本文提出了 VGGRPO (Visual Geometry GRPO),一种旨在提升视频生成模型几何一致性的后训练框架。该方法通过构建潜在几何模型 (LGM) 将视频扩散模型的 Latent 空间直接连接至几何基础模型,并利用组相对策略优化 (GRPO) 在 Latent 空间内进行高效的强化学习对齐,实现了在不经过 VAE 解码的情况下显著增强视频的 3D 结构稳定性和摄像机运动平滑度。
TL;DR
Google 与哥本哈根大学等机构的研究者近日发布了 VGGRPO (Visual Geometry GRPO)。该工作直击视频生成中的“几何崩坏”痛点,通过在 VAE 的 Latent 空间直接构建几何奖励模型,利用强化学习对齐手段,让视频模型在生成动态场景时能保持极高的 3D 一致性和摄像机平滑度。最惊人的是,它完全摆脱了高昂的 VAE 重复解码成本,效率与效果双杀前作。
动机:为什么视频生成的“世界感”这么难?
目前的 SOTA 视频模型(如 Sora, Wan2.1)虽然视觉画质惊人,但往往经不起“几何推敲”:
- 几何漂移 (Geometric Drift):背景物体在镜头移动时忽大忽小。
- 摄像机抖动:生成的轨迹缺乏物理真实感,伴随跳变。
- 维度受限:先前改进几何的方法(如 Epipolar-DPO)大多基于静态场景假设,遇到复杂动态物体直接“破功”。
以往的对齐方法(Alignment)通常需要把 Latent 还原回像素,再丢进几何模型算得分。这种做法不仅慢得离谱,而且像素层的噪声会干扰优化信号,导致训练不稳定。
核心武器:Latent Geometry Model (LGM)
VGGRPO 的第一大创新是 LGM。作者认为,与其在像素空间折腾,不如直接在 Embedding 层提取几何信息。
作者采用了一种“模型缝合 (Model Stitching)”技术:
- 取一个预训练好的几何大模型(如 Any4D)。
- 在其前层插入一个轻量级的 3D 卷积连接器。
- 训练这个连接器,使其能直接从 VAE 的 Latent 特征中预测出相机位姿(Pose)、深度(Depth)和点云(Point Map)。
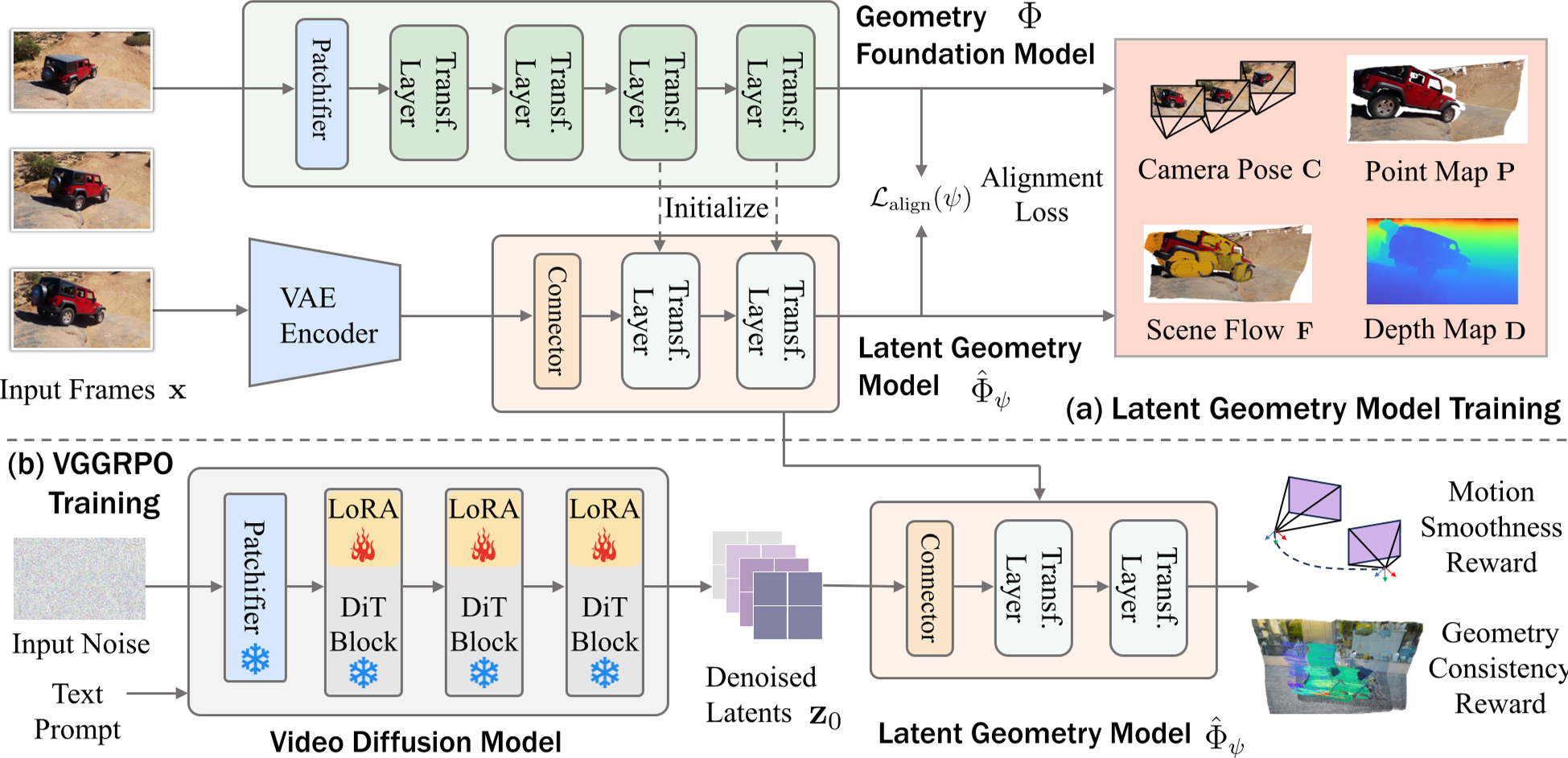
通过这种方式,模型学会了在“看不见”像素的情况下,感知到画面背后的金字塔、街道或滑雪者的 3D 结构。
算法流程:在潜在空间进行 GRPO 对齐
基于构建好的 LGM,作者引入了 GRPO (Group Relative Policy Optimization) 框架。不同于传统的 PPO,GRPO 不需要复杂的 Critic 网络,而是通过一组样本的相对得分来计算 Advantage,非常适合参数量巨大的视频模型。
定义的两个关键奖励函数:
- Camera Motion Smoothness Reward:惩罚加速度的突然跳变,强制模型生成平滑的平移和旋转。
- Geometry Reprojection Consistency Reward:利用 4D 感知的 LGM,将不同帧预测的点云投影回彼此的视角。如果深度对不上,重罚!
 如上图所示,只优化运动奖励(中)会让轨迹平滑但墙壁依然会变形;加上几何对齐(右)后,结构完整性大幅提升。
如上图所示,只优化运动奖励(中)会让轨迹平滑但墙壁依然会变形;加上几何对齐(右)后,结构完整性大幅提升。
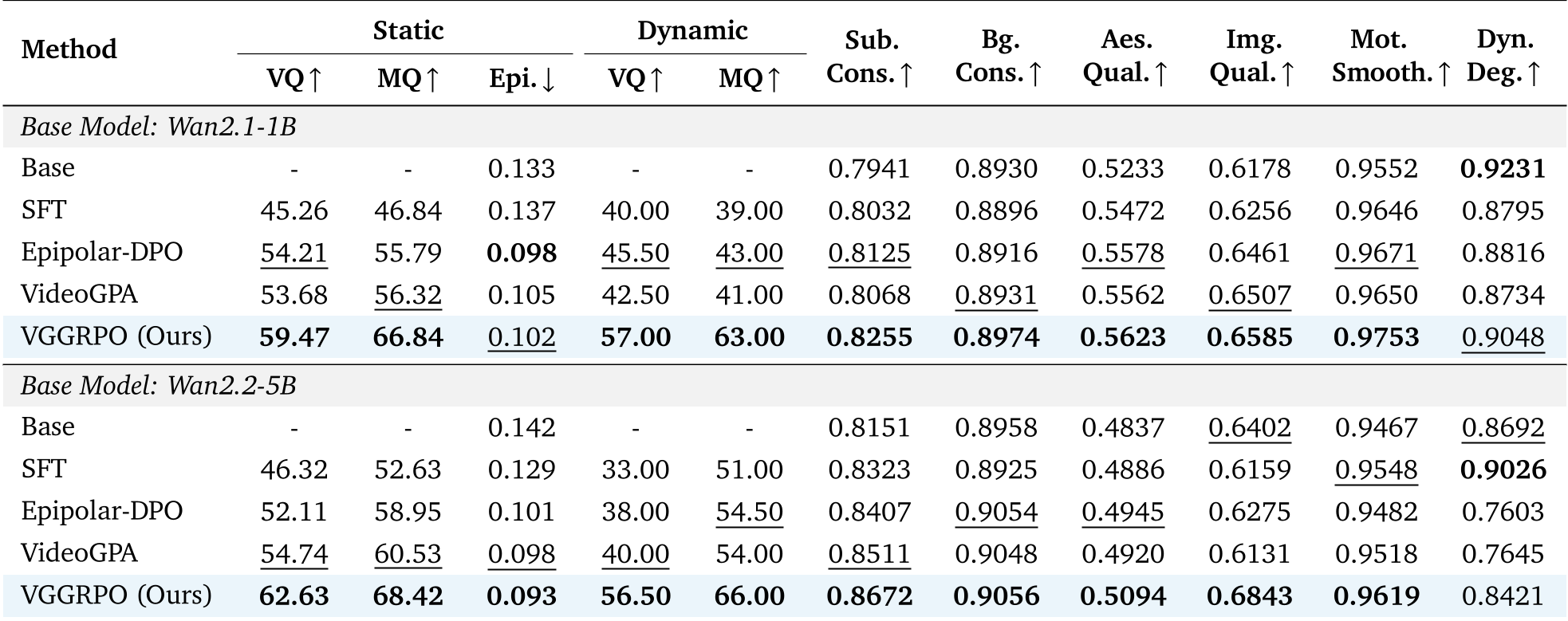
实验战绩:效率与质量的双重胜利
VGGRPO 在 Wan2.2-5B 等模型上展现了极强的适配性:
- 动态场景胜率:在最具挑战性的动态 Benchmark 上,VideoReward 胜率远超之前的 DPO 方法。
- 训练效率:由于省去了 VAE 解码步骤,计算时间缩短了 24.5%,显存压力显著减轻。
- 推理引导 (Test-time Guidance):得益于 LGM 的可微性,该模型甚至支持在推理阶段通过梯度引导来进一步微调几何表现,而无需重新训练。
总结与洞察
VGGRPO 的成功再一次印证了:Latent 空间蕴含着比我们想象中更丰富的结构化特征。通过将“几何感知”作为一种后训练(Post-training)约束,我们不需要重新训练耗资千万的基础模型,就能让其学会物理世界的一致性逻辑。这对于未来将 AI 视频模型应用于机器人仿真、虚拟制片等对几何精度要求极高的领域,具有里程碑式的意义。
Senior Editor's Note: 该方法通过 "Model Stitching" 巧妙避开了跨模态对齐中的计算瓶颈,是强化学习在 AIGC 领域落地的典型范式。唯一的改进空间在于 LGM 本身的精度上限,未来若能集成更强大的 4D 基础模型,视频生成的“世界模拟”能力将更趋完美。