Vega is a unified vision-language-world-action model designed for instruction-based autonomous driving. By integrating an autoregressive transformer for multimodal understanding and a diffusion transformer for trajectory planning and scene generation, it achieves state-of-the-art results on the NAVSIM v2 benchmark (89.4 EPDMS).
TL;DR
Autonomous driving is evolving from "copying the driver" (Imitation Learning) to "listening to the passenger." Tsinghua University and GigaAI present Vega, a Vision-Language-Action (VLA) model that can perform complex tasks like "overtake the front car to catch the green light" based on natural language. By treating future video prediction as a "world modeling" task, Vega provides the dense supervision needed to map human instructions to precise steering and acceleration.
The "Instruction Following" Problem
Most current End-to-End driving models focus on imitating an "averaged expert." While this works for standard navigation, it lacks personalization and flexibility. If a user says "Pull up to the side and wait," a standard model might ignore the command because it wasn't in the expert's "average" behavior.
The technical bottleneck is the Information Disparity: instructions are high-dimensional and complex, while actions (steering, throttle) are low-dimensional. Training a model with only action labels (sparse supervision) makes it hard for the AI to "understand" why it should change its behavior based on a sentence.
Methodology: World Modeling as Dense Supervision
Vega's core insight is that to act correctly, a model must first imagine the outcome. By training the model to predict the next frame (World Modeling), the authors provide pixel-level feedback. If the instruction is "Turn left," the model must generate an image of a left turn, forcing it to learn the causal link between the text and the physical environment.
The Integrated Transformer Architecture
Vega uses a Joint Autoregressive-Diffusion Architecture.
- Autoregressive Pipeline: Handles the understanding of past images and text instructions.
- Diffusion Pipeline: Generates the noise-to-signal future trajectory and future image frames.
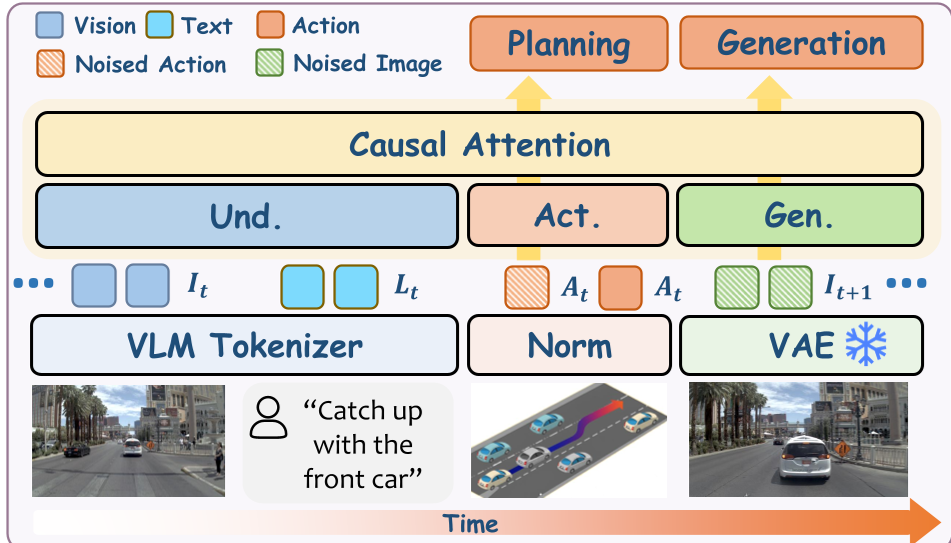
The model utilizes a Mixture-of-Transformers (MoT). Unlike MoE, which only swaps Feed-Forward Networks (FFN), MoT uses dedicated transformer blocks for each modality (Visual, Text, Action). This prevents "parameter interference," where learning to generate images might otherwise degrade the model's ability to plan trajectories.
Experiments & Results: Beyond Imitation
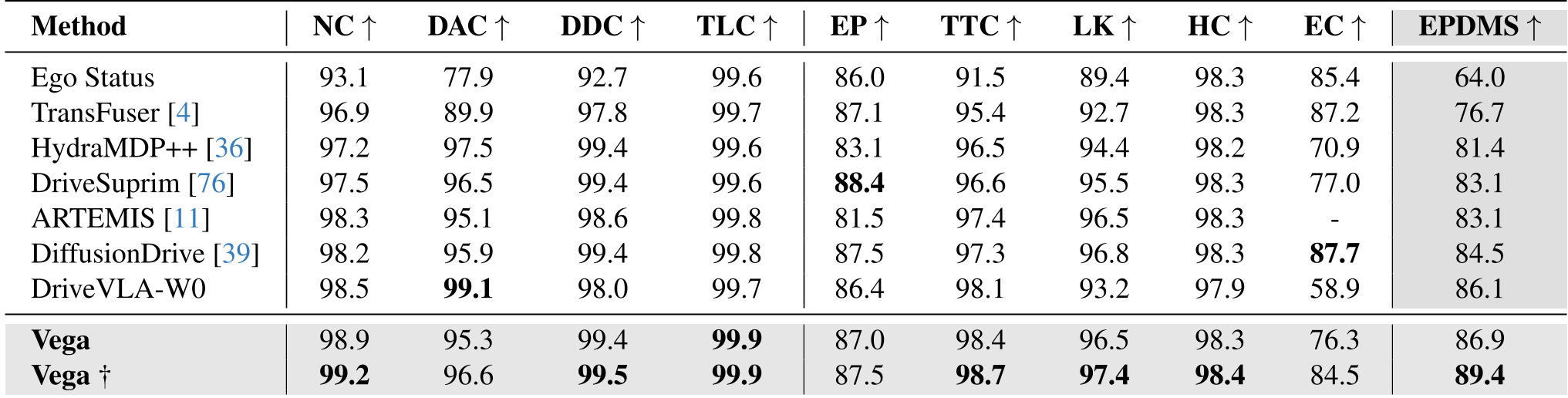
The authors introduced InstructScene, a dataset of 100,000 scenes annotated with diverse instructions using GPT-4o. On the NAVSIM benchmarks, Vega outperformed leading VLA models:
- NAVSIM v2: Achieved 89.4 EPDMS, showing superior adherence to traffic lights and lane keeping.
- Ablation Study: Removing the future image prediction task caused performance to drop significantly (from 77.9 to 51.8 PDMS), proving that "World Modeling" is essential for instruction alignment.
Visual Evidence
As shown in the qualitative results, Vega can plan entirely different trajectories for the same intersection depending on whether the instruction is to "Follow the car" or "Stop at the crosswalk."

Critical Analysis & Conclusion
Vega demonstrates that the future of autonomous driving lies in Unified Multimodal Models. By merging generative world modeling with action planning, we overcome the limitations of sparse data.
Limitations: Currently, the model focuses on front-view cameras. To reach L4 autonomy, expanding this architecture to multi-view 360-degree visions and 3D occupancy prediction will be the next frontier.
Takeaway: If you want your agent to follow instructions, don't just teach it what to do; teach it what the world should look like after it performs the action.