This paper introduces Video-CoE, a novel paradigm for Video Event Prediction (VEP) using a "Chain of Events" (CoE) approach. By reinforcing Multimodal Large Language Models (MLLMs) to construct fine-grained temporal event chains, the method establishes a new SOTA on benchmarks like FutureBench and AVEP, significantly outperforming models like GPT-4o and Qwen2.5-VL.
TL;DR
Predicting what happens next in a video is a hallmark of human intelligence, yet current Multimodal Large Language Models (MLLMs) fail at it because they "cheat" by looking at textual answer options instead of the video frames. Video-CoE introduces the Chain of Events (CoE) paradigm, which forces models like Qwen2.5 to first build a detailed timeline of events (timestamps + descriptions) before making a prediction. Through a sophisticated Reinforcement Learning (RL) pipeline called CoE-GRPO, the model achieves a massive SOTA jump, outperforming even GPT-4o and 72B-parameter giants with only a 7B backbone.
The "Textual Shortcut" Problem
Why do state-of-the-art models like GPT-4o struggle to predict future events? The authors of Video-CoE uncovered a startling trend: MLLMs often exhibit insufficient utilization of visual information.
When asked to predict the next event, these models spend most of their "attention budget" on the textual options provided in the prompt rather than the video tokens. This leads to common-sense hallucinations—where the model picks a plausible-sounding text option that has nothing to do with the specific visual cues in the video.
Methodology: Chain of Events (CoE)
To fix this, the authors argue that a model must understand the History Logic Future pipeline.
1. The CoE Paradigm
Instead of jumping from Video to Prediction , the model follows:
- Temporal Modeling: Segment video into .
- Grounded Reasoning: Reason over both and the newly constructed chain .
- Final Prediction: Output the future event.
2. CoE-GRPO: Learning to See via RL
The most innovative part of this work is the use of Group Relative Policy Optimization (GRPO). Unlike standard SFT, which requires expensive human labeling of "reasoning chains," CoE-GRPO uses a multi-factor reward system:
- Accuracy Reward (): Did it get the answer right?
- CoE Reward (): Did it follow the formatting (event tags) and optimal length?
- Similarity Reward (): This is the "anti-hallucination" shield. The model segments the video based on the timestamps it generated and checks if the text description matches the pixels using a CLIP-like model.
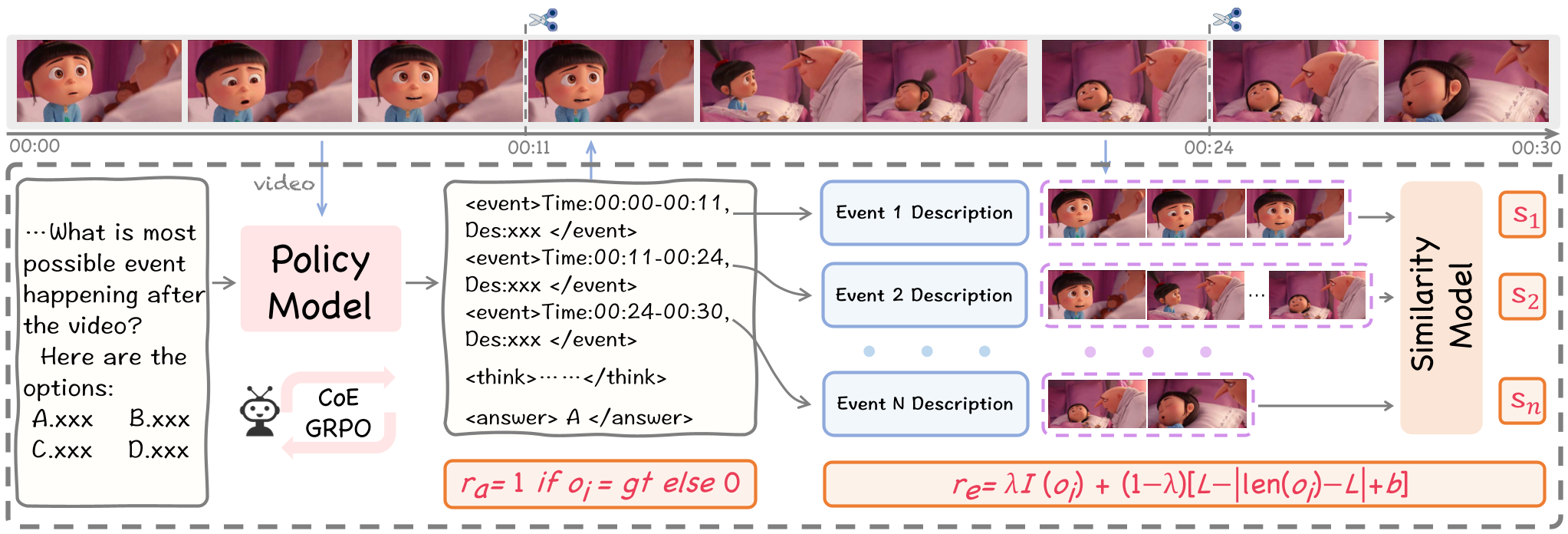 Figure 1: The CoE-GRPO training pipeline, highlighting the alignment between timestamps and video clips via the Similarity Reward ().
Figure 1: The CoE-GRPO training pipeline, highlighting the alignment between timestamps and video clips via the Similarity Reward ().
Experimental Results: Size Doesn't Always Matter
The results on FutureBench show a significant performance delta. The Video-CoE (7B) model achieved an AVG score of 75.00, while the standard Qwen2.5-VL-72B only managed 58.33.
| Model | Method | FutureBench AVG | | :--- | :--- | :--- | | GPT-4o | Vanilla | 59.04 | | Qwen2.5-VL-7B | Instruct | 52.94 | | Qwen2.5-VL-7B (Ours) | CoE-GRPO | 75.00 |
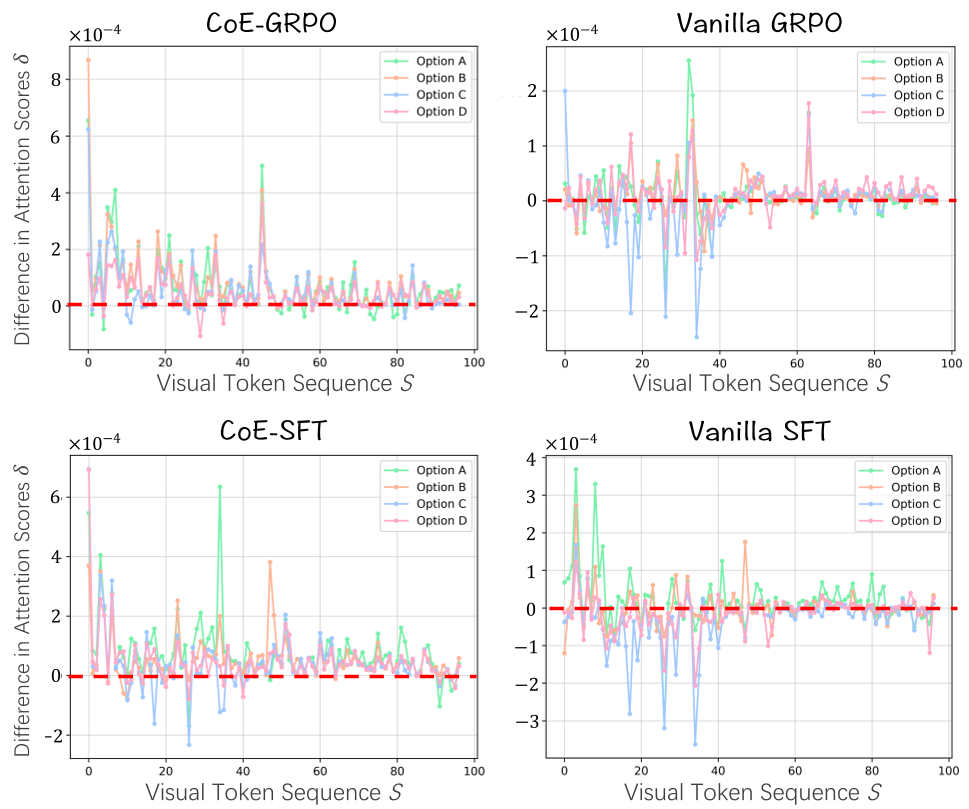 Figure 2: Attention difference analysis. Our CoE methods significantly increase the model's focus on visual tokens compared to standard SFT.
Figure 2: Attention difference analysis. Our CoE methods significantly increase the model's focus on visual tokens compared to standard SFT.
A Critical Analysis: Why This Matters
The "Chain of Events" is more than just a prompt trick; it’s an inductive bias for causality. In standard LLM training, temporal order is often lost in-context. By explicitly rewards the "temporal localization" ability (finding where an event starts and ends), the researchers have unlocked a way for MLLMs to perform "System 2" thinking for video.
Limitations
- Temporal Precision: The method relies on the model's ability to generate accurate timestamps. If the base model's localization is weak, the chain collapses.
- Representation Complexity: Currently, it is a linear chain. Real-world events are often a "Graph of Events" where multiple actors interact simultaneously.
Conclusion
Video-CoE demonstrates that the path to better video reasoning isn't just "more data" or "more parameters," but better regimes of reinforcement. By teaching models to document the past before predicting the future, we move one step closer to AI that truly understands the physical world's causal dynamics.