This survey provides a comprehensive taxonomy of video understanding by categorizing recent progress into three pillars: low-level geometry (depth, pose, flow), high-level semantics (segmentation, tracking, grounding), and unified models like VideoQA and integrated understanding-generation systems. It highlights the paradigm shift from task-specific pipelines toward unified, multimodal video foundation models.
TL;DR
Video understanding is moving beyond simple action recognition. A new comprehensive survey explores the convergence of Low-level Geometry (how the world moves), High-level Semantics (what the world means), and Unified Foundation Models (reasoning and generating). By integrating physically grounded structure with large-scale multimodal reasoning, the field is transitioning toward "World Models" capable of active prediction and long-horizon memory.
Background Positioning: The Three Pillars
In the academic coordinate system, this work acts as a critical map for the post-Transformer era. It argues that while we have mastered static image analysis, video remains a "foundational problem" because it requires reconciling 3D physical constraints with 2D semantic labels across time.
1. The Geometry Bedrock: Joint Feed-Forward Models
For years, recovering 3D structure from video required heavy optimization (Structure-from-Motion). The authors highlight a massive shift toward Joint Feed-forward Geometry Models.
Instead of solving depth, pose, and flow separately, models like VGGT and MASt3R predict these primitives in a single forward pass. This creates a "mutually consistent" geometric representation.
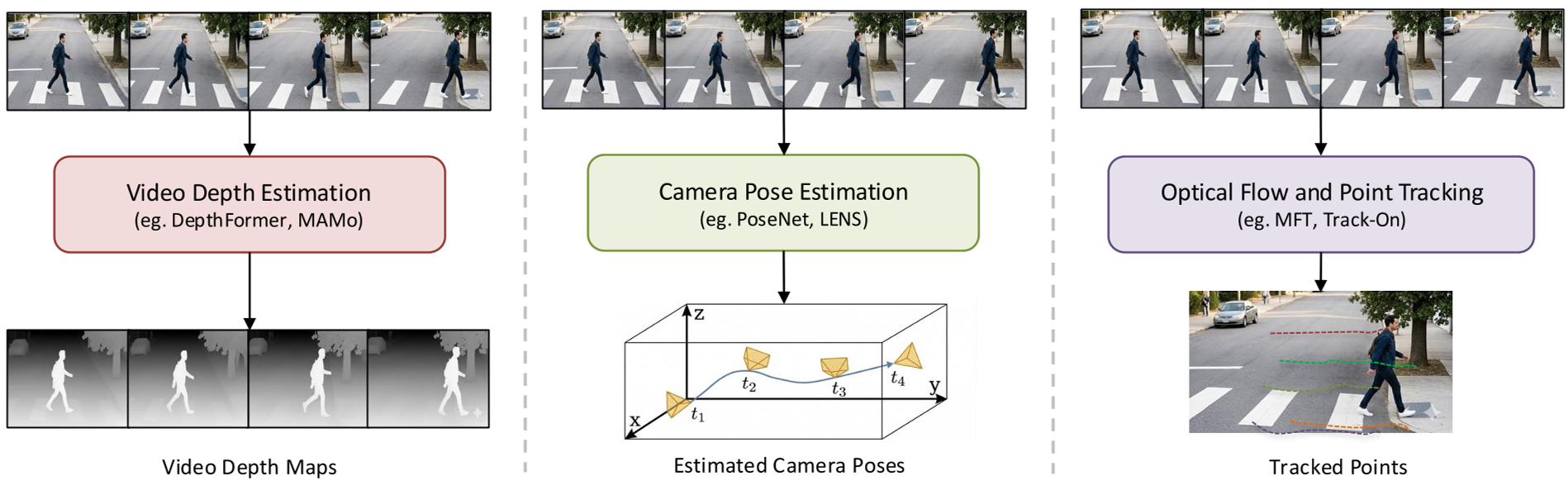 Fig 1: The synergy between depth estimation, camera pose, and point tracking.
Fig 1: The synergy between depth estimation, camera pose, and point tracking.
Key Insight: Learning shared representations across dynamic scenes allows these models to handle "in-the-wild" videos where classical geometry solvers typically fail due to motion blur or occlusions.
2. Semantics: Identity and Grounding
High-level understanding has evolved from closed-set classification to Open-Vocabulary and Multimodal Tracking.
- Video Segmentation: From VSS (Semantic) to VPS (Panoptic), the field now uses "Segment Anything" (SAM2/SAM3) paradigms to achieve zero-shot tracking via memory-centric architectures.
- Temporal Grounding: The rise of MLLMs (Multimodal Large Language Models) has turned grounding into a reasoning task. We no longer just "detect" a clip; we "reason" our way to it using Chain-of-Thought (CoT).
 Fig 2: The progression from Siamese matching to multimodal target representation.
Fig 2: The progression from Siamese matching to multimodal target representation.
3. The Unified Future: Reasoning + Generation
The most exciting frontier is the Unification of Understanding and Generation. Modern VideoQA (Quality Assurance) benchmarks like EgoSchema or Video-MME now test for "Spatial Supersensing"—the ability to maintain object permanence and causal logic over hour-long contexts.
Architectural Trends:
- Autoregressive (AR) Models: Treating video as a stream of tokens (e.g., Emu3).
- Hybrid Models: Utilizing a Transformer backbone for logic but Diffusion/Flow-matching for high-fidelity synthesis (e.g., Show-o2).
- Efficiency Gains: The introduction of Mamba/SSM blocks to handle long-video sequences with linear complexity, circumventing the quadratic cost of standard Attention.
 Table 1: Competitive landscape of Joint Feed-forward models across Depth, Pose, and 3D Reconstruction benchmarks.
Table 1: Competitive landscape of Joint Feed-forward models across Depth, Pose, and 3D Reconstruction benchmarks.
Critical Insight: Memory is the Bottleneck
The survey concludes that Memory is a first-class design principle. To reach the level of "World Models," AI must:
- Balance latency with representational fidelity.
- Move from "bag-of-features" encoding to persistent state management.
- Integrate uncertainty-aware planning, allowing agents to reason over multiple plausible futures.
Conclusion
We are moving away from isolated tasks toward holistic video agents. By bridging the gap between "how the world moves" (Geometry) and "what it means" (Semantics), unified models are paving the way for AI that doesn't just watch video—it understands the underlying reality.
Limitations: Current models still struggle with fine-grained hallucination and the massive computational cost of long-horizon temporal consistency.