本文提出了 VFig,一套专注于将复杂科学图表(Raster)转换为高质量可编辑 SVG 代码的视觉语言模型(VLM)家族。通过引入大规模数据集 VFig-Data 和结构感知强化学习(RL),VFig 在保持图表逻辑结构和几何精度方面达到了开源模型 SOTA,并能与 GPT-5.2 等商业模型竞争。
TL;DR
在学术交流和工业设计中,科学图表(如神经元架构、流程图)通常以 PNG/JPEG 等“扁平化”像素格式存在,一旦丢失源文件,修改和缩放将变得异常痛苦。VFig 是一项开创性的工作,它通过大规模高质量数据集、两阶段课程学习以及“渲染感知的强化学习”,实现了从位图到高保真、可编辑 SVG 代码的自动化转换。
1. 痛点:为什么传统的矢量化“不好用”?
目前的矢量化工具(如 Potrace, VTracer)大多基于几何轮廓追踪。虽然它们能生成看起来相似的矢量图,但其内部代码通常由数以万计的 <path> 路径构成:
- 不可编辑性:你看到的“矩形”在代码里只是几段路径,无法通过修改属性来改变宽窄。
- 逻辑缺失:连接两个框的“箭头”在传统方法中被视为孤立的像素堆叠,失去了箭头的语义标签。
- Token 爆炸:过长的坐标序列会导致大语言模型(LLM)因上下文长度限制而崩溃。
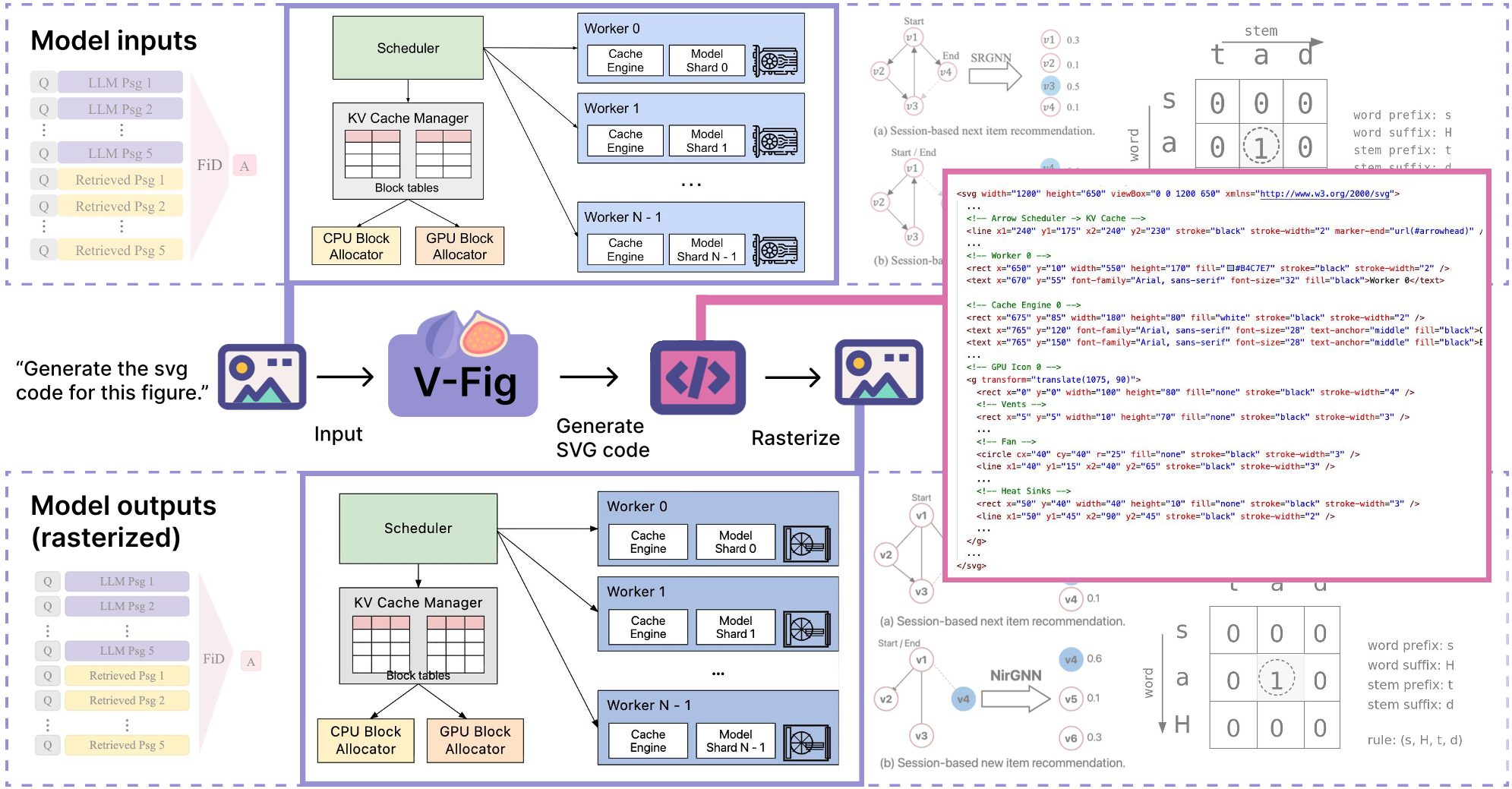 图 1: VFig 流程总览,从位图到可编辑 SVG 的跨越。
图 1: VFig 流程总览,从位图到可编辑 SVG 的跨越。
2. 核心贡献:VFig-Data 与结构感知生成
为了解决数据匮乏问题,作者构建了 VFig-Data(66K 对数据)。其核心思路非常有参考价值:
- 真实数据处理:从小部分现有矢量图转化,并利用 Gemini-3-Pro 建立“描述-生成”流水线,将位图转化为结构化的 SVG。
- 符号合成(VFig-Data-Shapes-and-Arrows):利用程序化语言自动通过 19 种模板生成具有随机抖动、特定连接关系的图表,确保模型能学到精确的连接逻辑(Connectivity)。
3. 训练策略:从原子级到架构级
直接通过位图训练复杂图表极易导致收敛失败。作者设计了 由易到难(Coarse-to-fine) 的训练课程(Curriculum SFT):
- 第一阶段:在简单的形状和箭头数据上预热,建立对
<rect>,<circle>等基本图元(Primitives)的稳定生成能力。 - 第二阶段:进入真实的科学论文架构图领域,训练模型处理多面板布局和层级嵌套。
4. 视觉反馈:强化学习优化(RL with Visual Feedback)
VFig 的最大亮点在于引入了 GRPO(群组相对策略优化) 算法。 模型生成的不再仅仅是文本,而是可以渲染的 SVG 程序。作者利用 VLM(如 Gemini-3-Flash)作为“裁判”,通过渲染后的效果进行打分:
- 存在性(Presence):元素丢没丢?
- 布局(Layout):位置对不对?
- 连接性(Connectivity):箭头连对地方了吗?(最难的一点)
- 细节(Details):颜色、字体是否吻合?
这种方法绕过了传统像素对比(如 L2 损失)无法识别语义语义差异的弊端。例如,一个微小的像素偏移可能在 L2 损失中微不足道,但在逻辑上可能意味着“箭头指向了错误的节点”,而结构化奖励能精准捕捉到这一点。
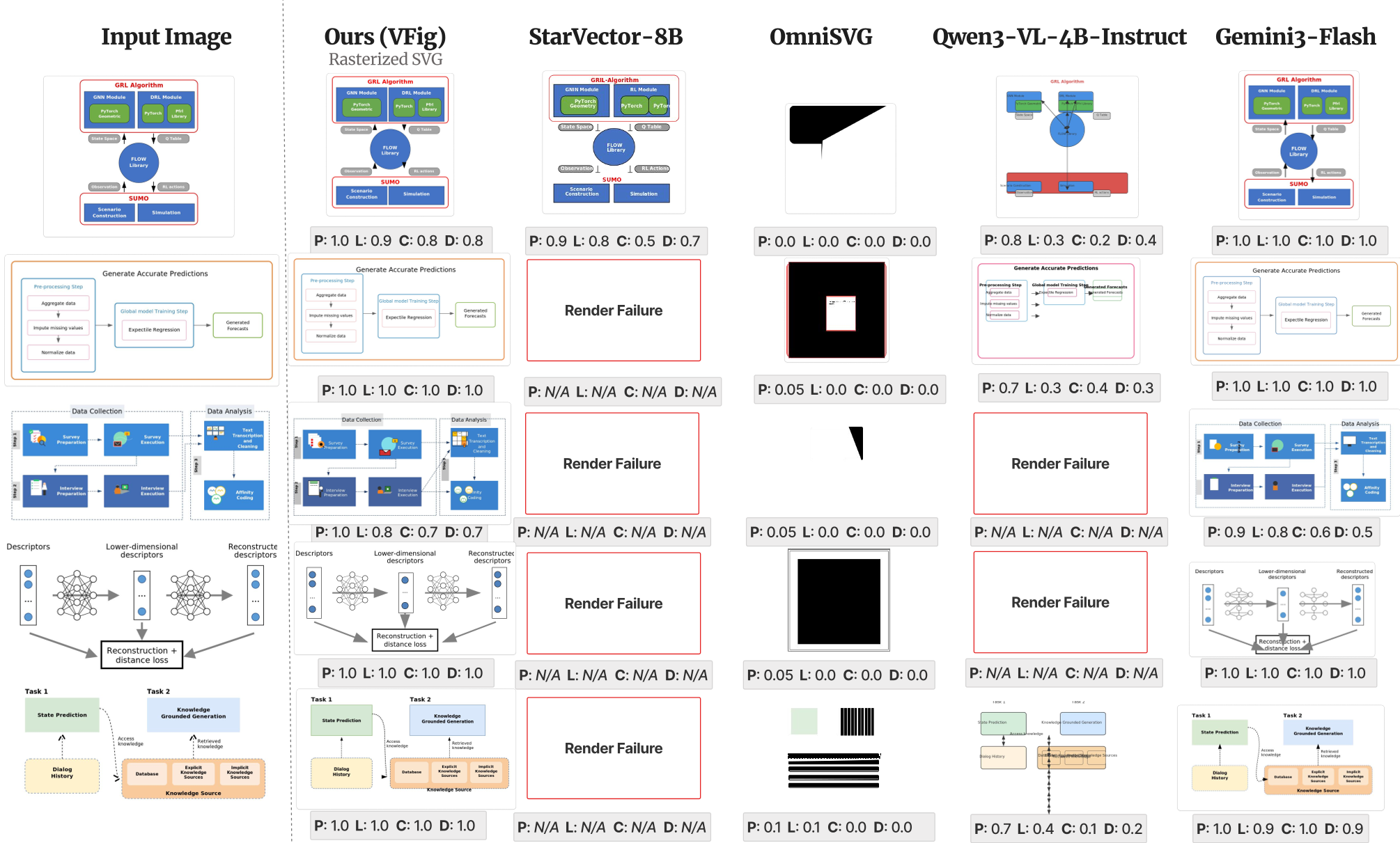 图 2: VFig 与 SOTA 模型对比,VFig 在保存拓扑结构和文本清晰度上具有明显优势。
图 2: VFig 与 SOTA 模型对比,VFig 在保存拓扑结构和文本清晰度上具有明显优势。
5. 实验战绩与 SOTA 评估
VFig 建立了一套多维度的评估基准 VFig-Bench。结果表明:
- 性能飞跃:在结构感知评分上,VFig(SFT+RL)比原始 Qwen3-VL 提升了约 15%。
- 开源之光:VFig 成为了目前最强的开源图表矢量化模型,甚至在多数复合评估指标上优于商业模型 GPT-5.2。
- 消融实验:如果不加入连接性(Connectivity)的奖励,生成的图表逻辑混乱率会大幅提升,证明了结构化奖励的必要性。
6. 局限性与展望
虽然 VFig 在逻辑结构上取得了长足进步,但其在极细微 local 细节(如复杂的数学公式渲染、特定的虚线样式)上仍有提升空间。 未来,将该技术与扩散模型(Diffusion Models)结合,或者扩展到建筑 CAD 图纸、电子电路图的自动矢量化重建,平衡“语义逻辑”与“像素精度”,将是一个极具潜力的方向。
主编点评:VFig 的成功告诉我们,大模型的视觉能力不应只停留在“看”和“说”,通过“生成代码-渲染-反馈”的闭环,模型可以真正理解事物背后的几何与拓扑逻辑。