between Raster Images and Editable Scientific Diagrams
The paper introduces VFig, a suite of Vision-Language Models (VLMs) specifically designed to convert rasterized complex scientific diagrams into high-fidelity, editable Scalable Vector Graphics (SVG). It achieves state-of-the-art performance for open-source models, rivaling proprietary systems like GPT-5.2 with a VLM-Judge score of 0.829.
TL;DR
Converting a flat PNG image of a neural network architecture back into editable SVG code has long been a "holy grail" for researchers. VFig achieves this by combining a massive new dataset (VFig-Data), a coarse-to-fine curriculum, and Reinforcement Learning from Visual Feedback (RLVF). It marks a significant milestone where open-source models can finally compete with proprietary giants like GPT-5.2 in structured code generation.
Problem & Motivation: Beyond Simple Tracing
Most existing vectorization tools (like Potrace or VTracer) focus on "tracing"—turning pixels into mathematical curves. While visually accurate, they produce a "path soup" that is impossible for a human to edit. If you want to move a box or change a label, these tools fail.
The challenge is that scientific figures are hierarchical. They consist of recurring primitives (rectangles, circles), precise connectivity (arrows), and semantic labels. Training a model to generate thousands of tokens of SVG code that must be syntactically perfect and visually aligned is a long-horizon reasoning problem that standard Vision-Language Models (VLMs) struggle with out-of-the-box.
Methodology: The VFig Recipe
The researchers addressed these challenges through a three-pronged approach:
1. Data Curation (VFig-Data)
They built a dataset of 66K high-quality pairs. The secret sauce was a "describe-and-generate" pipeline where a high-end VLM first describes the image and then generates the SVG, ensuring the resulting code is clean and uses semantic primitives instead of raw coordinate paths.
2. Coarse-to-Fine Training
Instead of jumping straight into complex figures, the model follows a curriculum:
- Stage 1 (Atomic Primitives): Learning basic shapes and simple layouts.
- Stage 2 (Compositional Reasoning): Moving to multi-panel, real-world scientific figures.
3. RL with a Rubric-Based Judge
Standard SFT minimizes token loss, which doesn't always correlate with visual beauty. VFig uses GRPO (Group Relative Policy Optimization) where a VLM judge (Gemini-3-Flash) provides rewards based on a four-point rubric:
- Presence: Are all elements there?
- Layout: Is the spacing correct?
- Connectivity: Do the arrows point to the right boxes?
- Details: Is the text and styling accurate?
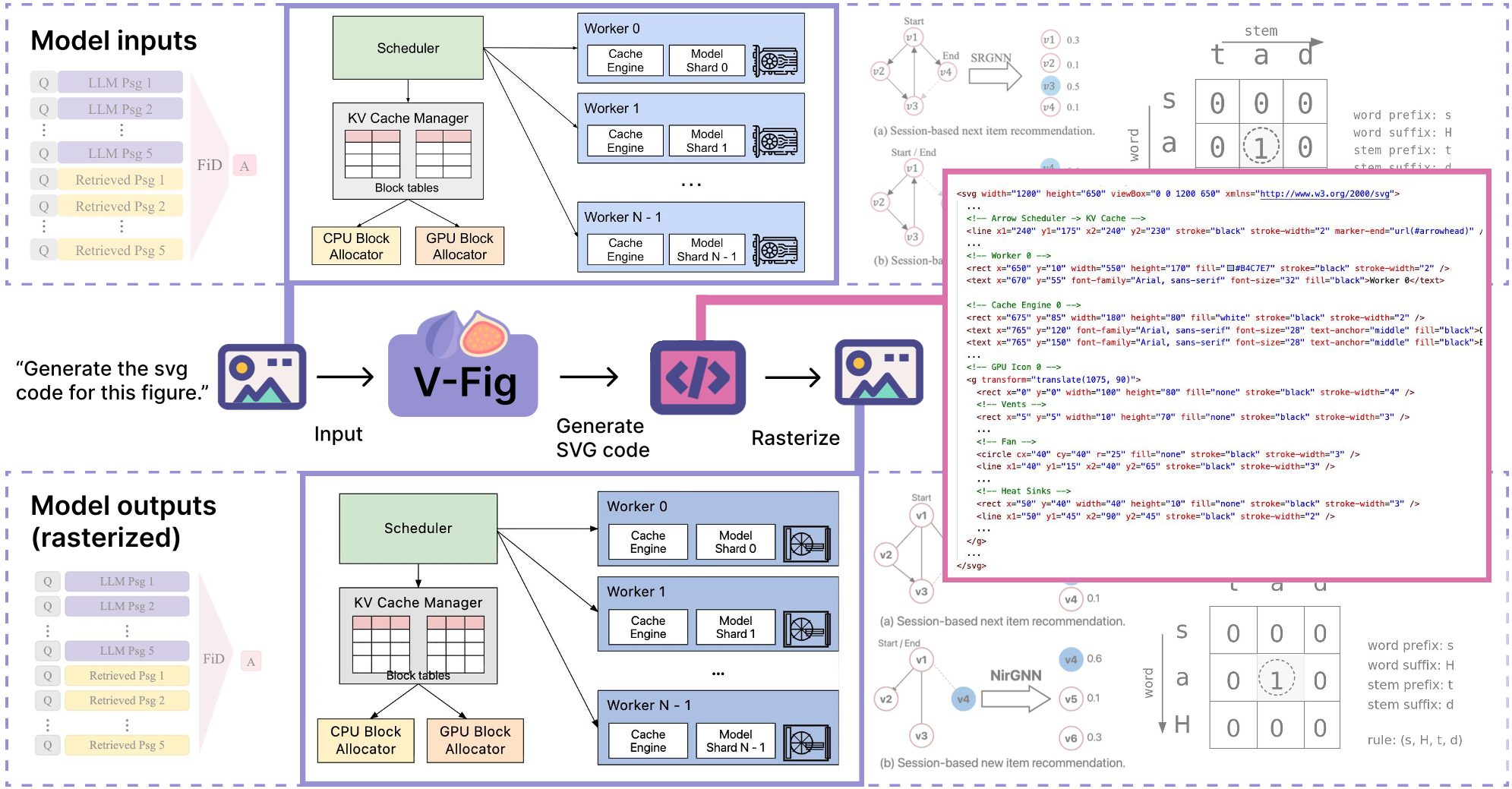 Fig 1: The VFig pipeline transforms complex raster inputs into high-fidelity, editable SVG code.
Fig 1: The VFig pipeline transforms complex raster inputs into high-fidelity, editable SVG code.
Experiments & Results: A New SOTA
The results on VFig-Bench demonstrate a massive gap between VFig and previous open-source models like OmniSVG or StarVector.
- Visual Fidelity: In human evaluations, VFig was preferred in 81.6% of cases compared to the Qwen3-VL-4B base model.
- Structural Correctness: The model achieved a VLM-Judge score of 0.829, nearly matching GPT-5.2 (0.858).
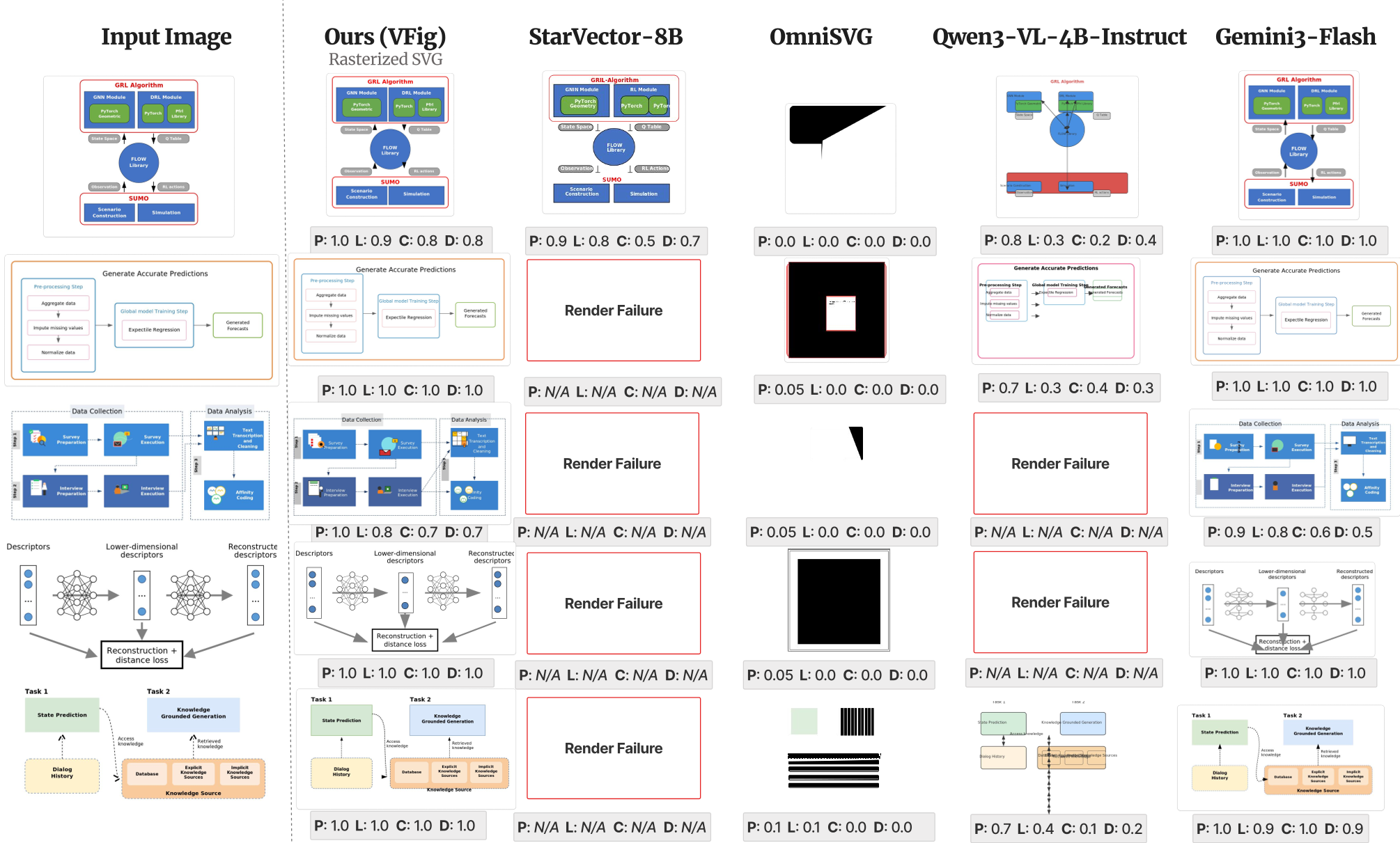 Fig 2: Compared to baselines, VFig (far right) preserves the connectivity and alignment of the input diagram without the "jitter" or missing elements seen in other models.
Fig 2: Compared to baselines, VFig (far right) preserves the connectivity and alignment of the input diagram without the "jitter" or missing elements seen in other models.
The Power of RL
An interesting finding was the "Full+Pixel" ablation. When authors tried to add a pixel-level reward (like SSIM), the VLM-Judge scores actually dropped. This proves that for structured graphics, semantic correctness (e.g., "is the arrow touching the gate?") is more important for optimization than raw pixel-matching.
Critical Analysis & Conclusion
VFig represents a shift from "image-to-image" thinking to "image-to-program" reasoning.
Limitations: Despite its success, the model still faces challenges with 3D-perspective shapes and extremely dense math equations, which are often better handled by LaTeX. The "detail" metric remains the lowest among the rubric scores, indicating room for improvement in fine-grained styling (fonts, subtle gradients).
Future Outlook: The VFig methodology—specifically using a VLM as an RL judge for code generation—is a template that could be applied to UI design, CAD modeling, and even architectural software. By releasing the data and models, the authors have set a new benchmark for the community.